[Advanced C++] 45. std::array, const & constexpr std::array, length & indexing, std::get<>(), std::array passing & returning, 클래스 타입 element의 std::array
Advanced C++

1. std::array
std::array
컨테이너란 이름 없는 객체(element)들을 저장하는 공간을 제공한다
배열은 element들을 메모리 상에 연속적으로 할당, [ ]를 통해 특정 element에 빠르고 직접적으로 접근할 수 있다
C++ 에서는 대표적으로 std::vector, std::array, C-style 배열 이렇게 3가지의 배열 타입이 존재한다
배열은 고정 크기 배열, 동적 배열 두 가지로 나눌 수 있는데 고정 크기 배열은 배열의 size가 인스턴스화 시점에 정해져있어야 하고 변경될 수 없다, 동적 배열은 런타임에 size를 조절할 수 있다
따라서 std::vector는 동적 배열이다
정리한바에 따르면 무조건 동적 배열이 고정 크기 배열보다 좋을 것 같은데 왜 모든것에 동적 배열을 사용하지는 않는걸까? 라는 의문이 들 수 있다
동적 배열은 강력하지만 단점도 존재하기 때문이다
std::vector는 고정 크기 배열보다 성능이 살짝 떨어진다 (물론 왠만하면 느끼지 못할것 (아주 많은 reallocation이 발생하지 않는한)
또한 std::vector는 아주 제한적인 상황에서만 constexpr을 지원한다
modern C++에서는 constexpr의 중요도가 상당히 높다고 생각한다, 컴파일러에 의해 더 높은 수준으로 최적화가 가능하다
따라서 constexpr 배열이 필요하다면 std::array를 사용하는걸 권장한다
std::array는 array헤더에 존재한다
#include <array>
int main()
{
std::array<int, 5> arr{ 1, 2, 3, 4, 5 };
return 0;
}std::array 선언에는 2개의 템플릿 인자가 존재한다, 하나는 배열 element의 타입을 정하는 타입 템플릿 인자, 나머지는 배열의 size를 정하는 정수형 비타입 템플릿 인자이다
std::vector는 생성자 인자로 size를 받는다
std::vector<int> vec(5);std::array의 size는 std::vector와 다르게 반드시 상수 표현식이어야 한다, 따라서 const, constexpr변수나 unscoped enumerator값을 사용한다 (macro값도 가능하지만 권장하지 않는다)
std::array<int, 5> arr{ 1, 2, 3, 4, 5 }; //상수 5
constexpr int size{ 10 };
std::array<int, size> arr1{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; //constexpr size
enum foo
{
a,
b,
c,
d,
max
};
std::array<int, max> arr2{ 1, 2, 3, 4 }; //enum size
#define SIZE 5
std::array<int, SIZE> arr3{ 1, 2, 3, 4, 5 }; //macro size (이렇게는 사용하지 말 것)std::array의 size는 컴파일 시점에 결정되어야 한다, 따라서 컴파일 타임에 값이 정해져 있는 상수 표현식만 사용이 가능한 것이다
void foo(const int size)
{
std::array<int, size> arr{}; //compile error, 매개변수 const int size는 런타임 상수임
}
int size{ 10 };
std::array<int, size> arr1{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; //compile errorstd::array는 size가 0이 될 수 있다, 이때 operator[ ]로 element에 접근하려고 하면 정의되지 않은 동작이 발생할 수 있기 때문에 주의해야 한다
따라서 배열 사용전에 empty()를 이용하여 길이가 0인지 아닌지 체크해보는게 좋다
std::array는 집합체(aggregate)이다, 따라서 aggregate initialization이 가능하다
std::array<int, 5> arr{ 1, 2, 3, 4, 5 }; //aggregate initialization만약 초기화 없이 std::array를 선언한다면 초기화 되지 않아 쓰레기 값이 들어간다, { }로 값 초기화를 해주는게 좋다
std::array<int, 5> arr;
