
🔍 들어가기 전
REST API를 쓰다가 GrapQL이라는 언어가 나왔는데, 엄청 좋다더라,, 라는 얘기를 어렴풋이 들었다.
하지만 왜 좋지? REST API도 충분이 잘 디자인 된 구조가 아닌가? 라는 의문이 생겼고,
구체적으로 어떻게 좋고, 왜 GraphQL 이 생겼는지에 대해서 정리해보려고 한다.
먼저 REST(Representational State Transfer) API를 짚어보자
GraphQL이라는 기술이 개발된 이유를 알기 전, REST API가 어떤 방식으로 요청하고 응답받는지를 알아야한다.
아마 개발하다가 API request 시 아래와 같은 url을 많이 마주했을 것이다.
example 1
GET /api/:id
POST /api/:id
PUT /api/:id
DELETE /api/:id 위와 같이 GET, POST, PUT, DELETE 와 같은 것을 HTTP METHOD라고 한다.
http 표준 명세를 가지고 있기 때문에
GET,POST, PUT, DELETE 등 HTTP 표준 메소드와 url을 통해 API가 많은 작업을 할 수 있도록 해준다.
말 그래도 표준이기 때문에 URL을 보고 누구든
'이 url은 어떤 요청이겠구나' 라는 예상이 가야하기 때문이다.
- 회원정보를 가져오는 URI
GET /members/show/1 (x)
GET /members/1 (o)
- 회원을 추가할 때
GET /members/insert/2 (x) - GET 메서드는 리소스 생성에 맞지 않습니다.
POST /members/2 (o)
예를 들어
영화 오픈 API를 이용하여 데이터를 받아오는 테스트를 해보자.
특정 영화 상세 정보를 조회하고 싶다.
아래 오픈 api 공식 문서를 살펴보면
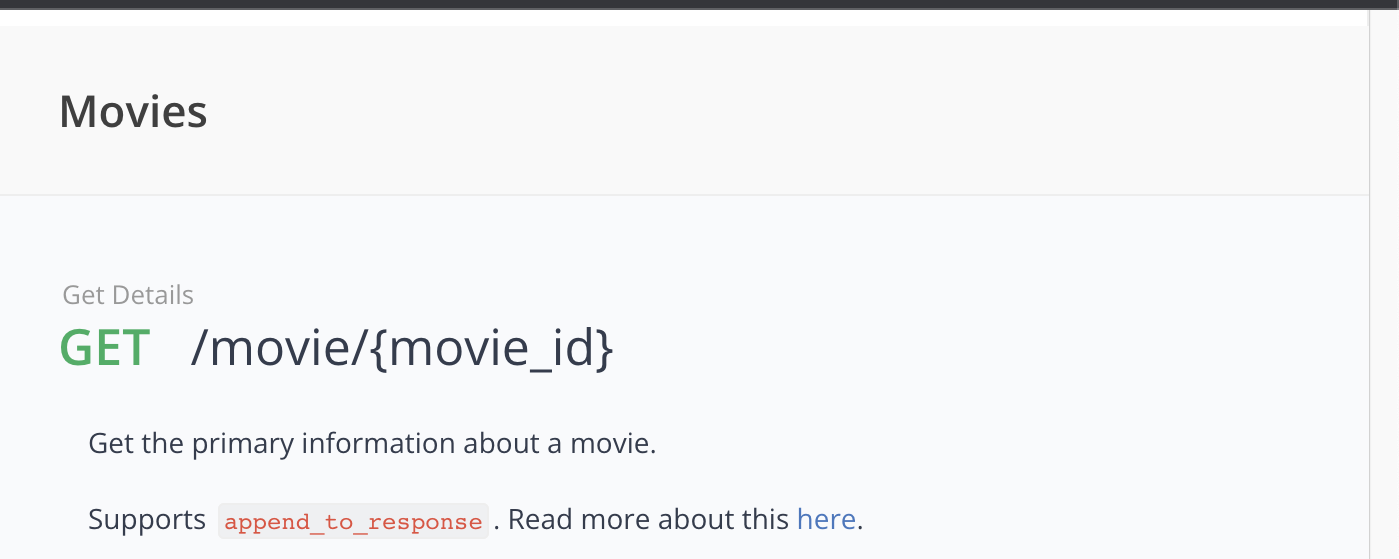
GET /movie/{movie_id}
특정 영화에 대해 조회하겠다고 얼추 예측할 수 있다.
