[Advanced C++] 53. Stack & Heap, Call Stack, Stack Overflow, Recursion (재귀), Command Line Arguments (int main(int argc, char* argv[]))
Advanced C++

1. Stack & Heap
Stack, Heap 메모리
프로그램이 사용하는 메모리는 여러 segments들로 나뉜다
-
Code Segment
Text segment라고도 하며 컴파일 된 프로그램 코드가 저장되는 메모리다, 일반적으로 read-only임 -
BSS Segment
명시적으로 초기화되지 않은 전역변수나 정적 변수들이 저장되는 메모리다, Uninitialized data segment라고도 한다 -
Data Segment
Initialized data segment라고도 하며 초기화 된 전역 변수와 정적 변수가 저장된다 -
Heap
동적으로 할당된 객체들이 저장되는 메모리다 -
Stack
함수 매개변수, 지역변수, 함수와 관련된 정보들이 저장되는 곳이다
Heap
Heap영역은 동적 메모리 할당 시 사용되는 메모리를 관리한다
new연산자로 동적 메모리 할당 시 Heap에 할당이 된다
int* ptr{ new int };
int* arr{ new int[10] };int를 4byte라고 가정했을 때 new int는 Heap의 4byte를 할당하고 new int[10]은 40byte를 할당한다
이렇게 할당된 메모리 주소는 new 연산자에 의해 return되어 포인터 변수에 저장할 수 있다
여기서 중요한 점은 이렇게 코드상 연속적으로 동적할당된 메모리가 반드시 연속적인 메모리 주소가 아니라는 점이다
int* ptr1{ new int };
int* ptr2{ new int };ptr1, ptr2는 코드상으로 연속적으로 동적할당 되었지만 반드시 연속적인 메모리 주소를 할당받는게 아니라는것임
이렇게 동적 할당된 변수를 delete하면 할당된 메모리는 다시 반환되고 추후에 있을 할당 요청에 사용될 수 있다
동적할당된 메모리 주소를 저장한 포인터를 delete하는건 메모리를 반환한다는 의미이다
heap은 굉장히 큰 메모리 풀이기 때문에 큰 사이즈의 데이터를 할당할 수 있다, 단 stack에 비해 heap에 메모리를 할당하는건 비교적 느리다 또한 명시적으로 할당된 메모리가 해제될 때 까지 할당된 상태로 남아있어 메모리 누수가 발생할 수 있다
동적할당된 메모리는 포인터를 통해 접근하기 때문에 역참조가 발생하여 약간의 오버헤드가 발생할 수 있다
Stack
Call Stack은 프로그램 시작부터 현재 실행 지점까지 활성화 된 모든 함수(호출되고 종료되지 않은 함수)를 추적하고 모든 함수 매개변수와 지역변수의 할당을 처리한다
call stack은 stack 자료구조로 구현된다
그렇다면 stack 자료구조란 어떤것일까?
자료구조란 데이터를 효율적으로 사용할 수 있도록 구성하는 프로그래밍 매커니즘이다
앞서 정리한 배열, 구조체도 자료구조의 일종이며 대부분의 프로그래밍에서 사용되는 자료구조들은 STL에 구현되어 있다
프로그래밍에서 stack은 여러 변수를 담는 컨테이너 자료구조이다, 배열과 비슷하지만 배열은 원하는 element에 접근하고 수정하는 임의접근이 가능한 반면 stack은 제한적이다
stack은 top()이나 peek()으로 맨 위 element를 볼 수 있고 pop()과 push()로 맨 위에 element를 꺼내고 추가할 수 있다
stack은 LIFO(Last In First Out) 후입선출 구조이다, 마지막에 push된 element가 가장 먼저 pop된다
프로그램은 main()함수가 OS에 의해 call stack에 push되면서 시작된다, 그리고 함수 호출이 발생하면 해당 함수가 call stack에 push되고 함수가 종료되면 pop된다
스택 되감기(stack unwinding)은 함수 실행중 예외가 발생했을 때 catch블록을 찾기 위해서 현재 함수를 종료하고 스택 프레임을 하나씩 pop하며 위로 거슬러 올라가는걸 의미한다