std::array<int, 5> arr{}; //0으로 element 전부 값 초기화만약 std::array의 size보다 더 많은 element가 { }를 통해 초기화 된다면 에러가 발생한다
더 적은 element가 { }를 통해 초기화 된다면 나머지는 0으로 자동 값 초기화 된다
const std::array
std::array는 const가 될 수 있다
const std::array<int, 5> arr{ 1, 2, 3, 4, 5 };
arr[2] = 100; //const이기 때문에 error!std::array의 모든 element가 const로 취급된다
또한 constexpr도 가능하다 (이것이 std::array를 사용하는 핵심 이유다)
std::array는 컴파일 시점에 모든 element값이 결정될 수 있기 때문에 다른 constexpr 표현식에도 사용이 가능하다, 성능과 코드 안정성이 향상될 수 있다
constexpr std::array<int, 5> arr{ 1, 2, 3, 4, 5 };std::vector와 마찬가지로 C++17의 CTAD를 이용하여 초기화 값으로 std::array의 타입과 갯수를 추론할 수 있다
constexpr std::array arr{ 1, 2, 3, 4, 5 };단 CTAD는 템플릿 인자의 부분적 생략은 지원하지 않기 때문에 둘 중 하나만 생략하는건 불가능하다
constexpr std::array<int> arr{ 1, 2, 3, 4, 5 }; //인자가 부족함, error하지만 C++20부터는 std::to_array 헬퍼 함수를 사용하여 std::array의 size 생략이 가능하다
constexpr auto arr2{ std::to_array<int, 5>({ 1, 2, 3, 4, 5 }) };
constexpr auto arr2{ std::to_array<int>({ 1, 2, 3, 4, 5 }) };
constexpr auto arr2{ std::to_array({ 1, 2, 3, 4, 5 }) };하지만 std::to_array는 임시 std::array 객체를 생성하고 복사 초기화 하기 때문에 성능상 불리하다, 이는 초기값으로부터 타입을 효과적으로 결정할 수 없을때만 사용하고 배열이 반복되어 생성되는 케이스에서는 사용하지 않는것이 좋다
예를들면 다음과 같다
constexpr auto arr2{ std::to_array<short>({ 1, 2, 3, 4, 5 }) };short 타입을 결정할 방법이 없기 때문에 사용한 케이스다 (literal은 int로 간주되기 때문에, CTAD는 int로 추론한다)
std::vector와 마찬가지로 operator[ ]를 사용하여 element에 접근이 가능하다
constexpr std::array<int, 5> arr{ 1, 2, 3, 4, 5 };
std::cout << arr[0] << std::endl; //1앞서 정리한대로 [ ]는 bound check를 하지 않기 때문에 invalid한 index로 접근 시 크래시가 발생할 수 있으며 잘못된 값에 데이터 읽기/쓰기가 발생할 수 있다
std::array size & indexing
std::array또한 std::vector와 같이 STL 컨테이너 클래스 이기 때문에 index와 size를 unsigned 값으로 사용한다
부호 변환은 narrowing 변환이지만 narrowing 변환이 일어나지 않는 constexpr일때는 예외이다
std::array의 size는 std::vector와 같이 std::size_t 타입을 가진다
//array 템플릿 구조체
template<typename T, std::size_t N>
struct array;따라서 std::array를 정의할 때 size가 std::size_t 타입이거나 std::size_t 타입으로 변환이 가능해야 한다
std::array의 size는 반드시 상수이기 때문에 (constexpr) 부호 변환 시 문제가 되지 않는다 (컴파일러가 컴파일 타임에 정수값을 std::size_t로 변환하고 narrowing 변환으로 간주하지 않음)
std::vector와 마찬가지로 std::array는 size_type 이라는 typedef 멤버를 정의한다, 이는 곧 std::size_t의 별칭이다
std::array의 size를 정의하는 비타입 템플릿 매개변수는 size_type대신 std::size_t가 명시되어 있다, 유일하게 size_type대신 std::size_t를 사용하고 다른곳에서는 size_type을 사용한다 (std::array는 항상 size_type이 std::size_t와 동일하기 때문)
그렇다면 std::array의 size는 어떻게 얻을까?