조회해봤더니 아래와 같이 영화 상세 정보를 받아온다.
{
"adult": false,
"backdrop_path": "/pbrkL804c8yAv3zBZR4QPEafpAR.jpg",
"belongs_to_collection": null,
"budget": 165000000,
"genres": [
{
"id": 12
},
{
"id": 18
},
{
"id": 878
}
],
"homepage": "http://www.interstellarmovie.net/",
"id": 157336,
"imdb_id": "tt0816692",
"original_language": "en",
"original_title": "Interstellar",
"overview": "The adventures of a group of explorers who make use of a newly discovered wormhole to surpass the limitations on human space travel and conquer the vast distances involved in an interstellar voyage.",
"popularity": 147.721,
"poster_path": "/gEU2QniE6E77NI6lCU6MxlNBvIx.jpg",
"production_companies": [
{
"id": 923,
"logo_path": "/5UQsZrfbfG2dYJbx8DxfoTr2Bvu.png",
"name": "Legendary Pictures",
"origin_country": "US"
},
{
"id": 9996,
"logo_path": "/3tvBqYsBhxWeHlu62SIJ1el93O7.png",
"name": "Syncopy",
"origin_country": "GB"
},
{
"id": 13769,
"logo_path": null,
"name": "Lynda Obst Productions",
"origin_country": ""
}
],
"production_countries": [
{
"iso_3166_1": "GB",
"name": "United Kingdom"
},
{
"iso_3166_1": "US",
"name": "United States of America"
}
],
"release_date": "2014-11-05",
"revenue": 701729206,
"runtime": 169,
"spoken_languages": [
{
"english_name": "English",
"iso_639_1": "en",
"name": "English"
}
],
"status": "Released",
"tagline": "Mankind was born on Earth. It was never meant to die here.",
"title": "Interstellar",
"video": false,
"vote_average": 8.4,
"vote_count": 28601
}해당 영화의 제목, 이미지, 장르 등과 모든 정보를 받아올 수 있었다.
위처럼 Http methd를 보고 url의 요청을 알아보기 쉽게 해주는 것이 REST API다
즉,
무언가를 받아오고 싶으면 GET
무언가를 CREATE 하고 싶으면 POST
무언가를 UPDATE하고 싶으면 PUT
무언가를 DELETE하고 싶으면 DELETE
이렇게 잘 디자인 된 REST는 이해하기 쉽다.
때문에 많은 기업들, 서버, 많은 사람들이 REST API를 사용하고 있다.
그러면 이렇게 좋은 REST API를 두고 GraphQL을 왜 사용해야할까?
REST API는 두가지의 문제점이 있다.
먼저,over-fetching이다.
위의 영화 정보를 가져왔을 때처럼
url을 요청했더니 해당 영화에 대한 모든 정보를 빠짐없이 조회했다.
하지만, 만약에 나는 단지 영화 제목, 영화 사진 두가지 정보만 보여주고 싶다면?
그럼에도 불구하고 선택권없이 내가 필요한 것 이상의 많은 정보를 조회할 수 밖에 없다.
이렇게 내가 데이터를 쓰던 말던 너무 많은 데이터를 받아오는 것을 over-fetching이라고 한다.
어떤 점이 안 좋을까? 그냥 데이터 다 받아오고 쓰고 싶은 것만 쓰면 안되나?
라고 생각할 수도 있다.
하지만 필요 이상의 정보를 가져오는 것은 내 database 즉 backend가 훨씬 많은 일을 해야한다는 뜻이다.
왜냐하면 말 그대로 database는 모든 정보를 주기 위해 리소스를 투여하지만 정작 내가 필요한 정보는 그 중 몇가지뿐이기 때문이다.
또한, backend에서 front로 보내야할 데이터가 많기 때문에 데이터 전송 속도 또한 느려질 수 있다.
under-fetching
두번째 문제점은 위와 반대로 우리가 필요한 정보보다 덜 받는 것이다.
위에서 조회한 영화 상세 정보에서 이 영화의 장르를 사용하고 싶을 수 있다.
장르명이 뭐지? 코미디? 로맨스? 어떤건지 체크하려고 봤더니
"genres": [
{
"id": 12
},
{
"id": 18
},
{
"id": 878
}장르명이 나와있지않고 장르에 대한 id값으로 장르명을 또 조회해야하는 상황이 되었다.
