[Advanced C++] 50. 코드 실행 시간 측정, chrono library, std::iota, 프로그램 성능에 영향을 미치는것들, release & debug build, Dynamic memory allocation (new, delete), Memory leak, dangling pointer, 동적 메모리 할당 실패, 동적메모리 할당 과정
Advanced C++

1. 코드 실행 시간 측정
코드 실행 시간 측정
개발을 하다보면 더욱 성능이 좋은 방식을 선택해야 하고 이때 더 성능이 좋은지 확신할 수 없는 경우가 종종 있다, 성능을 확인하기에 가장 쉬운 방법은 코드가 실행되는데 얼마나 시간이 걸리는지를 측정하는 것이다
C++11부터는 chrono library에 이러한 기능들이 포함되어 있다
chrono 라이브러리에서 필요한 기능만 클래스로 캡슐화해서 사용해보자
#include <chrono>
class Timer
{
public:
void reset()
{
m_beg = Clock::now(); //시간을 현재 시간으로 다시 되돌리기
}
double elapsed() const
{
return std::chrono::duration_cast<Second>(Clock::now() - m_beg).count();
//객체가 생성되고 나서 elapsed()가 호출될때까지의 시간을 반환한다 (count())
}
private:
using Clock = std::chrono::steady_clock;
using Second = std::chrono::duration<double, std::ratio<1, 1>>;
std::chrono::time_point<Clock> m_beg{ Clock::now() };
};< chrono > 헤더는 C++에서 시간과 관련된 기능을 사용하기 위해 필요한 헤더이다, std::chrono 네임스페이스 안에 관련 클래스와 함수들이 정의되어 있다
-
std::chrono::steady_clock
시스템 시간 변경(사용자가 컴퓨터 시간을 변경하는 등)에 영향을 받지 않고 꾸준히 증가하는 시계이다, 시간 간격을 측정하는데 가장 적합한 시계 타입이다 (std::chrono::system_clock은 시스템의 현재 시간을 나타내지만 시스템 시간 변경에 영향을 받기 때문에 시간 간격 측정에는 부적합할 수 있다) -
std::chrono::duration< >
std::chrono::duration은 시간의 간격을 나타내는 템플릿 클래스이다
위의 코드에서 <double, std::ratio<1>>는 시간 간격을 double로 표현하고 std::ratio<1, 1>로 1/1초 단위를 의미한다
만약 밀리초 단위를 사용하고 싶다면 std::chrono::duration<double, std::chrono::milliseconds>로 사용하거나 std::chrono::duration<double, std::ratio<1, 1000>> 으로 사용하면 된다
-
std::chrono::time_point<>
특정 시점을 나타내는 템플릿 클래스이다, 위 코드에서는 Clock 타입 (std::chrono::steady_clock)을 기준으로 한 시점을 의미한다 -
std::chrono::steady_clock::now()
현재 시점을 반환하는 static 멤버 함수이다, 객체가 생성되는 순간의 시간이 m_beg에 저장된다
이제 원하는 코드 영역에 해당 Timer 객체를 인스턴스화 하고 걸리는 시간을 확인할 코드 영역에 elapsed()를 호출해주면 된다
간단하게 선택정렬 코드를 작성하는것과 std::sort를 사용하는것과 시간을 비교해보자
#include <array>
#include <chrono> // std::chrono
#include <cstddef> // std::size_t
#include <iostream>
#include <numeric> // std::iota
void sortArray(std::array<int, g_arrayElements>& array)
{
for (std::size_t startIndex{ 0 }; startIndex < (g_arrayElements - 1); ++startIndex)
{
std::size_t smallestIndex{ startIndex };
for (std::size_t currentIndex{ startIndex + 1 }; currentIndex < g_arrayElements; ++currentIndex)
{
if (array[currentIndex] < array[smallestIndex])
{
smallestIndex = currentIndex;
}
}
std::swap(array[startIndex], array[smallestIndex]);
}
}
int main()
{
std::array<int, g_arrayElements> array;
std::iota(array.rbegin(), array.rend(), 1);
Timer t;
sortArray(array);
std::cout << "Time taken: " << t.elapsed() << " seconds\n";
return 0;
}여기서 std::iota는 iterator 시작과 끝을 받아 초기값을 시작으로 연속된 값으로 범위를 채워주는 함수이다 ex)1, 2, 3, 4, ....
rbegin()은 마지막 역방향 시작 iterator이다 (배열의 마지막 element를 가리킨다), 마찬가지로 rend()는 배열의 역방향 끝 iterator이다 (배열의 첫번째 element 앞을 가리킨다)
시작으로 rbegin(), 끝으로 rend()를 넣었기 때문에 끝에서부터 1, 2, 3, 4...가 들어가 array[0]은 10000이 들어가고 마지막에 1이 들어가게 된다
이제 std::sort로 테스트 해보자
#include <algorithm> // std::sort
int main()
{
std::array<int, g_arrayElements> array;
std::iota(array.rbegin(), array.rend(), 1); // 배열을 10000부터 1까지의 값으로 채웁니다.
