Kafka와 같은 메시지 큐를 활용한 비동기 처리는 사용자에게 빠르게 응답을 줄 수 있다는 큰 장점이 있습니다.
비동기 처리는 @Async 로도 구현 가능하잖아?
위와 같은 의문을 가졌었습니다.
맞는 말이에요. 다만, 상황에 따라 목적에 따라 결정하는 부분이라고 생각합니다.
@Async
: 현재 애플리케이션 프로세스 안에서 새로운 스레드를 만들어 비동기적으로 백그라운드 스레드에서 돌아가도록 합니다.
✅ 애플리케이션 내부에서 단순 백그라운드 실행을 해도 될 때 사용하면 됩니다.
❌ 서버 인스턴스가 죽으면 스레드 작업도 같이 날라갑니다.
❌ 스레드풀 한계로 인해 트래픽이 몰리면 병목 발생할 수 있습니다.
❌ 여러 서버 인스턴스에서 작업 순서를 제어하거나 재시도(retry), 보장(delivery guarantee) 같은 로직을 처리하기 어렵습니다.
Kafka
: 단순 "스레드 분리"가 아니라, 생산자(Producer) → 브로커(Kafka 서버) → 소비자(Consumer) 구조로 이루어진 분산 메시징 시스템입니다.
✅ 내구성 & 재시도 보장: Kafka는 디스크에 로그를 저장 → 장애 나도 메시지 유실 X
✅ 수평 확장성: 여러 Consumer 그룹으로 분산 처리 가능
✅ 서비스 간 결합도↓: 발행/구독 구조로, 서비스 간 의존도 낮음
✅ 지속적인 이벤트 스트림 처리 가능 (예: 로그 집계, 실시간 통계 등)
❌ 운영 복잡성 (Kafka 클러스터 운영, 오프셋 관리 등)
❌ 메시지 처리 순서, 중복 처리 등 고려 필요
❌ 트랜잭션 일관성 확보 어려움 (특히 DB 트랜잭션과 분리되므로)
DLT란?
▶️ DLT(Dead Letter Topic)는 오류로 인해 처리할 수 없는 메시지 (재시도(Retry) 조차 실패한 메시지)를 임시로 저장하는 토픽입니다.
DLT를 사용하는 이유는?
- 실패한 메시지를 DLT 토픽에 저장해놓기 때문에, 실패한 메시지가 유실되는 걸 방지할 수 있습니다.
- DLT 토픽에 실패한 메시지가 저장되어 있기 때문에, 사후에 실패 원인을 분석할 수 있습니다.
- DLT 토픽에 실패한 메시지가 저장되어 있기 때문에, 처리되지 못한 메시지를 수동으로 처리할 수 있습니다.
✅ Spring Kafka는
@RetryableTopic를 사용하면 자동으로 DLT 토픽을 생성하고 메시지를 전송해줍니다.
기본 DLT 토픽명:{기존 토픽명}-dlt
DLT에 저장된 메시지를 사후 처리하는 방식
1. DLT에 저장된 실패 메시지를 로그 시스템에 전송해 장애 원인을 추적할 수 있도록 한다.
2. DLT에 메시지가 저장되자마자 수동으로 대처할 수 있게 알림을 설정한다.
3. 알림을 받은 관리자는 로그에 쌓인 내용을 보고 장애 원인을 분석하고, 그에 맞게 메시지를 수동으로 처리한다.여기서 3번째 내용중에 '메시지를 수동으로 처리한다' 부분을 다시 나누면
1. 메시지를 원래 토픽으로 직접 다시 보내기
- 장애가 일시적이었고 지금은 해결된 경우 (ex. 외부 메일 서버가 다운되어 있었는데 지금은 정상 상태인 경우)
2. 메시지 폐기하기
- 메시지의 내용을 처리하려고 봤는데, 영구적으로 처리할 수 없는 메시지(ex. 탈퇴한 사용자, 형식오류)일 수도 있습니다.
그럴 때는 메시지 자체를 폐기합니다. 단, 폐기할 때도 영구적으로 폐기하지 않고 혹시 모를 상황에 대비해 로그로 남겨둡니다.
3. (사후 처리) 잘못된 메시지 내용이 Kafka에 들어가지 않게 Producer의 검증 로직 보완하기
- 잘못된 메시지는 최대한 Producer에서 검증할 수 있으면 검증해서 걸러야 한다. 이렇게 되면 잘못된 메시지가 kafka에 들어가지 않게 되고, 사용자 입장에서도 잘못된 요청 값에 대해 실패의 응답을 받을 수 있기 때문에 대처해야 할 에러가 확연히 줄어듭니다.
파티션(Partition)이란?
▶️ 큐(메시지를 임시로 저장할 수 있는 공간)를 여러개로 늘려서 병렬 처리를 가능하게 하는 기본단위입니다.
파티션의 특징
✅ 토픽을 생성할 때 별도의 옵션을 주지 않으면 파티션은 1개만 생성되고, Producer가 특정 토픽에 메시지를 넣으면 여러 파티션에 메시지가 적절하게 분산됩니다.