그럼 영화정보 + 장르명을 알기 위해서는
요청 1. 영화 상세 정보
요청 2. 장르 id값과 일치하는 장르명
이렇게 두가지 요청이 이루어져야한다.
왜?
REST API가 내가 원하는 정보보다 적게 정보를 주었기 때문이다.
이렇게 된다면 영화 상세 정보 화면을 위해 두번의 request가 이루어진다.
즉, 이것은 로딩 시간이 느려질 가능성과 두개의 요청 중 한개의 요청이 실패할 가능성도 생길 수 있다는 말이다.
이러한 상황을 under-fetching이라고 한다.
GrapQL를 써야하는 이유
그러면 GrapQL은 어떤 점에서 REST API를 보완해주는 것일까?
왜 이렇게 사람들이 좋아할까?
이 기술이 해결할 수 있는 문제가 무엇일까?
GraphQL 정의
GraphQL은 API를 위한 쿼리언어이다.
SQL이랑 비슷한 개념일까?
이 둘은 목적과 사용하는 위치가 다르다.
sql은 우리가 알고 있는 것 처럼 데이터베이스 시스템에 저장된 데이터를 효율적으로 가져오는 것이 목적이다.
반면에 GraphQL은 웹 클라이언트가 데이터를 서버로 부터 효율적으로 가져오는 것이 목적이다.
즉 sql의 문장(statement)은 주로 백앤드 시스템에서 작성하고 호출 하고
gql의 문장은 주로 클라이언트 시스템에서 작성하고 호출한다.
over-fething 이슈를 해결한다.
GraphQL의 중요한 역할 중 한가지인데,
정보 중 특정 부분만 달라고 요청할 수 없는 REST API와는 달리 url로 데이터를 즉시 받지 않고, 필요한 데이터만 요청할 수 있다.
위 예시 들었던 영화에 대해 둘이 비교 시 이렇게 요청한다.
REST API
: 영화에 대한 정보를 줘!
GraphQL
: 영화에 대한 정보 중 제목, 영화 포스터만 줘!
이것이 바로 공식 문서에 나와있는 GrapQL의 장점이다.
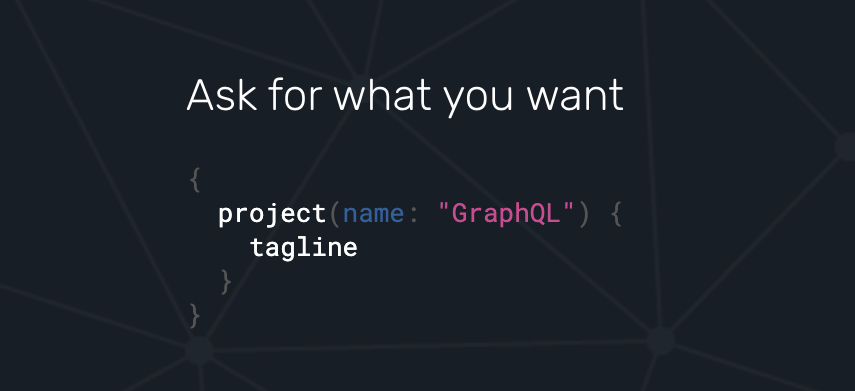
//request
{
hero {
name
height
}
}
//Response
{
"hero"{
"name" : "조예진",
"height": "161cm",
}
}under-fetching
위 영화 상세 정보를 받아오는데 아래와 같이 장르 id 값만 있고 장르명이 없다.
‘’’javascript
"genres": [
{
"id": 12
},
{
"id": 18
},
{
"id": 878
}
‘’’
그래서 사용자는 해당 장르 id값과 일치하는 장르명을 얻기 위해 또 한번의 request를 해야한다.
결국 영화 상세 정보를 가져오는 것과 장르명을 가져오는 api request가 두번 이루어지기 때문에 비효율적이다.
GrapQL은 우리가 필요한 정보를 한번에 받을 수 있게 해준다.
다시 말해 같은 화면에 두번의 요청을 할 필요가 없다.
이것이 바로 GrapQL 공식 문서에 나와있는 GrapQL의 특징 중 ‘ Get many resources in a single request’
이다.
그러면 GraphQL의 단점은 무엇일까?
먼저, 요청에 대한 필터링이 어렵다.