constexpr std::array<int, 5> arr{ 1, 2, 3, 4, 5 };
std::cout << arr.size() << std::endl; //5size()는 size를 unsigned size_type으로 return한다
std::string, std::string_view는 length()와 size()를 둘 다 가지고 있다 하지만 std::array 및 대부분의 컨테이너 타입은 size()만 가진다
또한 std::size() 비멤버함수를 호출할 수 있다 (내부적으로는 단순히 size() 멤버함수를 호출하는 형태)
constexpr std::array<int, 5> arr{ 1, 2, 3, 4, 5 };
std::cout << std::size(arr) << std::endl;C++20에서는 std::ssize() 비멤버 함수 사용이 가능하다, 이는 signed 정수 타입인 std::ptrdiff_t로 반환한다
std::cout << std::ssize(arr) << std::endl;
std::array에서 size는 상수이기 때문에 위 함수들은 전부 constexpr로 반환한다 (심지어 constexpr이 아닌 std::array 객체에 대한 호출일때도)
이 뜻은 곧 해당 함수들을 상수 표현식 내에서도 사용이 가능하다는 뜻이고 반환된 size는 narrowing conversion 없이 int로 변환이 가능하다는 의미이다
constexpr int length{ static_cast<int>(std::size(arr)) }; // 명시적 캐스팅 사용 권장이때 컴파일러에 따라 다음과 같은 문제가 발생할 수 있다
void printLength(const std::array<int, 5> &arr)
{
// arr가 함수 매개변수이므로 std::size(arr)이 constexpr이 아님
// constexpr int length{ static_cast<int>(std::size(arr)) }; // 오류 발생
// 오류를 피하기 위해 constexpr을 제거해야 함
int length{ static_cast<int>(std::size(arr)) };
std::cout << "length inside function: " << length << '\n';
}
int main()
{
std::array arr { 9, 7, 5, 3, 1 };
constexpr int length{ static_cast<int>(std::size(arr)) }; // 여기서는 잘 작동함
std::cout << "length outside function: " << length << '\n';
printLength(arr);
return 0;
}C++23이전에는 위 size()관련 함수들은 매개변수가 const &로 전달될 때 non-constexpr을 반환하는 문제가 있었다
따라서 컴파일 에러를 피하기 위해 constexpr을 뺀 변수에 할당해야 한다 혹은 배열의 길이를 비타입 템플릿 매개변수로 하기 위한 함수 템플릿을 만드는것이다
template <auto Length> //std::array의 length가 비타입 template 매개변수이기 때문에 컴파일 타임 상수임
void printLength(const std::array<int, Length>& arr)
{
constexpr auto value{ Length }; //OK
}std::array에는 std::vector와 마찬가지로 runtime bounds check를 하는 at()이 존재한다, 범위를 벗어나는 인덱싱을 하기 되면 std::out_of_range 예외를 발생시킨다
operator[ ] 는 이러한 과정이 없이 바로 메모리에 접근하기 때문에 더 빠르지만 위험하다
at()과 [ ]의 인덱슨는 size_type 타입 (std::size_t)일것이기 때문에 constexpr 값으로 인덱싱을 한다면 narrowing conversion이 발생하지 않지만 non-constexpr의 signed 정수 값으로 인덱싱 한다면 narrowing conversion이 발생할 수 있다
int index{ -1 };
arr[index]; //constexpr이 아닌 signed 정수값으로 indexing함, 경고 발생가능 및 out of bounds 로 인한 의도하지 않은 동작이 발생할 수 있다 (매우 큰 숫자로 변환되면서)std::array의 size는 constexpr이고 index도 constexpr이라면 컴파일러는 해당 index가 bound내에 있는지 컴파일 타임에 검사할 수 있어야 한다, 또한 bound를 벗어난다면 컴파일 에러를 출력해야 한다
하지만 operator[ ]는 bound check를 하지 않고 at()은 런타임에만 bound check를 한다, 따라서 std::get< index >(array)을 사용하여 컴파일 타임에 bound check를 하여 element에 접근이 가능하다
constexpr std::array arr{ 9, 7, 5, 3, 1 };
std::cout << std::get<3>(arr); //3
std::cout << std::get<6>(arr); //compile error!