Timer t;
std::ranges::sort(array); //C++20
std::cout << "Time taken: " << t.elapsed() << " seconds\n";
return 0;
}시간을 확인해보면 거의 100배정도 std::sort가 빠른걸 확인할 수 있다, 결론적으로 std::sort에서 사용하는 Introsort는 일반 선택 정렬보다 100배정도 빠르다는 것이다
STL 함수들은 굉장히 최적화 되어있고 검증되어 있기 때문에 직접 알고리즘을 구현하기 보다는 STL 함수를 사용하는게 더 효율적이다
프로그램 성능에 영향을 미치는것들
어떠한 것들이 프로그램의 성능에 영향을 미치는지 아는것이 중요하다
- 빌드 대상 확인
debug빌드는 일반적으로 최적화를 끄지만 release빌드는 최적화를 켠다, 위의 sort만 해봐도 엄청난 차이가 발생하는걸 확인할 수 있다
-
release build
배포용으로 컴파일하는 빌드 타겟이다, 컴파일러는 코드 크기를 줄이고 실행속도를 높이기 위해 다양한 최적화를 진행한다 (함수 inline, loop해제, 의미없는 코드 제거 등) -
debug build
개발 및 디버깅 과정에서 사용한다, 디버깅 정보를 가지고 있고 최적화를 거의 수행하지 않거나 최소한으로 수행하여 원래 코드 구조와 실행 흐름을 파악하기 쉽게 한다 (실행 속도 저하)
- 백그라운드 작업
시스템이 cpu나 메모리, 하드를 많이 사용하는 작업을 백그라운드에서 하고있는지 확인이 필요하다, 심지어 웹 브라우저 활성탭도 아무것도 하지 않는것처럼 보이지만 수많은 광고를 로드하고 자바스크립트를 파싱하는 경우 cpu를 많이 사용할 수 있다
성능 측정 시 시간은 보통 한 3번정도 측정하는게 좋다 (위의 외부 요인을 감안해서), 또한 머신마다 상대적인 측정이 되기 때문에 다른 환경에서는 의미없는 수치가 될 수 있다
단일 머신에서 측정 시 최소 3번정도 측정하고 시스템 환경을 유지하는것이 중요하다
2. Dynamic memory allocation
동적 메모리 할당
C++은 세 가지 메모리 할당을 지원한다
-
정적 메모리 할당 (static memory allocation)
static 변수, 전역 변수 정의 시 발생한다, 이러한 타입의 변수를 위한 메모리는 프로그램 실행 시 한번 할당되고 프로그램의 수명동안 지속된다 -
자동 메모리 할당 (Automatic memory allocation)
함수 매개변수, 지역변수에 정의 시 발생한다, 이러한 타입의 변수를 위한 메모리는 관련 코드 블록에 진입할 때 할당되고 코드 블록을 빠져나오면 해제된다 (stack memory 사용) -
동적 메모리 할당 (Dynamic memory allocation)
동적 메모리 할당이 필요한 경우는 다음과 같이 생각하면 된다
예를들어 게임에 몬스터가 존재하고, 이러한 몬스터들은 죽기도 하고 스폰이 되기도 하면서 수가 변하게 된다, 따라서 런타임에 동적으로 메모리 할당이 되어야 한다
이러한 상황을 동적 메모리 할당이 아닌 메모리 할당법으로 사용하려면 미리 컴파일 타임에 최대 크기를 추측하고 그 크기가 충분하기를 바래야한다
좋지 않은 방법인 이유는 다음과 같다
-
변수가 실제로 사용되지 않는다면? 메모리 낭비가 된다
예상해서 메모리 할당 크기를 크게 잡은 변수를 사용하지 않는다면 그대로 메모리 낭비가 되는것이다 -
대부분의 일반 변수들은 stack 메모리에 할당되고 stack은 굉장히 작다
동적 메모리 할당으로 하지 않고 스택 메모리에 할당을 전부 하게 된다면 stack overflow가 발생하여 크래시가 발생할 수 있다 -
크기를 예상한다는것 자체가 좋지 않음
런타임에 사용자로부터 얼마나 큰 데이터가 들어올지 모르는 상태에서 예상하고 크기를 잡는것은 의도치 않은 동작을 발생시킬 가능성이 높다