따라서 call stack을 보면 현재 실행 지점에 도달하기 위해 호출된 모든 함수를 알 수 있다
(디버깅의 기본)
stack에 push되고 pop되는 데이터들을 stack frame이라고 하며 stack frame은 하나의 함수 호출과 관련한 모든 데이터를 포함한다
stack pointer(SP)는 레지스터로서 현재 call stack의 가장 위가 어디인지를 추적한다
(element가 call stack에서 pop되면 stack pointer를 한칸 위로 올린다(stack은 높은주소 -> 낮은 주소로 쌓인다))
call stack 동작 방식
call stack의 동작은 다음과 같다
-
함수 호출 시 stack frame이 생성되어 stack에 push된다
stack frame은 함수 호출 다음 명령어의 주소(return address, 호출된 함수가 종료되고 돌아갈 주소이다), 모든 함수 인자, 모든 지역변수를 위한 메모리, 함수가 반환될 때 복원해야 하는, 함수에 의해 수정된 모든 레지스터의 저장된 복사본을 가지고 있다 -
함수의 시작 지점으로 점프
-
함수 내부 명령어 실행
-
함수 종료 시 레지스터들이 call stack에서 복원
-
stack frame이 stack에서 pop됨 (모든 지역변수, 인자를 위한 메모리 해제)
-
반환값 처리
-
cpu가 return address를 통해 실행 재개
아키텍처에 따라 다르지만 call stack은 0을 향해서 가까워질 수 있고, 0으로부터 멀어지는 방향으로 증가할 수 있다 따라서 새로 push된 stack frame은 이전 stack frame보다 더 높을수도 있고 낮을수도 있는 메모리 주소를 가질 수 있다
int foo(int a)
{
return a;
}
int main()
{
foo(100);
return 0;
}위 코드의 call stack은 다음과 같다
- main()
- foo() -> 매개변수 포함
- main()
stack overflow
stack은 크기가 제한되어 있기 때문에 당연하게도 제한된 양의 정보만 담을 수 있다, 기본적으로 VS는 기본 stack크기가 1MB이며 g++,Clang은 최대 8MB까지 가능하다
따라서 프로그램이 stack에 너무 많은 정보를 담으려고 하면 stack overflow가 발생하게 된다, stack overflow는 stack의 모든 메모리가 할당되었을 때 발생한다
stack에 너무나 많은 변수 할당, 너무 많은 중첩 함수 호출등으로 인해 발생할 수 있으며 OS에서 이러한 stack overflow가 발생 시 접근 위반(access violation)을 발생시키고 크래시를 내버린다
int stack[10000000]; //int를 4byte로 가정 시 40MB (stack overflow)
std::cout << stack[0]; int counter{ 0 };
void StackTest()
{
++counter;
if (counter > 0)
{
StackTest(); //재귀
}
std::cout << "hi";
}
int main()
{
StackTest(); //너무나 많은 재귀함수 호출로 인해 stack overflow
return 0;
}stack메모리를 할당하고 사용하는건 heap에 비해 비교적 빠르다, heap에 할당된 객체와 다르게 변수를 통해 직접 접근이 가능하다
단 stack은 상대적으로 작기 때문에 크기가 큰 데이터를 저장하는 작업에는 적합하지 않다
2. Recursion
재귀함수
재귀함수는 자기 자신을 호출하는 함수를 의미한다
재귀함수를 사용할 때 가장 중요한 점은 infinite loop를 발생시켜선 안된다는 것이다
void StackTest()
{
++counter;
if (counter > 0)
{
StackTest(); //infinite loop
}
std::cout << "hi";
}infinite loop로 인해 stack frame이 stack에 계속 push되면서 stack overflow가 발생하고 crash가 발생한다