GraphQL은 클라이언트가 필요한 데이터를 스스로 결정하여 요청하기 때문에
GraphQL의 다양한 요청 형태에서 잘못된 요청을 필터링하기가 까다롭다.
두번째, 각 요청에 대한 Http 캐싱 전략을 사용할 수 없다.
여러개의 요청을 단 하나의 요청으로 처리하기 때문에
각각의 url로 처리하는 rest api와 달리
여러개의 요청도 하나의 요청으로 할 시에는 각 요청에 대한 캐싱 전략을 적용하기 힘들다
GraphQL 사용법
- grapQL을 테스트 해볼 수 있는 틀이다.
query root click시
아래와 같이 내가 받을 수 있는 정보에 대해 나온다.
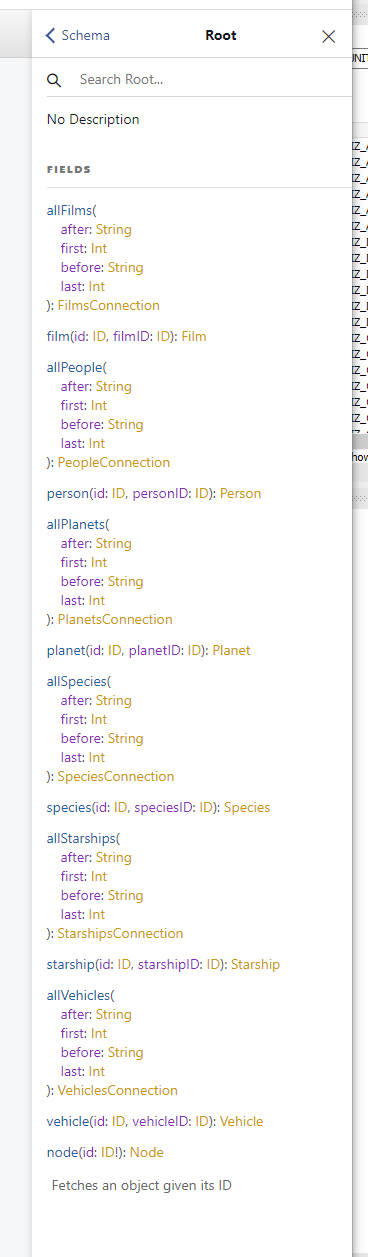
내가 받을 수 있다는 것이 무슨 의미일까?
이말은 즉 요청 시 API가 나한테 주는 data인 것이다.
자 , 이제 graphQL을 이용하여 데이터를 요청해보자
아래와 같이 allFilms에 대한 정보를 받아오려고 한다.
그런데 어떤 데이터를 어떻게 요청해야할까?!
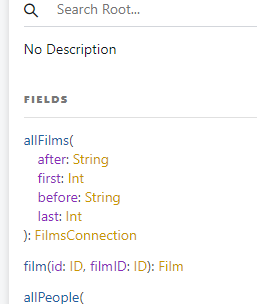
위에 보이는 FilmsConnection을 클릭해보면 우리가 어떤 데이터를 어떤식으로 요청해야할지 알수 있다.
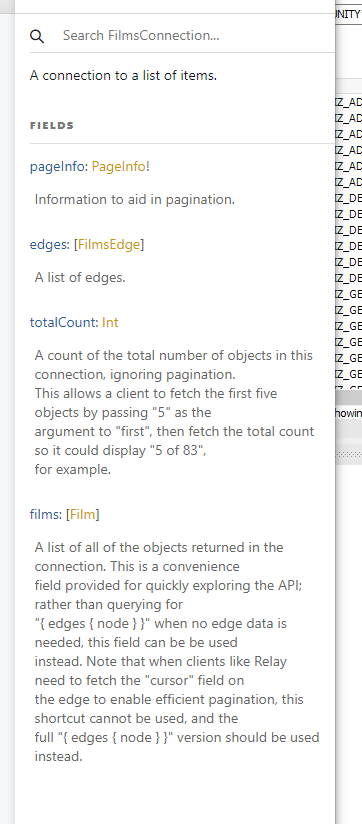
클릭하면, 아래와 같은 정보가 나온다.
