
📝 들어가기 전..
자바스크립트로 업무를 하다가
감사하게도 파이썬으로 데이터를 정제하는 업무를 맡게 되었다.
업무는 웹 스크래핑한 데이터를 가지고
다양한 형태의 데이터들을 정제해서 DB에 직접 넣고 자동화하는 업무이다.
파이썬을 처음 하는 거라 기초부터 관련 라이브러리를 공부하려고 한다.
웹 크롤링과 웹 스크래핑 두가지가 있던데,
웹 크롤링은 많이 들어봤지만, 웹 스크래핑은 이번에 크롤링을 공부하면서 처음 들어봤다.
두가지의 차이는 무엇일까?
웹 크롤링 vs 웹 스크래핑 차이
웹 크롤링 : 모든 데이터 다 긁어오는 것이고,
웹 스크래핑 : 원하는 데이터만 긁어오는 것이다.
웹 스크래핑, 데이터 정제할 때 쓰는 라이브러리가 몇 개있는데,
우선 웹 스크래핑 관련된 라이브러리를 먼저 공부해 볼 것 이다.
웹 스크래핑 start!
📌 필요한 라이브러리
- requests: 스크래핑할 웹 사이트 요청하기 위한 패키지이다.
아래와 같이 조회할 url을requests.get메소드를 이용하여 요청할 수 있다.
import requests
url = "https://comic.naver.com/webtoon/list?titleId=675554"
res = requests.get(url)- BeautifulSoup :
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/list?titleId=675554"
res = requests.get(url)
res.raise_for_status() # 혹시나 문제가 있으면 프로그래밍이 바로 종료 되도록 하는 함수
soup = BeautifulSoup(res.text, "lxml")
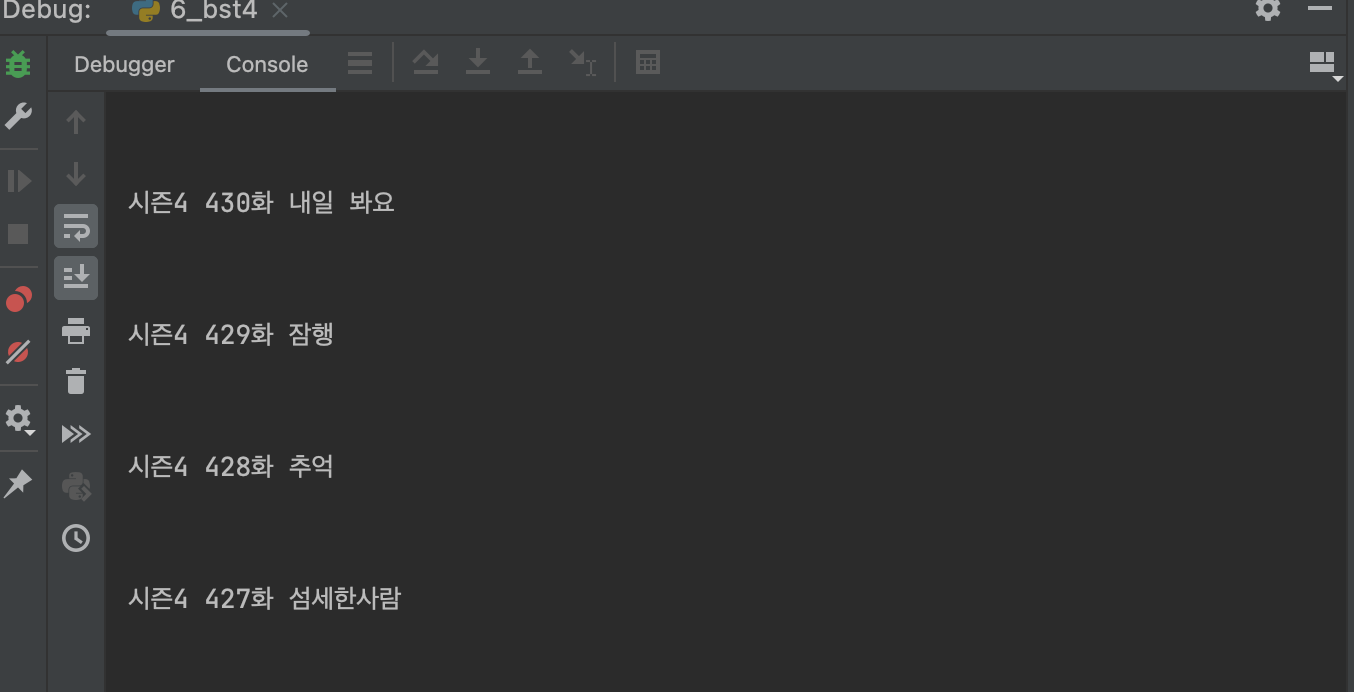
cartoons = soup.find_all("td", attrs={"class": "title"})
for cartoon in cartoons:
print(cartoon.get_text())아래와 같이 출력된다.

블로그 이전 중 -> https://devjooj.tistory.com/