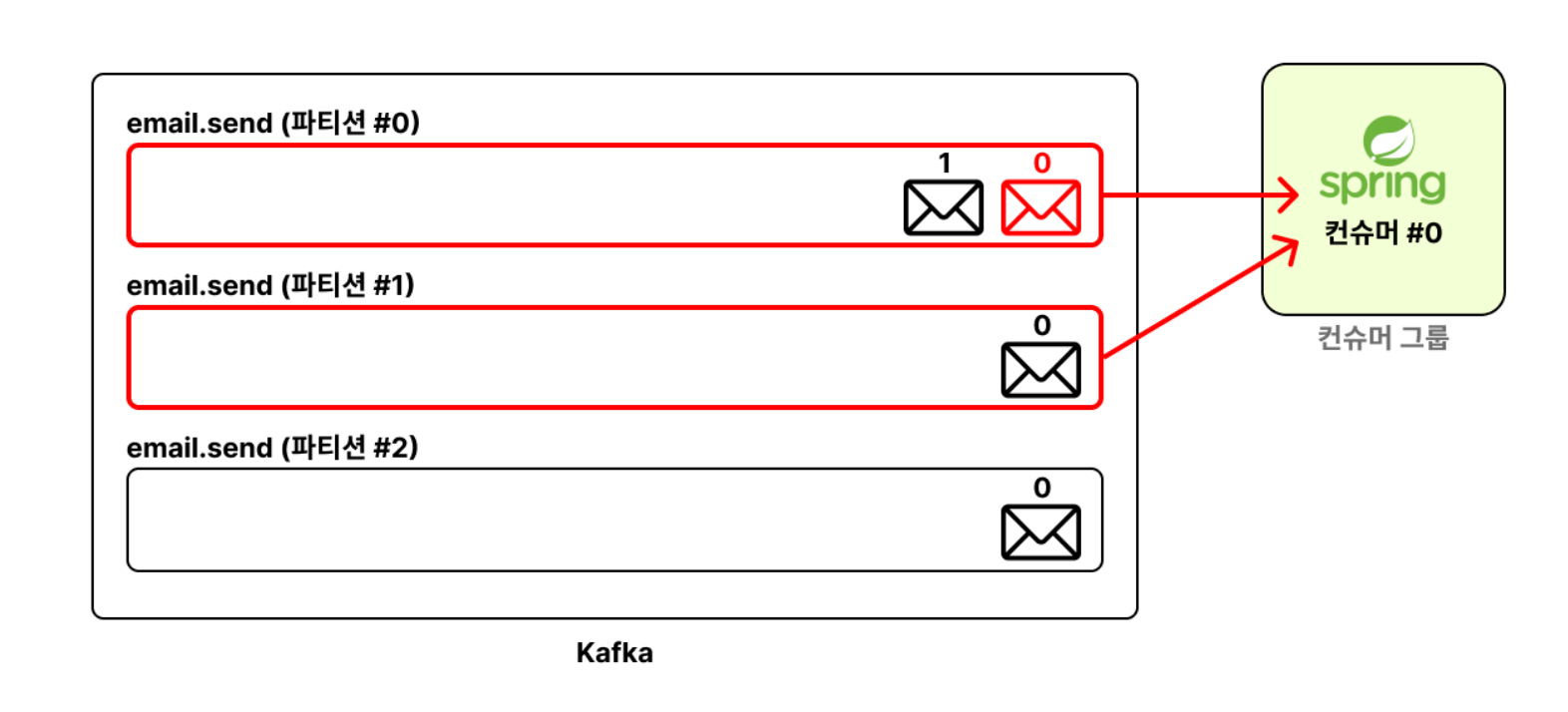
1. 하나의 파티션은 동일한 Cousumer Group 내에서 단 하나의 컨슈머에게만 할당됩니다.
- 여러 컨슈머가 하나의 파티션의 메시지를 같이 처리할 수는 없습니다.
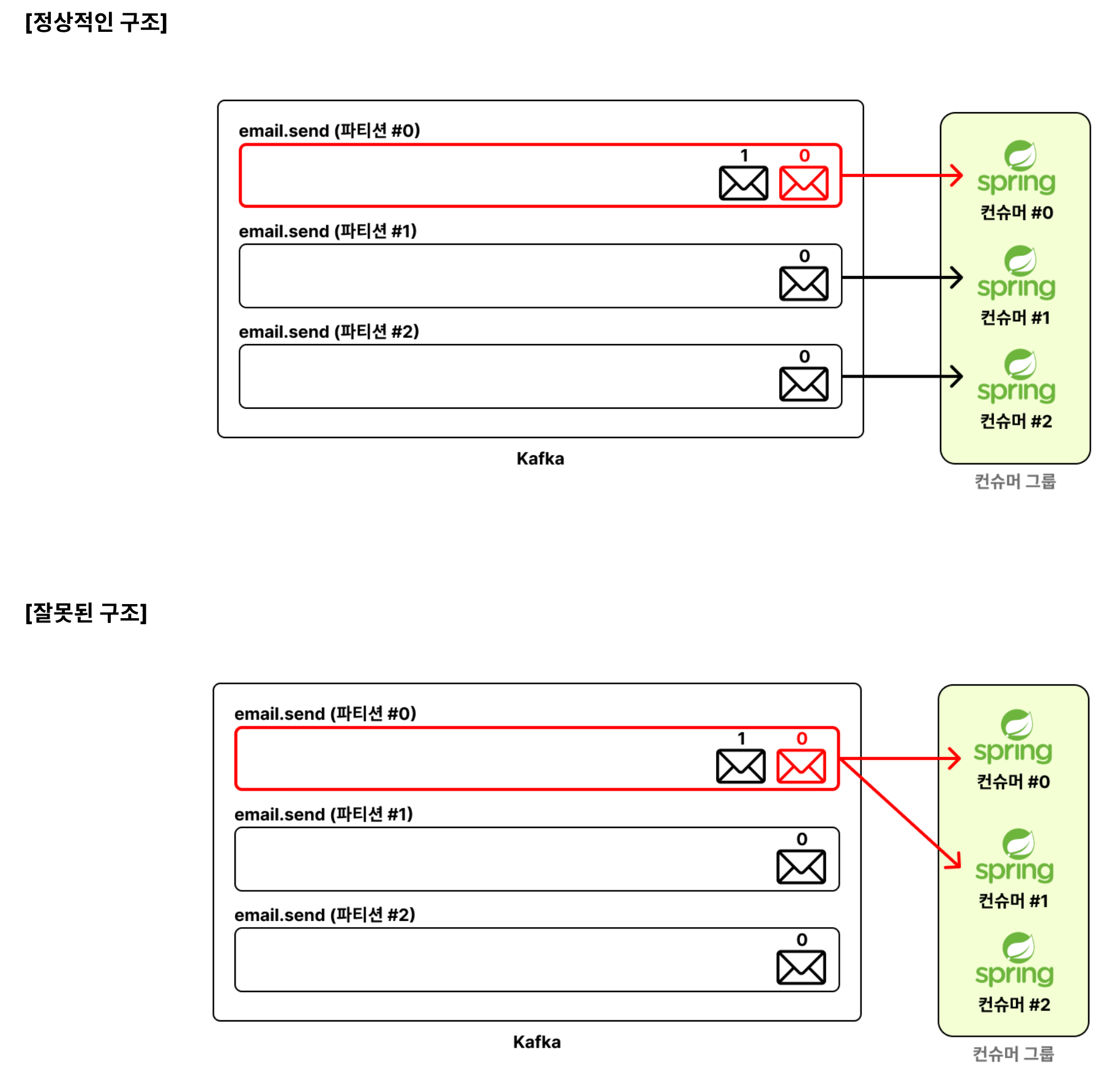
2. 하나의 컨슈머가 여러 파티션을 처리할 수 있습니다.