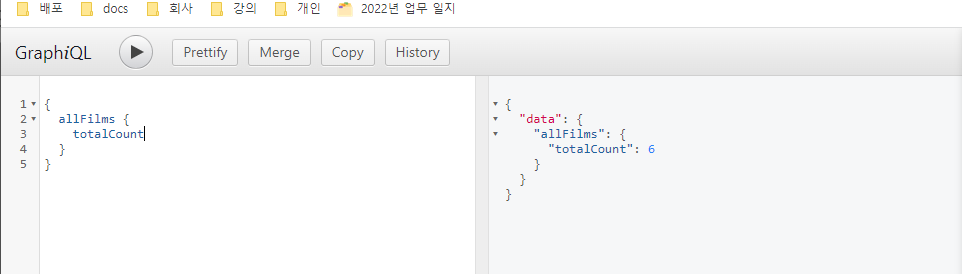
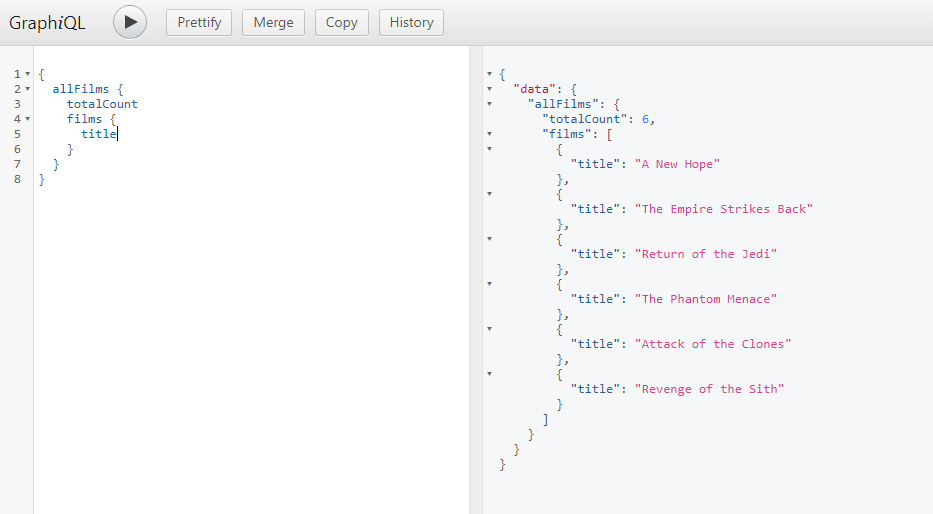
totalCount에 대한 데이터를 쓰고 재생 또는 Ctrl+enter를 검색하니 오른쪽 결과가 return 되었다.
위의 방식이 over-fetching을 해결한 GraphQL의 예시이다.
위와 같이 graphQL은 우리가 원하는 데이터 그 이상, 그 이하도 주지 않고 딱 원하는 정보만 return했다.
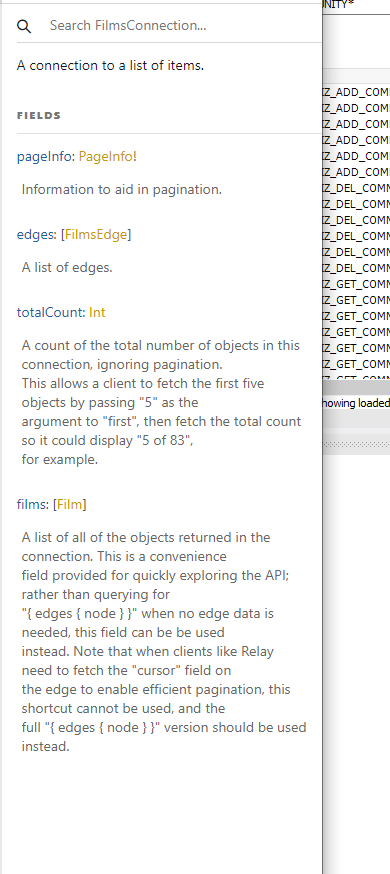
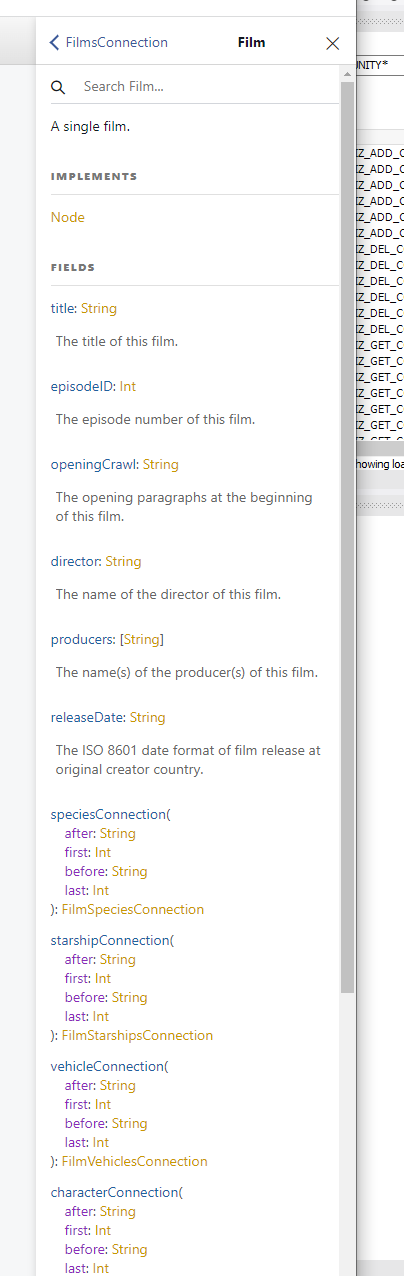
FILM을 클릭하면 위와 같이 해당 FILM이 가질 수 있는 정보가 표시된다.
