[Advanced C++] 35. Delegate constructor, Temporary class object & return by value
Advanced C++

1. Delegate constructor
생성자 위임
DRY(Don't Repeat Yourself) 원칙을 지키기 위해 최대한 코드의 중복은 피하는 것이 좋다
반복되는 코드를 함수로 대체하여 코드 유지보수성을 향상시키고 중복 코드를 줄이는 것 처럼 생성자도 마찬가지다
생성자의 코드가 매우 유사하거나 동일한 경우는 생각보다 많기 때문에 가능한 중복을 제거하는게 좋다
class Knight
{
public:
Knight(int InHp, int InMp)
: hp(InHp)
, mp(InMp)
{
std::cout << "Knight() called" << std::endl;
}
Knight(int InHp, int InMp, int InExp)
: hp(InHp)
, mp(InMp)
, exp(InExp)
{
std::cout << "Knight() called" << std::endl;
}
private:
int hp{};
int mp{};
int exp{};
};위의 예제 코드를 보면 Knight 생성자 2개가 거의 동일한 명령을 수행한다 (물론 생성자에서 출력하는건 좋지 않은 방식임, 단순 정리용으로 작성함)
생성자에서는 다른 멤버 함수를 호출할 수 있다, 따라서 함수를 이용하여 코드 중복을 방지하는게 좋다
class Knight
{
public:
Knight(int InHp, int InMp)
: hp(InHp)
, mp(InMp)
{
Print();
}
Knight(int InHp, int InMp, int InExp)
: hp(InHp)
, mp(InMp)
, exp(InExp)
{
Print();
}
void Print()
{
std::cout << "Knight() called" << std::endl;
}
private:
int hp{};
int mp{};
int exp{};
};Print()라는 함수를 만들어 각 생성자에 호출만 해주는 방식으로 코드 중복을 방지하였다
이러한 방법은 물론 아예 동일한 코드를 중복하여 사용하는 방식보다는 좋지만 새로운 함수가 필요하고 초기화는 중복 코드 해결을 하지 못했다는 단점이 존재한다
그렇다면 생성자 안에서 다른 생성자를 호출하면 어떻게 될까?
class Knight
{
public:
Knight(int InHp, int InMp)
: hp(InHp)
, mp(InMp)
{
//std::cout << hp << mp << exp << std::endl;
}
Knight(int InHp, int InMp, int InExp)
: exp(InExp)
{
Knight(InHp, InMp);
}
int GetHp() const { return hp; }
private:
int hp{};
int mp{};
int exp{};
};
int main()
{
Knight K1{100, 200, 300};
std::cout << K1.GetHp() << std::endl;
return 0;
}결과는 100이 나올 것 같지만 전혀 그렇지 않고 0이 나오게 된다, 객체의 초기화는 생성자 멤버 초기화 리스트에서 이미 끝났고 Knight(InHp, InMp)는 Knight 클래스 타입 임시객체를 생성하여 그 임시객체를 초기화 하게 되었기 때문에 k1객체는 hp, mp는 초기화되지 않고 exp만 초기화가 된 것이다
결론적으로 생성자는 다른 함수의 본문에서 직접 호출되면 안된다, 임시 객체를 생성하여 그 임시객체를 초기화 하게 되고 컴파일 에러를 발생시킨다
이렇게 함수를 사용하는것도, 생성자에서 다른 생성자에서 호출하는것도 좋지 않은 방식이다, 이럴때 생성자 위임을 사용한다 (constructor chaining이라고도 함)
쉽게 말해서 한 생성자가 다른 생성자에게 초기화를 위임시키는 것이다
멤버 초기화 리스트에서 원하는 생성자를 호출하면 된다
class Knight
{
public:
Knight(int InHp, int InMp)
: Knight(100, 200, 300)
{
//hp, mp, exp는 Knight(int, int, int) 생성자에 의해 초기화 됨
}
Knight(int InHp, int InMp, int InExp)
: hp{ InHp }, mp{ InMp }, exp{ InExp }
{
}
int GetHp() const { return hp; }
private:
int hp{};
int mp{};
int exp{};
};
int main()
{
Knight K1{100, 200, 300};
std::cout << K1.GetHp() << std::endl;
return 0;
}이때 위임 받은 생성자는 따로 자체적으로 멤버 초기화가 불가능하다
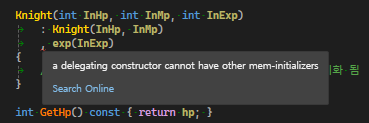
Knight(int, int, int)는 Knight(int, int)생성자를 위임 받았는데 exp를 자체적으로 초기화하려고 해서 컴파일 에러가 발생함