- 여러 컨슈머가 하나의 파티션의 메시지를 같이 처리할 수는 없지만, 하나의 컨슈머가 여러 파티션을 처리하는건 가능합니다.
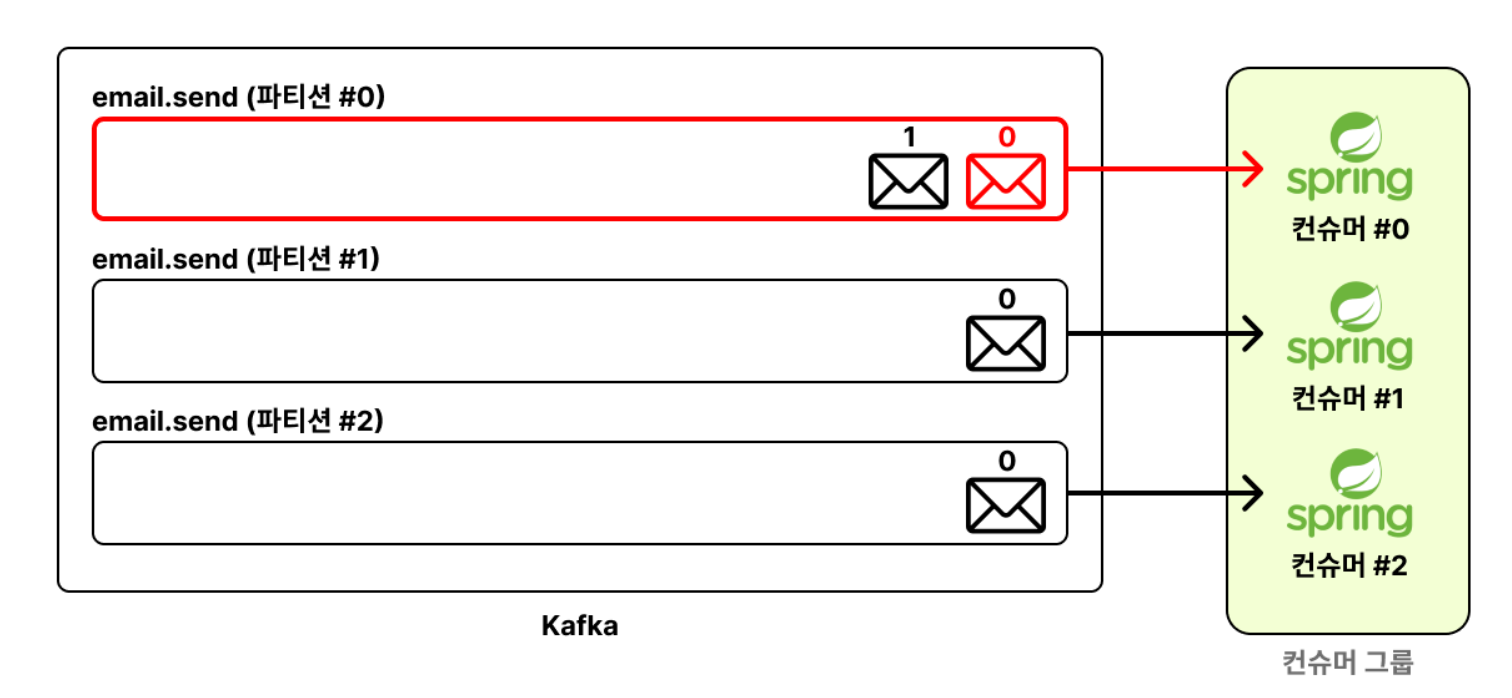
3. 하나의 파티션에 할당된 하나의 컨슈머는 메시지를 순서대로 처리합니다.
- ⭐️
파티션 #0에컨슈머 #0이 할당됐을 때,컨슈머 #0은 오프셋이 0인 메시지를 다 처리하고 난 뒤에 오프셋이 1인 메시지를 처리합니다.
즉, 오프셋이 0인 메시지와 1인 메시지를 병렬적으로 처리하지 않는다는 뜻입니다.
이렇게 처리하는 이유는 파티션 단위로 메시지의 처리 순서를 보장하기 위함입니다.
이 특징 때문에 Spring Boot가 멀티 쓰레드를 기반으로 여러 개의 요청을 처리할 수 있는 구조임에도 불구하고, Consumer가 한 번에 하나씩만 처리하는 것입니다.
특정 토픽의 파티션 수 설정 / 조회 / 변경
설정
// 문법
$ bin/kafka-topics.sh \
--bootstrap-server <kafka 주소> \
--create \
--topic <토픽명> \
--partitions <파티션 수>
// 예제
$ bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create \
--topic test.topic \
--partitions 3조회
$ bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--describe --topic test.topic
PartitionCount: 토픽이 가지고 있는 파티션의 총 개수Partition: 파티션 번호 (0번 부터 시작)
변경
// 문법
$ bin/kafka-topics.sh \
--bootstrap-server <kafka 주소> \
--alter \
--topic <토픽명> \
--partitions <변경할 최종 파티션 수>
// 예제
$ bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--alter \
--topic test.topic \
--partitions 5- --alter 옵션 추가
✅ 파티션을 줄이는 과정은 내부적으로 문제(데이터 손실, 성능 저하 등)가 많이 발생하기 때문에 카프카가 에러를 발생시킵니다.
처음 파티션 수를 설정할 때 신중하게 설정하는 걸 권장합니다.🙏
여러 개의 파티션에 메시지 분배
✅ 특정 토픽에 메시지를 넣을 때, 메시지의 형태에 따라 파티션에 분배되는 방식이 달라집니다.
- key가 포함되지 않은 메시지를 넣을 경우
- 스티키 파티셔닝 방식
- Kafka 2.4 Ver 이전: 라운드 로빈 방식. 하지만 대규모 메시지를 처리할 때는 스티키 파티셔닝 방식이 성능적으로 효율적이었기 때문에 2.4 Ver 이후로는 기본 메시지 분배 방식이 라운드 로빈 방식에서 스티키 파티셔닝 방식으로 변경되었습니다.
- key가 포함된 메시지를 넣을 경우
- key의 해시 값을 기반으로 파티션을 결정해서 메시지를 분배합니다. 그래서 같은 key 값을 가진 메시지는 같은 파티션에 들어갑니다.