std::get< index >(array)에서 index는 반드시 constexpr 상수여야 한다, std::get의 구현에는 index가 배열의 size보다 작은지 확인하는 static_assert가 존재하기 때문에 컴파일 에러시 static_assert failed error를 뱉게 된다
템플릿 인자는 반드시 컴파일 타임 상수여야 하기 때문에 std::get의 index는 반드시 컴파일 타임 평가 상수여야 한다
std::array passing and returning
std::array를 함수에 전달하고 return하려면 어떻게 해야할까?
다른 클래스와 마찬가지로 std::array 타입의 pass by value하게 되면 복사 비용이 발생할 수 있다, 따라서 pass by ref를 해야한다
std::array를 함수의 매개변수로 사용하려면 타입과 size를 명시적으로 지정해야 한다
void foo(const std::array<int, 5>& arr)
{
for (const auto& element : arr)
{
std::cout << element << " ";
}
std::cout << std::endl;
}
int main()
{
std::array arr{ 1, 2, 3, 4, 5 };
foo(arr);
return 0;
}이러한 함수 호출 시 std::array의 타입이 정확히 일치해야 한다
CTAD는 함수 매개변수에서 작동하지 않기 때문에 타입과 length를 꼭 작성해야 한다
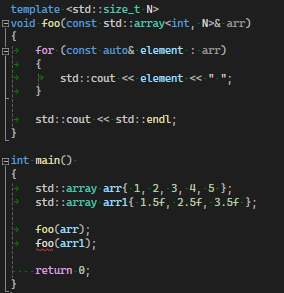
그렇다면 어떠한 타입이나 size를 가진 std::array를 모두 인자로 받을 수 있는 함수를 만들기 위해서는 함수 템플릿을 사용해야 한다
std::array는
template<typename T, std::size_t N> // N은 비타입 템플릿 매개변수
struct array;이와 같이 정의되어 있기 때문에 같은 템플릿 매개변수를 사용하는 함수 템플릿을 만들 수 있다
template <typename T, std::size_t N>
void foo(const std::array<T, N>& arr)
{
for (const auto& element : arr)
{
std::cout << element << " ";
}
std::cout << std::endl;
}
int main()
{
std::array arr{ 1, 2, 3, 4, 5 };
std::array arr1{ 1.5f, 2.5f, 3.5f };
foo(arr);
foo(arr1);
return 0;
}여기서 안정성을 높이기 위해서 static_assert()로 검사하는것도 좋은 방식이다
static_assert(N != 0, "error");타입과 size 중 하나만 템플릿화도 가능하다
float type의 std::array 객체를 인자로 넘기려고 하니 컴파일 에러가 발생하는걸 확인할 수 있다
이러한 비타입 템플릿 매개변수 선언을 조금 더 편하게 하기위해 C++20부터는 auto를 사용할 수 있다, (인자로부터 타입을 추론하게 할 수 있다)
template <typename T, auto N> //auto 사용
void foo(const std::array<T, N>& arr)
{
for (const auto& element : arr)
{
std::cout << element << " ";
}
std::cout << std::endl;
}auto는 비타입 템플릿 매개변수임을 나타내고 컴파일러가 인자로부터 타입을 추론한다
템플릿 매개변수는 컴파일 타임 상수이기 때문에 std::get<>()을 사용할 수 있다 (operator[ ]보다 안전한 인덱싱이 가능하다 (컴파일 타임 bound check가 가능))
template <typename T, auto N>
void foo(const std::array<T, N>& arr)
{
std::get<N>(arr);
}혹은 static_assert()를 이용하여 검사하는 방법이 존재한다
위에서 정리한 함수 매개변수가 참조로 넘어오면 constexpr이 아닌 문제가 발생하여 static_assert()에서 컴파일 에러가 발생할 수 있다, 따라서 비타입 템플릿 매개변수를 사용하는게 좋다
