HDFS
- 5월달에는 어쩌면...코로나가 끝날 것...
- 동영상은 매주 올려줄 예정
- 코딩테스트 할 예정
- 교수학습방법 10개를 들으심..
✅ HDFS 개요
- 여러가지 에코가 있음
- sql처리, 키 밸류로 처리, 파일시스템&데이터처리프레임워크로 시작했음
- 맵리듀스는 이제 많이 안씀
- 맵리듀스는 가장 베이직함
- 3번 정도 고생할 예정
- 프로그램 올려보고 돌려보고 하둡에 대해 익숙해지기
- 모델에 익숙해지기
- 스파크는 그걸 확장한 것 -> 플렉서블
- 라지 데이터 : 데이터가 생성이 되는 속도가 빠르고, 크다. 머신의 바운더리를 넘어섬, 예를 들어 저장 공간이 4테라이면 파일하나가 8테라 -> 컴퓨터 한 대에 저장 안됨
- 분할 압축 -> 4테라 단위로 쪼개서 각 드라이브에 넣는다
- 페이스북, 유튜브 -> 라지데이터 폭발적
- 엑세스하는 패턴 : 중간에 업데이트하는 성질은 거의 없음, 그냥 계속 씀
- 운영체제 수준의 파일시스템 : 관리의 단위 - 블락, 페이지 -> 크기는 ? 4kb, 업데이트가 자주 일어남, 한번도 업데이트를 안 하면 블락 사이즈를 크게 해도 되겠다. 장점?
- 64MB : 디스크같은 경우 ioc에서 읽어오는 시간이 너무 많이 걸림. 64mb로 하는 경우 시간이 빨라짐. 여러 군데 안 돌아도 됨. 연속으로 저장되어 있으면 좋다. 64mb가 연속적으로 연결되어 있을테니 빠를 것.
- 관리 오버헤드 : 4kb경우 1mb를 관리할 경우 256번 관리 해야됨
- 파일이 굉장히 커지면 머신의 바운더리를 넘어설 건데 한 파일을 나눠서 저장.
- 파일이 중간에 지워지지만 않으면 100% open이 됨
- 이제는 네트워크가 껴있음 -> 정말 자주 오류를 냄, 중간에 단전, 네트워크의 전원이 꺼질 수도 있고..
- 돌다가 심심하면 일어나는 일이 고장인데 그런 것까지 대응하는 것이 HDFS