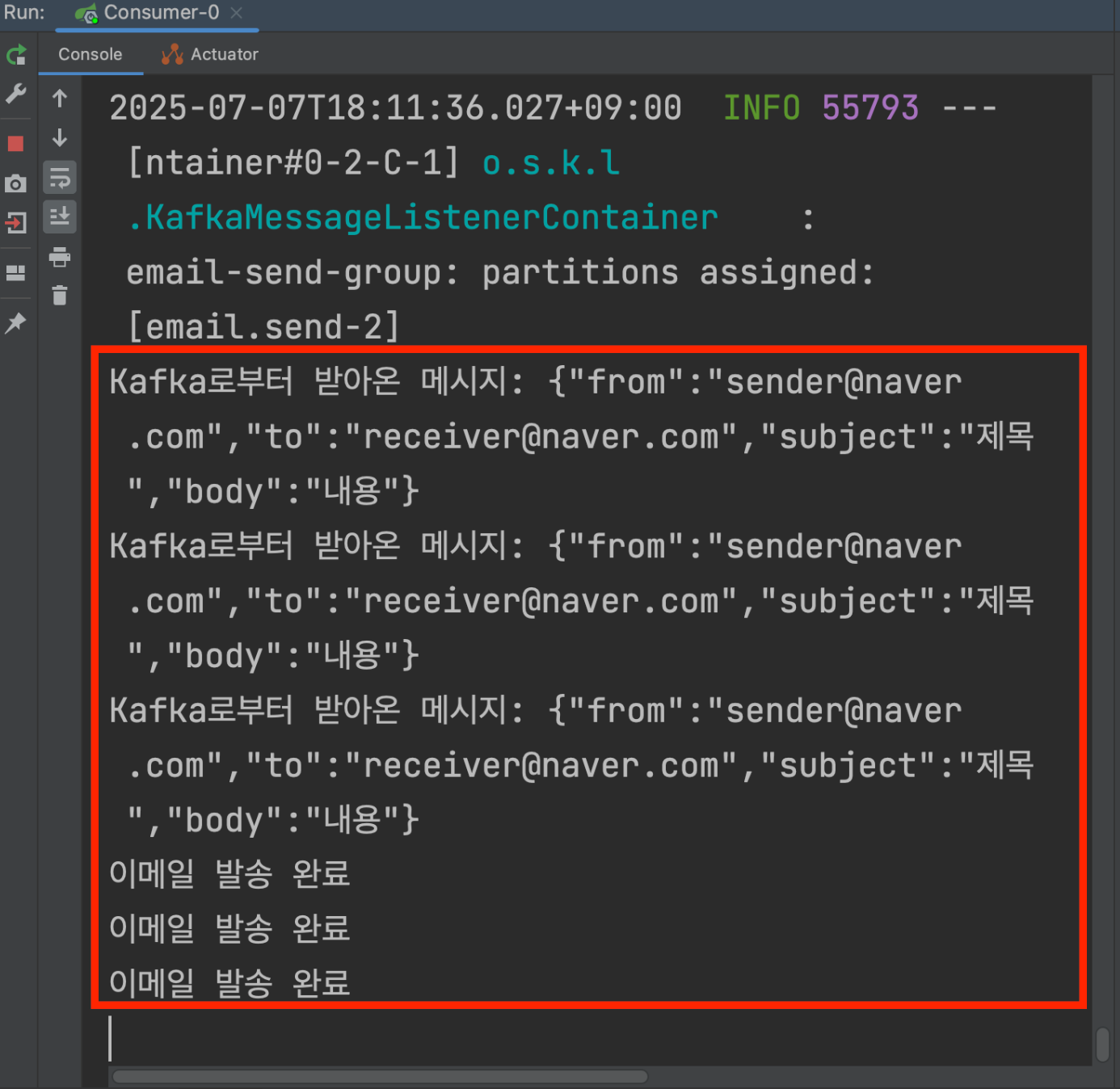
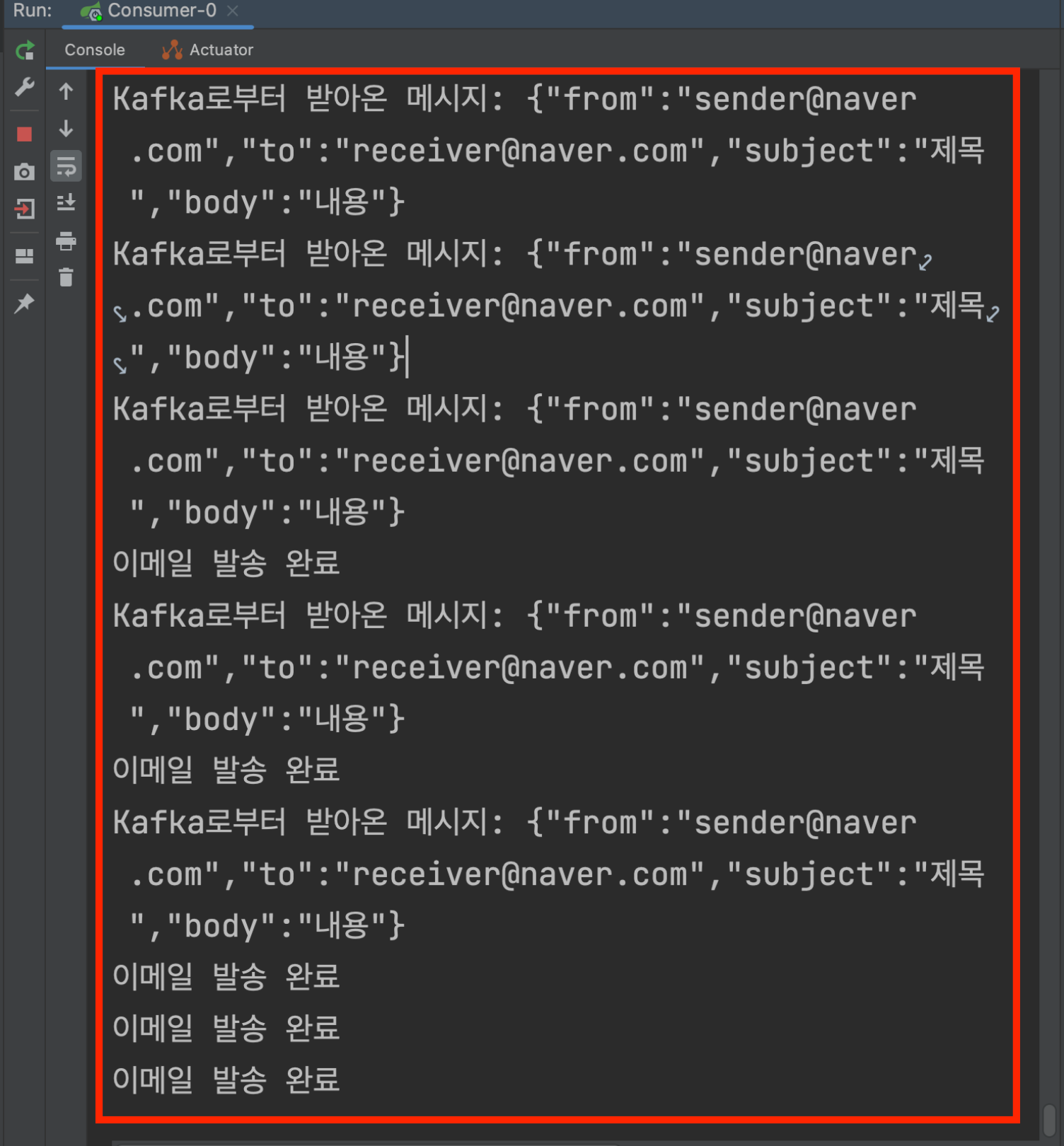
하나의 컨슈머로 메시지 병렬적으로 처리하기
✅ 코드
✅ 그림
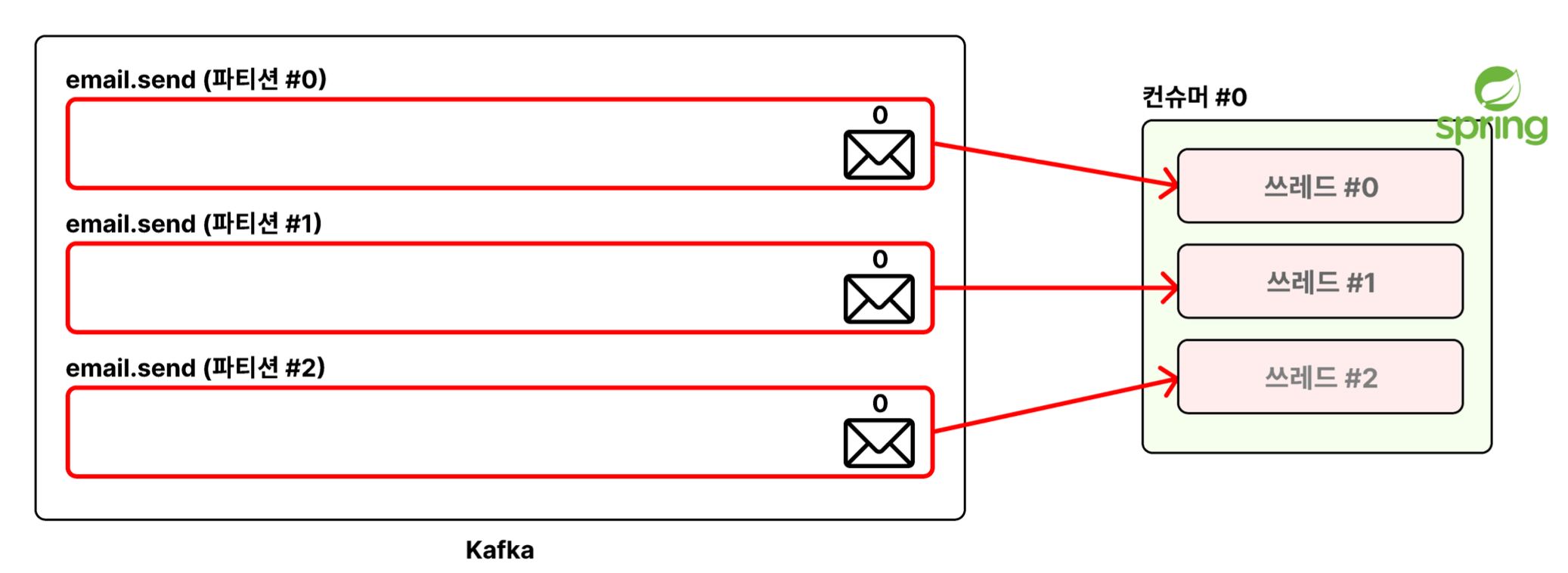
💡 ex 1: API 요청을 연속으로 3번 보냈을 경우
Spring Boot 서버에서 총 3개의 쓰레드가 파티션을 하나씩 담당해서 처리하는 방식으로 작동
💡 ex 2: API 요청을 연속으로 5번 보냈을 경우
3개의 메시지까지는 바로 컨슈머 서버가 받아들이지만, 그 다음 2개의 메시지는 각 파티션의 이전 메시지가 처리되는 대로 받아들입니다. 그 이유는 해당 토픽의 파티션이 3개이기 때문에 여러 쓰레드가 병렬적으로 처리할 수 있는 메시지의 개수가 최대 3개일 수 밖에 없기 때문입니다.
Lag 이란?
▶️ 카프카에서 사용하는 랙의 의미는 지연된 메시지 수(컨슈머가 아직 처리하지 못한 메시지 수)입니다. 컨슈머 랙(Consumer Lag)이라고도 부릅니다.
컨슈머 랙은 언제 발생할까?

1초에 메시지가 3개씩 전송되는데 1초에 메시지를 1개씩 밖에 처리를 하지 못한다면, 1초 당 2개의 메시지가 계속해서 쌓일것입니다.
사용자들 입장에서 요청을 보낸 내용이 처리되지 않아 서비스에 버그가 생겼다고 생각할 것입니다.
빠르게 조치하려면 컨슈머 랙을 지속적으로 모니터링 할 수 있어야 합니다.
현업에서 컨슈머 랙 체크 방법
1. 외부 모니터링 툴 사용하기
외부 모니터링 툴을 사용해서 컨슈머 랙(Conusmer Lag)을 지속적으로 모니터링하면서, 특정 케이스에 대해 알림을 발송하게 만들어서 빠르게 대처할 수 있게 셋팅하는 편입니다.
많이 사용하는 외부 모니터링 툴로는 이런 것들이 있습니다.