static_assert(N != 0);std::array는 std::vector와 달리 포인터만 넘기는 가벼운 Move가 불가능하다 (내부 element를 전부 옮겨야 한다), 하지만 값을 return할때 오버헤드는 RVO나 복사 생략으로 인해 비용이 발생하지 않게 된다
template <typename T, auto N>
std::array<T, N> GetArray() //return by value
{
std::array<T, N> result{ 10, 20, 30, 40, 50 };
return result;
}
int main()
{
std::array fooarr{ GetArray<int, 5>() };
return 0;
}혹은 out-param을 사용하여 값을 반환할 수 있다
template <typename T, auto N>
void GetArray(std::array<T, N>& outArr) //non-const reference
{
outArr[0] = 10;
}
int main()
{
std::array<int, 5> fooarr{ 1, 2, 3, 4, 5 };
GetArray(fooarr);
return 0;
}단 함수가 인자를 수정한다는걸 쉽게 파악하기 힘들며 해당 함수로 다른 std::array를 초기화 할 수 없다, 임시 객체를 생성할 수 없다
클래스 타입의 element를 가진 std::array
컨테이너 클래스 타입 객체들은 기본 타입뿐 아니라 클래스 타입의 element도 가질 수 있다
struct Color
{
int white{};
int black{};
int green{};
};
int main()
{
std::array<Color, 3> colors{};
//aggregate initialization으로 { }값은 Color객체로 암시적 변환
colors[0] = { 1, 2, 3 };
colors[1] = { 4, 5, 6 };
colors[2] = { 7, 8, 9 };
return 0;
}혹은 선언과 동시에 초기화도 가능하다
std::array<Color, 3> colors{ Color{1, 2, 3}, Color{4, 5, 6}, Color{7, 8, 9} };다른 std::array와 마찬가지로 CTAD 적용으로 타입과 length 추론도 가능하다
std::array colors{ Color{1, 2, 3}, Color{4, 5, 6}, Color{7, 8, 9} };하지만 다음과 같은 초기화는 컴파일 에러를 발생시킨다
std::array<Color, 3> colors{ {1, 2, 3}, {4, 5, 6}, {7, 8, 9} }; //compile errorstd::array는 내부적으로 단일 C-style 배열을 가지는 struct로 정의된다
template<typename T, std::size_t N>
struct array {
T implementation_defined_name[N]; // T 타입의 N개 요소를 가진 C 스타일 고정 크기 배열
};따라서 {1, 2, 3}이 단일 C-style 배열을 초기화 하고 나머지는 붕 떠버리는것이다
다음과 같이 { }로 한번 더 묶어주면 내부 단일 C-style 배열을 잘 초기화 할 수 있다
//1
std::array<Color, 3> colors{ {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}} };그렇다면 다음과 같은 경우는 왜 허용될까?
//2
std::array<int, 5> arr{ 1, 2, 3, 4, 5 };같은 개념이라면 std::array 내부의 단일 C-style 배열이 1로 초기화되고 나머지 2, 3, 4, 5는 의미가 없어지는것인데 이는 초기화가 잘 진행된다
C++의 aggregator는 중괄호 생략 (brace elision) 개념을 지원한다, 여러 개의 중괄호가 생략될 수 있는 규칙이다
대표적인 예시가 바로 scalar값으로 초기화 되거나 각 element에 타입이 명시적으로 붙여진 클래스 타입이나 배열로 초기화 될 때이다, 사실 2번도 { {1, 2, 3, 4, 5} }로 초기화 해야하지만 스칼라 int타입이기 때문에 brace elision 처리가 됨, 마찬가지로 { Color{1, 2, 3}, Color{5, 6, 7} }; 이런방식은 명시적으로 클래스 타입이 붙어있기 때문에 brace elision처리가 되어 초기화가 가능한것이다
따라서 1번은 초기화가 불가능하고 2번은 초기화가 가능한것이다