나는 그 중 title 정보만 받아보고 싶어 아래와 같이 데이터를 요청했다.
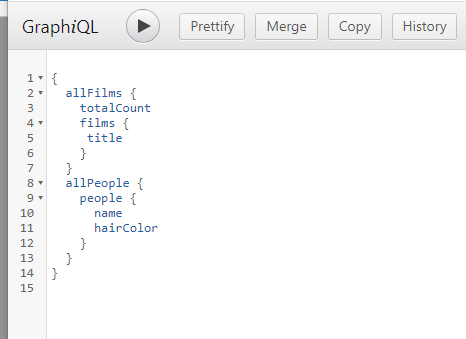
이번엔 under-fetching 문제를 해결한 GraphQL의 예시를 살펴보자
나는 아래와 같이 allFilms, allPeople을 한번의 요청(한번의 엔터로) 데이터를 가져와볼 것이다.
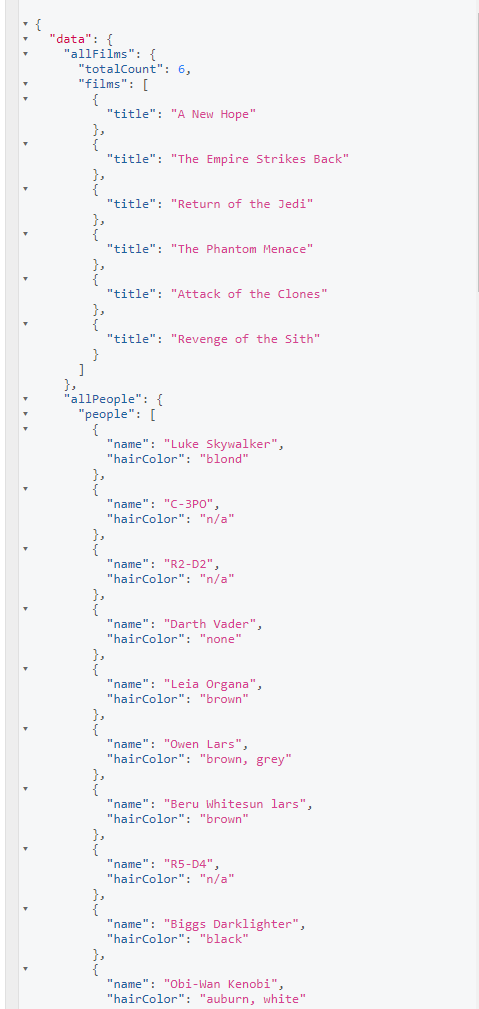
위와 같이 한번의 요청으로 두가지의 정보를 받아왔다 이것이 바로 under-fetching의 해결책이다.
REST API에서 처럼 다른 정보를 가져오기 위해 API Request를 각각 두번 보내서 받아오는 것이 아니라 한번에 정보를 받아올 수 있다.
이게 만약 API였다면
/api/films 1번
/api/peple 2번
총 2번의 요청을 받아와야 했을 것이다.
다음 시간
- grapQL API 만들어보기
📎 참고자료