이때 tail call이라는 개념이 등장한다, tail call이란 함수의 가장 마지막에서 발생하는 함수 호출을 의미하는데 재귀적인 tail call을 가진 함수는 컴파일러에 의해 최적화 되기 쉽다 (크래시가 발생하지 않고 영원히 호출될 것)
함수 A의 마지막에서 A를 다시 호출한다고 가정하면 컴파일러는 이전 함수 A가 쓰던 stack 공간을 다음에 호출될 A함수가 이어받아서 사용하는 방식으로 최적화 하는것이다 (계속 push하지 않기때문에 stack overflow가 발생하지 않는다)
이러한 최적화가 있다고 해도 결국 재귀함수의 가장 중요한 점은 종료 조건이 확실해야 하다는것이다
int counter{ 0 };
void StackTest()
{
++counter;
if (counter > 5) //재귀함수 종료 조건
{
return;
}
std::cout << counter << std::endl;
StackTest();
} int sumTo(int sumto)
{
if (sumto <= 0)
{
return 0; // 종료 조건
}
if (sumto == 1)
{
return 1; // 종료 조건
}
return sumTo(sumto - 1) + sumto; //재귀 함수 호출
}sumTo(1)은 1을 return
sumTo(2)는 sumTo(1) + 2, 즉 1 + 2 = 3을 return
sumTo(3)은 sumTo(2) + 3, 즉 3 + 3 = 6을 return
sumTo(4)는 sumTo(3) + 4, 즉 6 + 4 = 10을 return
sumTo(5)는 sumTo(4) + 5, 즉 10 + 5 = 15를 return
재귀함수에서 조건값을 제어할때는 operator--, ++보다 x - 1을 사용하는게 side effect를 피할 수 있다
이러한 재귀함수의 종료 조건 역할을 하는것을 base case라고 하고 위 코드에서는 sumto <= 0, sumto == 1이 된다
대표적인 수학적 재귀 알고리즘 중 하나는 피보나치 수열이다
int fibonacci(int count)
{
if (count == 0)
{
return 0;
}
if (count == 1)
{
return 1;
}
return fibonacci(count - 1) + fibonacci(count - 2);
}위 코드는 0, 1, fib(2) + fib(1), fib(3) + fib(2), fib(4) + fib(3)가 되고
그 결과 0, 1, 1, 2, 3가 된다
하지만 위의 피보나치 알고리즘은 효율적이지 않다, 왜냐하면 불필요한 재귀함수 호출이 존재하기 때문이다
fibonacci(5)를 생각해보면 fibonacci(4) + fibonacci(3)이 호출된다, 이때 fibonacci(4)와 fibonacci(3)는 이미 호출된 함수지만 이를 재 호출하게 된다는 의미이다
따라서 Memoization Algorithms을 사용하여 조금 더 효율적으로 만들어줄 필요가 있다
Memoization Algorithms는 함수 호출의 결과를 캐싱하여 동일한 호출이 발생할 때 캐싱된 결과값을 return하는 방식의 알고리즘이다
int fibonacci(std::size_t count)
{
static std::vector<long long> results{ 0, 1 };
// 이 count 값을 이미 본 적이 있다면 캐시된 결과를 사용
if (count < results.size())
return results[count];
// 그렇지 않으면 재귀 함수 호출
results.push_back(fibonacci(count - 1) + fibonacci(count - 2));
return results[count];
}이러한 Memoization Algorithm을 적용하면 기존의 재귀함수보다 더욱 더 적은수의 함수 호출을 하여 기능을 구현할 수 있다
Recursive vs Iterative
그렇다면 위 재귀함수로 구현한 기능들을 for loop나 while loop와 같은 반복문을 사용해서 만들지 않는 이유가 무엇일까?