- 컴퓨터에 저장. usb저장. 웹 브라우저에 저장. -> 이런 것처럼 HDFS도 고장나면 읽히긴 해야하니까 여러 번 저장.

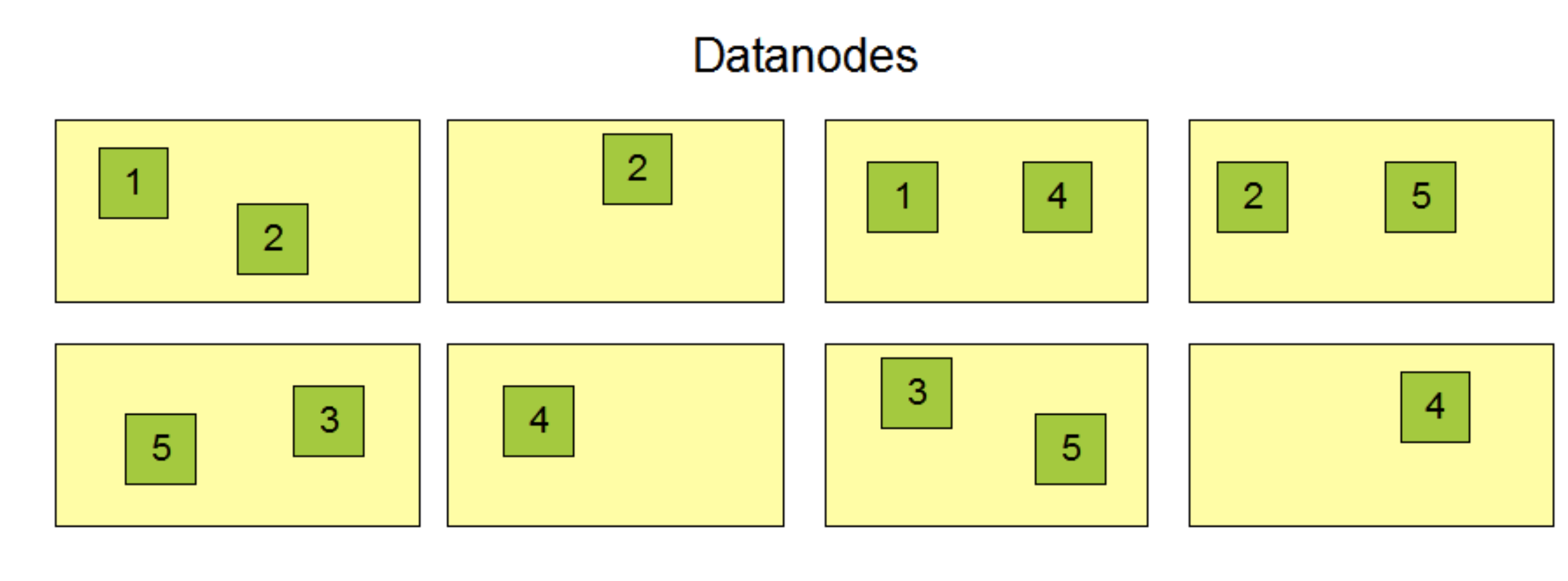
- 만약 데이터가 손실되면 다른 곳에서 가져옴
- 랙 : 서버는 누워있음. 저장을 3개 하지만 물리적으로 디자인하는 것은 좀 다름. 예를 들어 4번은 3군데 저장되어 있지만 같은 랙에 있다면 의미가 없어짐. 다른 랙에 저장되어 있어야 함. 또 다른 데이터 센터에도 저장되어야 함. 고장이 나더라도 고장의 범위를 1개만 하도록 디자인하는 것.
- 한번 쓰고 주구장창 읽기만 하더라
- 한번 수십테라짜리를 읽어서 처리를 한다던지 그런 작업이 적합함
- 실시간으로 바로바로 처리해야하는 건 적합하지 않음 -> ex) 결제
✅ HDFS 엑세스
- 파일시스템 같은 경우 운영체제를 설치하면 자동으로 설치됨
- 어플리케이션 같음
- 웹 하드 서버
- HDFS는 운영체제 수준이 아니라 어플리케이션 수준의 파일시스템임
✅ MapReduce 프레임워크
- 구글의 검색엔진에서 쓰는 알고리즘(웹 페이지의 중요도를 계산해주는 알고리즘) -> 데이터가 많이 필요함 -> 전 세계의 웹 페이지를 담아올 수 있어야 함 -> 스토리지 커야 함 -> 구글 파일 시스템 -> 계산할 때 사용하는 프레임이 맵리듀스
- 분산 처리 시스템
- 데이터의 엄청난 부하를 일으킴 -> 해결하는 핵심 아이디어 : 데이터를 가져오지 말고 코드를 데이터가 저장되어 있는 곳으로 전달하자 -> 맵리듀스의 아이디어
- 잡트래커도 과거임. 이제 안써
- 데이터가 배치되어 있는 건 누가 알까? 네임노드가 알 것(파일시스템)
- 잡트래커는 HDFS에게 물어봐 -> 랭크 파일이 어디에 있는지 물어봐 -> 가능하면 그 쪽으로 코드를 보내서 네트워크 부하를 최소화
- 코드를 움직이게 함
- 데이터는 90테라일 수도 있지만 코드는 고작해야 1mb
✅ 실습

iOS 개발자😺