일반적으로 매개변수가 많은 생성자를 적은 매개변수의 생성자에 위임해서 사용한다
이런 방식으로 생성자 위임을 통해 중복 생성자를 줄일 수 있다 (객체를 생성하면 생성자 2개가 호출됨)
또한 기본값을 사용하여 생성자의 갯수를 줄일 수 있다
Knight(int InHp, int InMp, int InExp = 0);
Knight K1{ 100, 200 };
Knight K2{ 100, 200, 300 };이렇게 인자가 2개, 3개인 생성자를 따로따로 만들지 않아도 기본값을 주어 같이 사용할 수 있게 만들어 중복을 줄일 수 있다
좋은 습관 중 하나는 초기화값이 반드시 제공되어야 하는 매개변수를 먼저 정의하고 그 다음 선택적으로 초기화를 해도 되는 매개변수를 정의하는것이다 (기본값이 있는 매개변수는 항상 최우측에 존재해야 하기 때문)
2. Temporary class object
임시 클래스 객체
함수로 먼저 예시를 들어보자
int add(int x, int y)
{
int sum{ x + y };
return sum;
}
int add(int x, int y)
{
return x + y;
}
add(100, 200);위의 함수에서는 sum이라는 변수를 만들고 값을 할당한 뒤 return하고 두번째 함수는 연산 결과를 바로 return하는 방식의 함수들이다
변수가 한번만 사용되는 경우 굳이 변수를 정의할 필요가 없다 (오히려 함수를 더 복잡하게 만든다)
물론 함수 인자에서도 동일하다
int sum{ 3 + 5 };
Print(sum);
Print(3 + 5);둘 다 동일한 함수지만 불필요한 sum이라는 변수를 정의하지 않고 literal 값 자체를 넘기는것이 더 깔끔한 코드를 유지할 수 있다
(변수가 단 한번만 사용된다면)
이렇게 사용하면 3 + 5는 표현식이기 때문에 해당 line에서만 사용된다는걸 쉽게 알 수 있다, 변수를 사용하면 해당 변수가 또 다른곳에서 사용하는지 확인해봐야 한다
이런 방식은 rvalue 표현식이 허용되는 경우에만 가능하다 (&와 같은 lvalue 표현식이 필요한 경우에는 객체가 있어야 하기 때문에 사용이 불가능하다, 단 const&인 경우에는 임시객체 rvalue 사용이 가능하다 (수정하지 않기 때문에))
(인자가 const&타입이고 임시객체를 전달하게 되면 심지어 참조가 유효한 동안 임시객체의 수명을 연장시킨다)
void Print(int& InValue); //lvalue를 인자로 받는 함수
int sum{ 3 + 5 };
Print(sum); //ok (lvalue)
Print(3 + 5); //error (rvalue)
void Print(const int& InValue);
Print(3 + 5); //ok, const&이기 때문에 rvalue를 받을 수 있음이러한 규칙은 클래스 타입(클래스, 구조체)에서도 동일하게 적용된다
class SumClass
{
public:
SumClass(int a, int b)
: alpha{ a }, beta{ b }
{
}
private:
int alpha{};
int beta{};
};
void Print(SumClass InSC)
{
std::cout << InSC.alpha << InSC.beta << '\n';
}
int main()
{
SumClass sc{ 100, 200 };
Print(sc);
}SumClass 클래스 타입 객체 sc를 정의하고 Print()의 인자로 넘기는 방식이다, 이때 sc는 단 한번만 사용되고 Print()는 rvalue를 허용하기 때문에 위와 같이 SumClass타입의 이름있는 변수를 넘길 필요 없고 이름없는 임시객체를 넘기면 된다
Print(SumClass{ 100, 200 }); //SumClass타입 임시객체를 생성 후 전달, 해당 line이 끝나면 임시 객체는 소멸
Print({ 100, 200 }); //암시적으로 SumClass타입 객체로 변환이 된다리스트 초기화를 통해 임시객체 생성이 가능하고 직접 초기화를 통해서도 임시객체 생성이 가능하다 (복사 초기화를 사용한 임시 객체 생성 구문은 없음)
Foo(10, 20); //10, 20으로 초기화 된 임시 Foo 객체가 생성{ }초기화와 축소 변환 방지 기능이 없다는 것 외에는 동일한 결과를 생성한다
하지만 직접초기화 ()를 사용한 임시 객체 생성은 혼란을 일으킬 수 있다
Foo();우선 함수 문법과 비슷한 문법으로 인한 혼란이 생긴다
Foo bar{}; //Foo타입 bar변수를 정의하고 값을 초기화
Foo bar(); //매개변수가 없고 반환형이 Foo인 함수 선언이 되어버림또한
Foo(1); //literal 1로 초기화 된 임시객체 Foo를 return (Foo{1};과 유사함)
Foo(bar); //Foo타입의 변수 bar를 정의한다 (위의 내용과 일치하지 않음), Foo bar; 와 유사함이러한 혼란이 생길 수 있다
그렇다면 왜 Foo(bar)는 Foo bar처럼 변수 선언으로 작동하는가?