결국 재귀적인 문제는 반복을 통해 구현이 가능하다, 하지만 재귀로 구현하는게 더 간단하고 가독성에 좋다
하지만 재귀는 반복보다 함수 호출이 더 많기 때문에 stack frame이 더 많이 push되고 pop되면서 오버헤드가 증가한다
그렇다고 반복이 재귀보다 무조건 더 좋은 선택이라는 의미는 아니다, 유지보수성을 위해 재귀함수를 통한 구현이 더 권장될 수 있다, 물론 재귀로 구현해야 정말 의미있는 구조가 아니라면 반복을 사용하는게 더 좋다고 생각한다
3. Command Line Arguments
명령줄 인자
코드가 컴파일되고 링킹 단계를 거쳐 실행파일이 생성되고 이를 실행하면 프로그램이 실행된다, 프로그램이 실행될 때 main() 함수의 맨 위에서 시작된다
int main()
{
}이제까지 사용했던 main()은 매개변수를 받지 않았다, 하지만 다양한 프로그램을 실행시키기 위해서는 특정한 입력이 필요하다
예를들어 이미지 파일을 읽고 썸네일을 만드는 프로그램을 작성할 때 해당 프로그램이 어떤 이미지 파일을 읽고 처리해야 하는지 알려줄 방법이 있어야 한다
지금까지 정리했던 방식으로는 다음과 같이 해결할 수 있다
int main()
{
std::cout << "이미지 파일명 입력";
std::string imageFileName{};
std::cin >> imageFileName;
//열기 및 썸네일 생성 처리
}이러한 방식은 유저가 입력을 할 때 까지 프로그램이 무한 대기를 하는 문제가 있다, 또한 특정 디렉토리의 모든 이미지 파일에 대한 처리가 필요할 때 위 코드의 프로그램으로 실행하게 되면 존재하는 모든 이미지 파일명을 전부 입력해야 한다
결론적으로 써드파티 프로그램이 우리가 만든 프로그램에 입력을 할 수 있게 해야한다는 것이다
명령줄 인자는 프로그램이 시작될 때 OS에 의해 프로그램에 전달되는 문자열 인자를 말한다, 이를 사용할 수 있고 무시할 수 있다
명령줄 인자는 사람이나 써드파티 프로그램이 우리가 만든 프로그램에 입력을 제공하는 방법을 제공한다
VS에서 프로그램에 명령줄 인자를 전달하기 위해서는 프로젝트의 Properties의 Debugging탭에서 Command Line Arguments에 원하는 명령줄 인자를 입력해야 한다
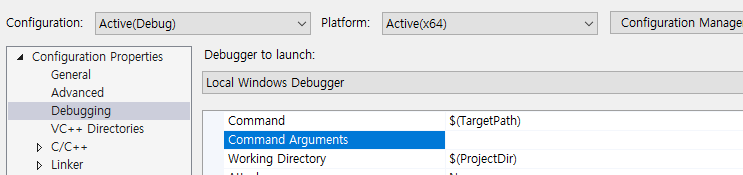
C++ 프로그램에서 명령줄 인자에 접근하기 위해서는 다른 형태의 main()을 사용해야 한다
int main(int argc, char* argv[])여기서 argc는 프로그램에 전달된 명령줄 인자의 개수를 의미한다, 최소 1이된다 (프로그램 자체의 이름을 가짐)
argv는 실제 인자값이 저장되는 곳이다, C-style의 문자 포인터의 배열이다
int main(int argc, char* argv[])
{
std::cout << argc << std::endl; //명령줄 인자의 개수
for (auto count = 0; count < argc; count++)
{
std::cout << argv[count] << std::endl; //명령줄 인자값
}
return 0;
}
명령줄 인자는 제공된 값이 숫자라도 문자열로 전달된다, 따라서 숫자로 사용하기 위해서는 변환이 필요하다
#include <sstream> // std::stringstream
int main(int argc, char* argv[])
{
if (argc <= 1)
{
if (argv[0] && argv[0][0] != '\0') // argv[0]이 null이 아니고 빈 문자열이 아닌지 확인 {
std::cout << "Usage: " << argv[0] << " <number>" << '\n';
}
else
{
std::cout << "Usage: <program name> <number>" << '\n';
}
return 1;
}
std::stringstream convert{ argv[1] }; // std::stringstream 변수를 argv[1]값으로 초기화
int myint{};
if (!(convert >> myint)) // operator >>로 변환한다 (std::cin처럼)
myint = 0; //변환 실패
std::cout << "Got integer: " << myint << '\n';
return 0;
}이렇게 명령줄 인자를 넘기게되면 OS가 명령줄 인자 구문 분석을 진행한다
OS에는 큰따옴표, 백슬래시와 같은 특수문자를 처리하는 규칙이 있다
명령줄 인자로 Hello world!를 넘긴다면 Hello와 world!로 명령줄 인자가 넘어가게 된다, 이때 " "로 묶어준다면 Hello world!로 하나로 넘어가게 된다
이떄 \"Hello world!\" 로 넘긴다면 " "도 문자 그대로 포함할 수 있도록 해준다
("Hello와 world!"로 넘어감 (windows 기준))
OS에 따라 이러한 구문 분석 규칙이 다르기 때문에 결과가 다를 수 있다