따라서 동적 메모리 할당을 통해 실행중인 프로그램이 필요할때마다 OS로부터 메모리를 요청하는게 좋다 (stack메모리가 아닌 OS가 관리하는 훨씬 큰 메모리 풀인 heap에서 할당된다)
new
단일 변수를 동적 할당하기 위해서는 new 타입을 사용해주면 된다
new int; //int타입 하나 크기의 메모리를 OS에 요청한다new연산자는 OS에 요청해서 받은 메모리를 사용하여 객체를 생성하고 할당된 heap메모리의 주소를 담고 있는 포인터를 반환한다
int* ptr{ new int };int크기의 heap영역 메모리를 할당받고 해당 주소를 ptr에 넣은것이다
포인터 역참조로 해당 메모리에 접근이 가능하다
*ptr = 10; //할당받은 heap영역 메모리에 10을 할당한다heap에 할당된 객체에 접근하는건 stack에 할당된 객체에 접근하는 것보다 느리다
(stack에 할당된 객체는 주소를 알고있기 때문에 바로 값을 가져올 수 있다, 하지만 heap에 할당된 객체는 주소를 모르기 때문에 우선 heap에 할당된 객체의 주소를 가져오고 역참조로 값을 가져와야 하기 때문에 약간의 오버헤드가 있다)
동적 메모리 할당은 어떤 방식으로 작동할까?
컴퓨터에는 응용 프로그램이 사용할 수 있는 메모리가 존재하고 응용 프로그램을 실행하면 해당 응용 프로그램을 메모리 일부에 로드한다
이때 응용 프로그램이 사용하는 메모리는 여러 영역으로 나뉘게 된다 (코드, 데이터, 스택, 힙 영역)
이때 많은 양의 메모리가 프로그램이 요청할때까지 기다리며 그냥 방치되게 된다
메모리를 동적 할당하게 되면 OS에 위의 방치된 메모리의 일부를 사용하기 위해 예약하도록 요청하는것이다, 메모리 요청을 수행할 수 있다면 해당 메모리의 주소를 응용 프로그램에 return하게 되고 응용 프로그램은 할당받은 메모리를 원하는 대로 사용이 가능해진다
할당받은 메모리 사용이 끝나면 다시 OS에 return할 수 있다
정리하면 static, auto 메모리 할당과 다르게 dynamic 메모리 할당은 프로그램 자체가 메모리를 요청하고 처리하는 책임을 지게 되는것이다
stack메모리에 할당되는 객체의 할당과 해제는 자동으로 수행되기 때문에 프로그래머가 직접 메모리 주소를 다룰 필요가 없다, 그렇지만 heap메모리에 할당되는 객체의 할당 및 해제는 자동으로 수행되지 않고 프로그래머가 직접 해줘야 한다
동적 할당 변수 초기화
변수를 동적 할당할 때 초기화가 가능하다
int* ptr1{ new int(10) }; //직접 초기화
int* ptr2{ new int{20} }; //리스트 초기화만약 초기화 하지않고 new int;로 끝난다면 해당 메모리 공간은 garbage value가 될 수 있다 (기본타입일 경우), 만약 클래스 타입이라면 기본 생성자가 호출된다
동적 할당 메모리 해제
동적 할당된 변수의 사용이 끝난다면 명시적으로 메모리 해제를 해줘야 한다, delete 연산자를 사용한다
delete ptr1;
ptr1 = nullptr;delete 연산자는 이름과 다르게 내부적으로 아무것도 삭제하지 않는다, 단지 가리키고 있는 메모리를 OS에 다시 반환한다
이때 ptr1에는 해제된 메모리 주소를 담고있게 되고(dangling 상태) 이에 접근하게 된다면 의도치 않은 동작이 발생할 수 있다, 따라서 nullptr로 명시적으로 아무런 메모리 주소를 담고있지 않게 해주는게 좋다
delete는 반드시 new로 동적 할당된 메모리에 대해서만 사용해야 한다, stack에 할당된 변수의 주소나 이미 해제된 메모리 주소에 delete(double free)를 사용하면 정의되지 않은 동작을 유발한다
dangling pointer
C++은 이미 해제된 메모리의 내용이나 해제된 메모리 주소를 담고있는 포인터 값에 대해 어떠한 보장도 해주지 않는다 (그저 헤제된 메모리 주소를 담고있게 된다)