- Datadog (유료)
- Burrow (무료 오픈소스)
- Prometheus, Grafana (무료 오픈소스)
2. 매니지드 서비스(Managed Service)에서 제공하는 모니터링 기능 사용하기
현업에서는 카프카를 직접 구축해서 사용하지 않고, 클라우드의 카프카 서비스를 사용하는 경우도 많다. 대표적인 서비스로 AWS MSK와
Confluent Cloud가 있습니다. 이 서비스를 사용하면 자체적으로 컨슈머 랙(Consumer Lag)에 대한 모니터링 기능을 같이 제공하는 경우가
많습니다.
노드(node), 클러스터(cluster), 브로커(broker), 컨트롤러(controller), 레플리케이션(replication) 용어정리
⭐️ Kafka의 고가용성(시스템이 장애 상황에서도 멈추지 않고 정상적으로 서비스를 제공할 수 있는 능력)을 확보하는 방법을 이해하려면 해당 용어들을 알고있어야 합니다.
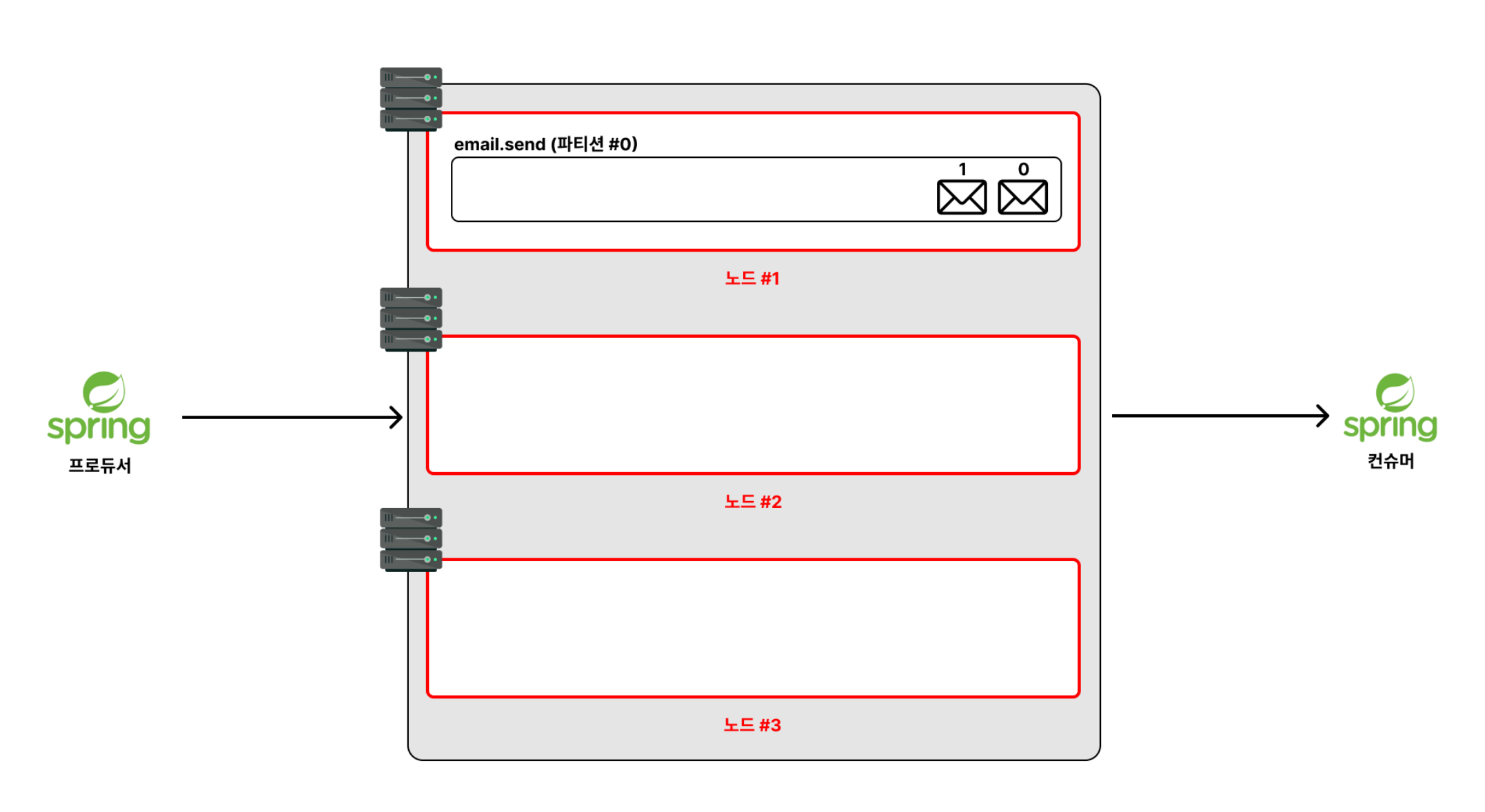
✅ 노드(node)란?
▶️ 카프카가 설치되어 있는 서버 단위
💡 서비스 장애를 방지하기 위해 실무에서는 위 그림과 같이 노드(node)를 1대만 두지 않고, 최소 3대의 노드(node)를 구성합니다. 즉, 최소 카프카 서버 3대를 구축해서 운용한다는 뜻입니다.
✅ 클러스터(cluster)란?
