
1. 변수와 레지스터
변수의 선언 및 사용
메모리에서 .data영역은 초기화 된 데이터를 사용할 때 사용한다
어셈블리에서 .data영역에서의 변수선언은 [변수이름][크기] [초기값]으로 한다
이때 크기는 db(1), dw(2), dd(4) dq(8)로 키워드를 사용한다
db의 b는 byte, dw는 word, dd의 d는 dword, dq의 q는 qword이다
16진수에서 숫자 2개당 1byte이다
section .data
a db 0x11
b dw 0x2222
c dd 0x33333333
d dq 0x4444444444444444.bss영역은 초기화 되지 않은 데이터를 사용할 때 사용
어셈블리에서 .bss영역에 변수 선언은 [변수이름][크기] [개수] 로 한다
마찬가지로 크기는 키워드를 사용한다 resb(1), resw(2), resd(4), resq(8)로 나타내며 b,w,d,q의 의미는 같다
section .bss
e resb 10왜 .data영역 .bss영역을 나눌까?
초기값이 있는 변수들은 실행file에도 존재해야 하기 때문에 .data영역에 있어야 하지만 초기값이 없는 변수들은 굳이 실행file에 있을 필요가 없기 때문에 .bss영역에 존재한다 그 결과 실행file의 크기도 줄어든다
다음은 위의 빌드 결과이다
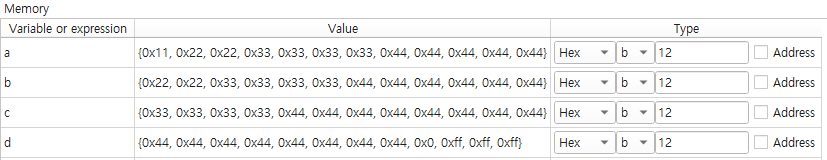
메모리를 보게 되면 a,b,c,d에 알맞은 값이 16진수로 잘 들어가 있는걸 확인할 수 있다
메모리<->레지스터 간의 데이터 복사
mov rax, arax에 a의 데이터를 mov시키게 되면 a의 값 자체가 rax로 mov되는게 아닌 a변수의 주소가 mov된다
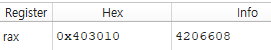
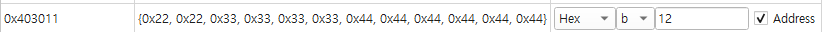
메모리에 데이터가 올라갈 때 메모리에는 이 데이터를 구분할 수 있도록 주소라는게 존재한다
이러한 메모리의 주소로 값을 가져오거나 수정이 가능하다
(c++의 포인터 개념, 주소는 실행 될 때 마다 변경될 수 있다 고정값 아님)
따라서 위의 a변수의 주소는 0x403010이 된다
이를 이용해서 주소에 1byte만큼 더해주면 그 다음인 b의 주소가 되는걸 확인할 수 있다
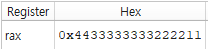
그렇다면 실제 값은 어떻게 mov해야 할까?
mov rax, [a]이런식으로 a변수 주소에 있는 데이터 자체를 mov할 수 있다, 단 이때 크기를 명시하지 않으면 rax크기인 8byte 전체 값을 가져오기 때문에 이런 값이 나오게 된다

mov al, [a]이렇게 필요한 만큼만 (1byte) mov시켜서 사용하는게 좋다
레지스터에서 메모리로, 상수를 레지스터로 값을 mov하는것도 같은 방식이다
상수 전달 시 앞에 type을 꼭 붙여야 한다 ex) byte, word, dword
mov cl, 0xff
mov [a], byte 0x55
mov [a], cl 이러면 a에 0x55가 들어간 뒤 cl의 0xff가 a value로 들어가게 된다
메모리 변수끼리, 상수 끼리는 어셈블리에서 계산이 불가능하다
2. 문자와 엔디안
assembly라고 해서 데이터 값을 무조건 2진수, 16진수로만 입력해야 하는건 아니다
a db 17이런식으로 a에 17이라는 10진수 값도 넣을 수 있다
하나의 변수에 여러개의 데이터를 ,로 구분하여 집어넣을 수 있다
a db 0x11, 0x12, 0x13, 0x14문자는 어떻게 선언해야 할 까?
testmsg db 'Hello World', 0x00일반 변수와 마찬가지로 [변수명][크기] [값]으로 선언이 가능하다
이때 testmsg 메모리를 까보게 되면 다음과 같이 나온다
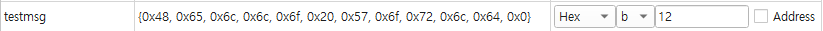
이 0x48, 0x65들은 Hello World의 아스키 코드를 16진수로 변환한 값이다
(이 16진수 값들을 testmsg에 그대로 넣어도 같은 Hello World가 출력된다)
엔디안이란 프로그래밍에서 메모리 등의 1차원 공간에서 데이터를 어떻게 배열하는지의 방식을 의미한다
b dd 0x12345678다음과 같이 b에 dd로 0x12345678 데이터를 넣었다, b변수를 메모리에서 까보게 되면
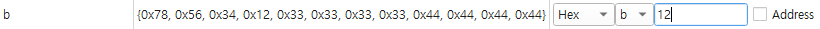
12345678순이 아닌 0x78, 0x56순으로 나열되어 있다
이를 Little-Endian이라 한다 (거꾸로 나열, Big-Endian은 순서대로 나열)
(대부분의 intel, amd환경에서는 Little-Endian으로 데이터를 배열한다)
지금 봤을때는 별로 중요해보이지 않을 수 있지만 추후 서버로 데이터를 넘길 때 엔디안 방식이 다르게 되면 큰 이슈가 발생할 수 있다
그렇다면 왜 직관적이지 않은 Little-Endian을 사용하나?
Litte, Big Endian은 장단점이 교차한다
우선 Little-Endian은 캐스팅에 유리하다, 여기서 캐스팅이란 데이터 사이즈가 크게 잡혀있는 데이터를 사이즈를 줄여 작은 데이터로 만드는 과정을 의미한다
ex) b dd 0x12345678에서 1byte만 줄이고 싶다면 0x78만 빼면 된다 이때 첫번째가 0x78인 Little-Endian이 유리하게 되는 것임, Big-Endian은 맨 뒤까지 이동해야 함
하지만 Big-Endian은 숫자 비교에 유리하다
ex) 0x12345678, 0x45123411을 비교할 때 맨 앞에서 부터 비교하게 되는데 Big-Endian은 순차적으로 데이터가 배열되기 때문에 숫자 비교에 유리하다