이전에도 정리했듯 이렇게 해제된 메모리를 가리키고 있는 포인터를 dangling pointer라고 한다, 이러한 dangling pointer를 역참조하면 정의되지 않은 동작이 발생하거나 크래시가 발생한다
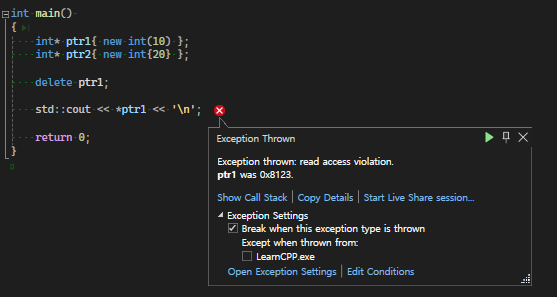
다음과 같은 dangling pointer 문제가 자주 발생할 수 있다
int* ptr1{ new int(10) };
int* testptr{ ptr1 };
delete ptr1;
ptr1 = nullptr;ptr1을 delete하고 nullptr로 처리했지만 testptr은 여전히 ptr1의 주소를 담고 있기 때문에 testptr은 dangling pointer이다, 역참조 하지 않도록 조심해야 한다
따라서 여러 포인터가 동일한 동적 메모리를 가리키지 않는게 좋다, 또한 메모리가 헤제되었다면 그 즉시 포인터 변수를 nullptr로 설정하는게 좋다
new 연산자 실패
OS로부터 메모리 할당을 요청할 때 OS가 해당 메모리 요청을 승인할 메모리가 없을 수도 있다
new가 실패한다면 std::bad_alloc 타입의 예외가 발생하게 되고 이러한 예외처리를 하지 않는다면 바로 크래시가 발생할 수 있다
일반적으로 new를 실패할 때 예외를 발생시키거나 크래시가 발생하는건 좋지 않기 때문에 다음과 같이 new에 실패했을 때 nullptr을 return하도록 지시할 수 있다
int* ptr1{ new(std::nothrow)int };이렇게 하면 new가 실패하면 nullptr을 return한다
new를 하고 nullptr 체크를 통해 동적 메모리 할당이 잘 수행되었는지 확인하고 사용하는것도 좋은 방법이다
int* ptr1{ new(std::nothrow)int };
if (!ptr1)
{
std::cout << "Memory allocation failed!" << std::endl;
return 1;
}
*ptr1 = 20;nullptr을 통해 해당 포인터가 아무런 메모리를 가리키지 않는다면 할당하는 방식으로 코드를 작성할 수 있다
int* ptr1{ nullptr };
if (!ptr1)
{
ptr1 = new int{ 100 };
}Memory leaks
동적할당된 메모리는 명시적으로 해제하지 않으면 프로그램이 종료될 때 까지 할당된 상태로 유지된다
그러나 동적할당된 메모리 주소를 담는 포인터는 지역변수에 대한 유효 범위 규칙을 따른다
이는 메모리 누수 문제를 야기할 수 있다
void foo()
{
int* ptr1{ new int{} }; //지역변수
}foo()함수가 종료되면서 ptr1은 소멸되지만 실제 할당된 메모리는 해제되지 않는다
ptr1이 동적 할당된 메모리 주소를 담고있는 유일한 포인터 변수였는데 지역변수기 때문에 함수가 종료되며 소멸되고 결국엔 동적 할당된 메모리에 대한 참조가 더 이상 없어지는것이다
결과적으로 동적 할당된 메모리를 더 이상 해제할 수 없고 메모리 누수가 발생하게 된다
일반적으로 메모리 누수는 위와 같은 경우 (동적 할당된 메모리 주소를 잃어버릴때) 많이 발생한다
계속해서 메모리가 할당된 상태기 때문에 OS에서 사용도 불가능하다, 또한 다른 프로그램이 사용할 수 있는 메모리 영역도 줄어들기 때문에 성능 문제가 발생하기 쉽다
new로 메모리 동적할당을 했으면 반드시 참조를 잃기 전에 delete를 꼭 해줘야 한다
아래와 같은 경우에서도 메모리 누수가 발생할 수 있다
int a{ 5 };
int* ptr{ new int{} };
ptr = &a; //동적할당 메모리 주소 잃어버림, 메모리 누수 발생또한 이중 할당을 통해서도 메모리 누수가 발생할 수 있다
int* ptr{ new int{} };
ptr = new int{};두번째 할당받은 동적 메모리 주소로 덮어씌워지기 때문에 기존 메모리 참조를 잃게 되어 메모리 누수가 발생할 수 있다