▶️ 여러 대의 서버가 연결되어 하나의 시스템처럼 동작하는 서버들의 집합
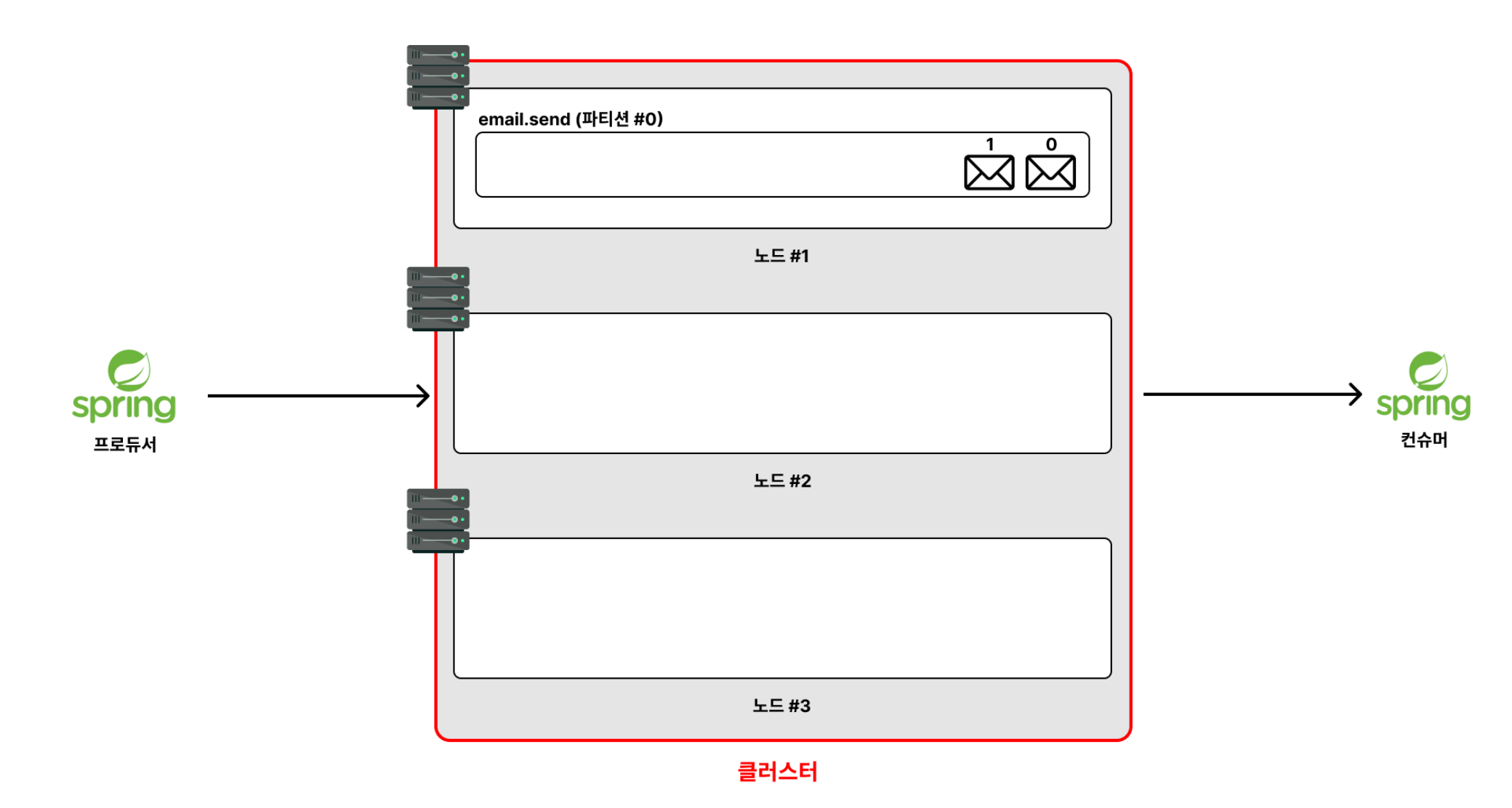
예를 들면, 서로 들어오는 메시지를 나눠 저장하고, 서로의 복제본을 생성해서 유지할 수도 있으며, 장애 시 시스템 전체가 중단없이 작동되게 만듭니다. 이와 같이 유기적으로 작동하는 노드들을 묶어서 클러스터(cluster)라고 부릅니다.
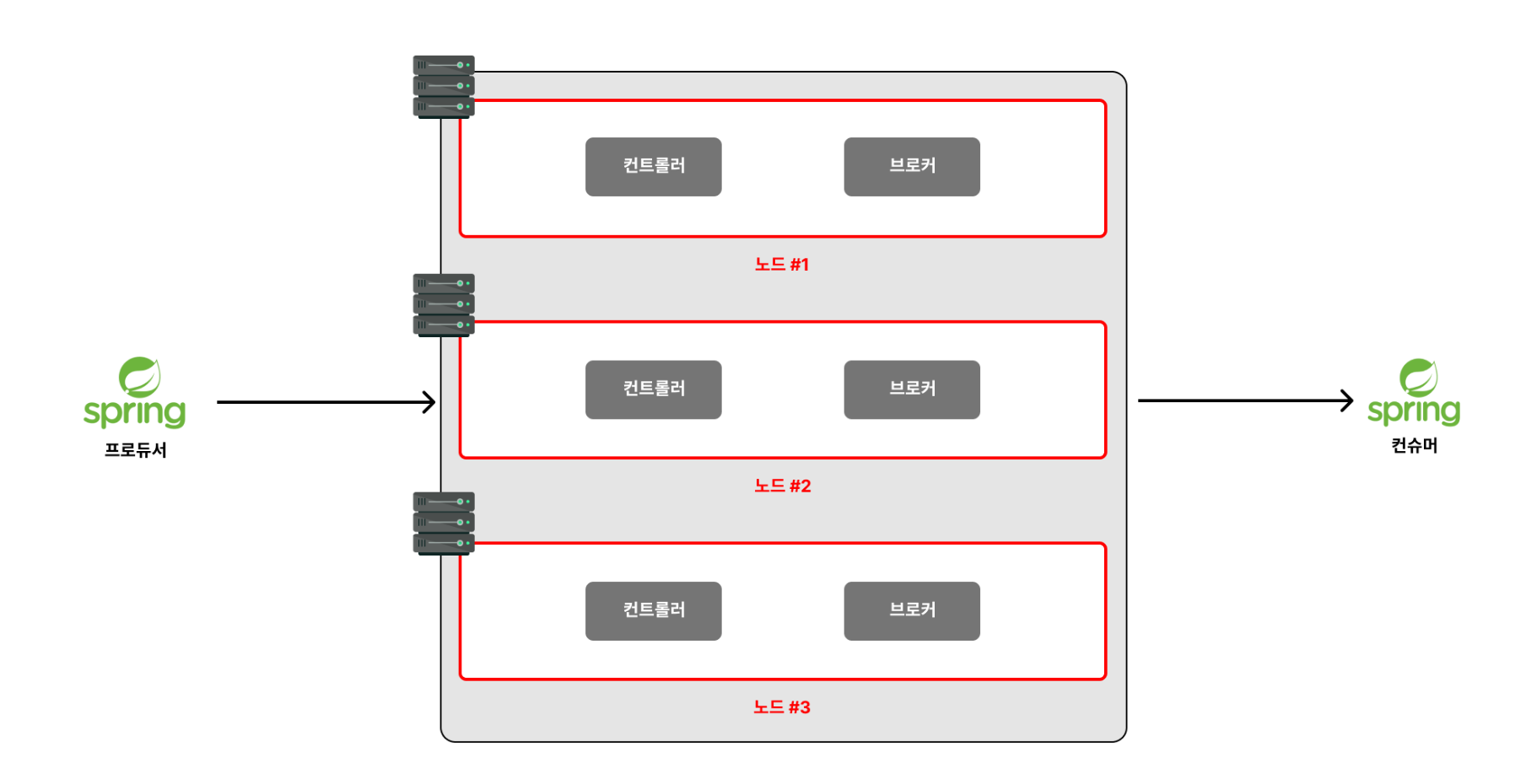
✅ 컨트롤러(controller), 브로커(broker)란?