()의 가장 흔한 용도는 그룹화이다 (수학에서 ()를 이용하여 연산의 우선순위를 높이는것과 같음)
선언 구문은 ()기반 그룹화를 허용하기 때문에 Foo(bar)는 Foo타입의 bar 변수 정의로 해석되는것이다
(()를 그룹화로 인식하여 Foo bar로 인식함)
더욱 헷갈리는 예제를 이해해보자
Foo* bar(); //Foo*타입 반환형을 가진 bar() 함수 선언
Foo (*bar)(); //()로 *와 bar를 그룹화한다, 매개변수가 없고 Foo타입을 반환하는 함수의 주소를 담고있는 bar이름의 함수 포인터를 정의함
(Foo *) bar(); //Foo* bar()와 동일해보이지만 bar()를 호출하고 C-style casting으로 Foo*로 캐스팅한 구문이 된다임시객체와 return by value
함수가 값 타입으로 반환할 때 반환되는 객체는 임시객체이다
// 이름 있는 변수를 생성하고 반환
IntPair ret1() {
IntPair p { 3, 4 };
return p; // 임시 객체가 생성되고 p를 사용하여 초기화 후 return
}
// 사례 2: 임시 IntPair를 생성하고 반환
IntPair ret2() {
return IntPair { 5, 6 }; // 임시 객체가 생성되고 rvalue를 사용하여 초기화 한 후 return
}
// 사례 3: { 7, 8 }을 IntPair로 암시적으로 변환하고 반환
IntPair ret3() {
return { 7, 8 }; // 임시 객체가 생성되고 rvalue를 암시적으로 변환한 후 초기화하여 return
}
void Print(IntPair InIntPair)
{
}
Print(ret1());
Print(ret2());
Print(ret3());이때 반환되는 임시객체는 복사된 후 return된다 (최신 컴파일러에서는 복사 생략 copy elision 최적화로 효율적으로 처리된다)
만약 ret1()을 it라는 변수에 넣는다고 가정하고 복사/이동 생략이 있으면 p변수도 메모리 공간에 할당되지 않고 caller인 it한테 메모리 공간을 할당받은후 바로 생성된다
복사/이동 생략이 없다면 p변수 메모리 공간이 할당되고 이 값과 동일한 임시객체 사본을 만든다 이때 값이 복사/이동 되고 return된 값을 it 변수에 넣을때 또 이동/복사가 발생한다
임시 클래스타입 객체는 rvalue이다, 이렇게 return된 임시객체를 사용하기 위해서는 rvalue 표현식이 허용되는 곳에서만 사용이 가능하다
임시 객체는 정의 지점에서 생성되고 표현식의 끝에서 소멸한다
임시 객체는 이름이 없고, 메모리 주소를 얻을 수 없으며 표현식의 일부로 잠시 존재했다가 사라진다
ex) literal value, 임시 객체, 산술 연산의 결과 등
만약 타입이 맞지 않는다면 명시적으로 casting하여 임시객체 생성도 가능하다
void Foo(const std::string &InString);
std::string_view sv{ "Kelvin" };
Foo(sv); //error, std::string_view는 std::string으로 암시적 변환되지 않음
Foo(static_cast<std::string>(sv)); //string_view타입을 std::string으로 명시적 캐스팅 하여 std::string타입 임시객체를 생성
Foo(std::string{ sv }); //리스트 초기화로 임시 객체 생성 (명시적 생성이므로 변환이 허용됨)
Foo(std::string(sv)); //직접 초기화로 임시 객체 생성 (사용하지 말 것)기본 타입으로 변환할 때는 static_cast를 권장하고, 클래스 타입으로 변환할 때는 리스트 초기화된 임시 객체를 생성하는 방식을 권장한다
데이터 손실을 감수하고 축소 변환을 수행하는 경우나 아주 명확하게 다른 타입으로의 캐스팅이 필요한 경우에는 static_cast를 사용하는것도 괜찮다
리스트 초기화를 사용하는 경우는 데이터 손실 방지(축소 변환 방지), 생성자에 여러 인자를 전달하면서 객체를 만들어야 할 때 사용한다 (static_cast<>()로는 생성자에 인자를 넘길 수 없음)