💡
Kafka 서버는 크게 컨트롤러와 브로커로 구성되어 있으며, 기본적으로 kafka 노드에서 브로커는 9092 포트, 컨트롤러는 9093 포트에서 별개의 프로세스로 실행됩니다.
▶️ 컨트롤러: 브로커들간의 연동과 전반적인 클러스터의 상태를 총괄합니다.(총관리자)
▶️ 브로커: 메시지를 저장하고 클라이언트의 요청을 처리하는 역할을 합니다.(직원)
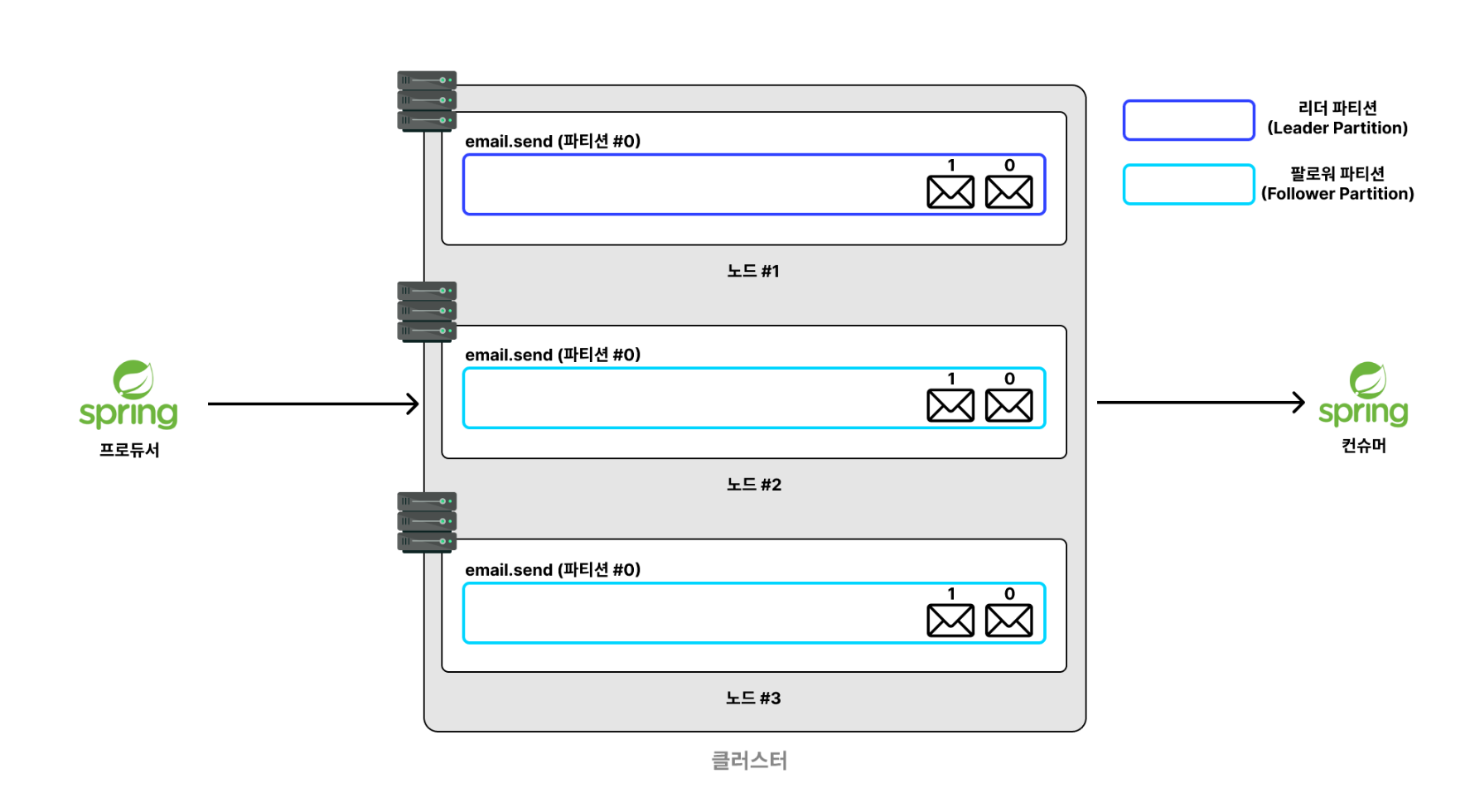
✅ 레플리케이션(replication)이란?
▶️ 데이터의 안정성과 가용성을 높이기 위해
토픽의 파티션을 여러 노드에 복제하는 걸 의미합니다.
- 레플리케이션 설정을 하면 email.send 의 파티션 #0 을 다른 노드에도 복사해서 저장해둡니다.
- 복제된 파티션들은
리더 파티션(원본)과팔로워 파티션(복제본)으로 구분됩니다.리더 파티션은 프로듀서나 컨슈머가 직접적으로 메시지를 읽고 쓰는 파티션입니다. 반면에팔로워 파티션은 프로듀서나 컨슈머가 직접적으로 메시지를 일고 쓰지 않습니다.팔로워 파티션은리더 파티션의 메시지를 실시간으로 복제하며 유지합니다.리더 파티션에 장애가 발생하면팔로워 파티션이 리더 역할(프로듀서로부터 메시지를 받고, 컨슈머가 메시지를 처리)을 대신 수행합니다. 이미팔로워 파티션은리더 파티션내부에 있는 메시지까지 복제해서 가지고 있기 때문에,리더 파티션의 노드가 중간에 장애가 난다고 하더라도 메시지는 정상적으로 이어서 처리할 수 있습니다.
- 레플리케이션 개수는 kafka 서버 수만큼 설정할 수 있지만, ⭐️ 실무에서는 레플리케이션 개수를 2나 3으로 설정해서 활용하는 편입니다.
Kafka 서버 총 3대 셋팅하기
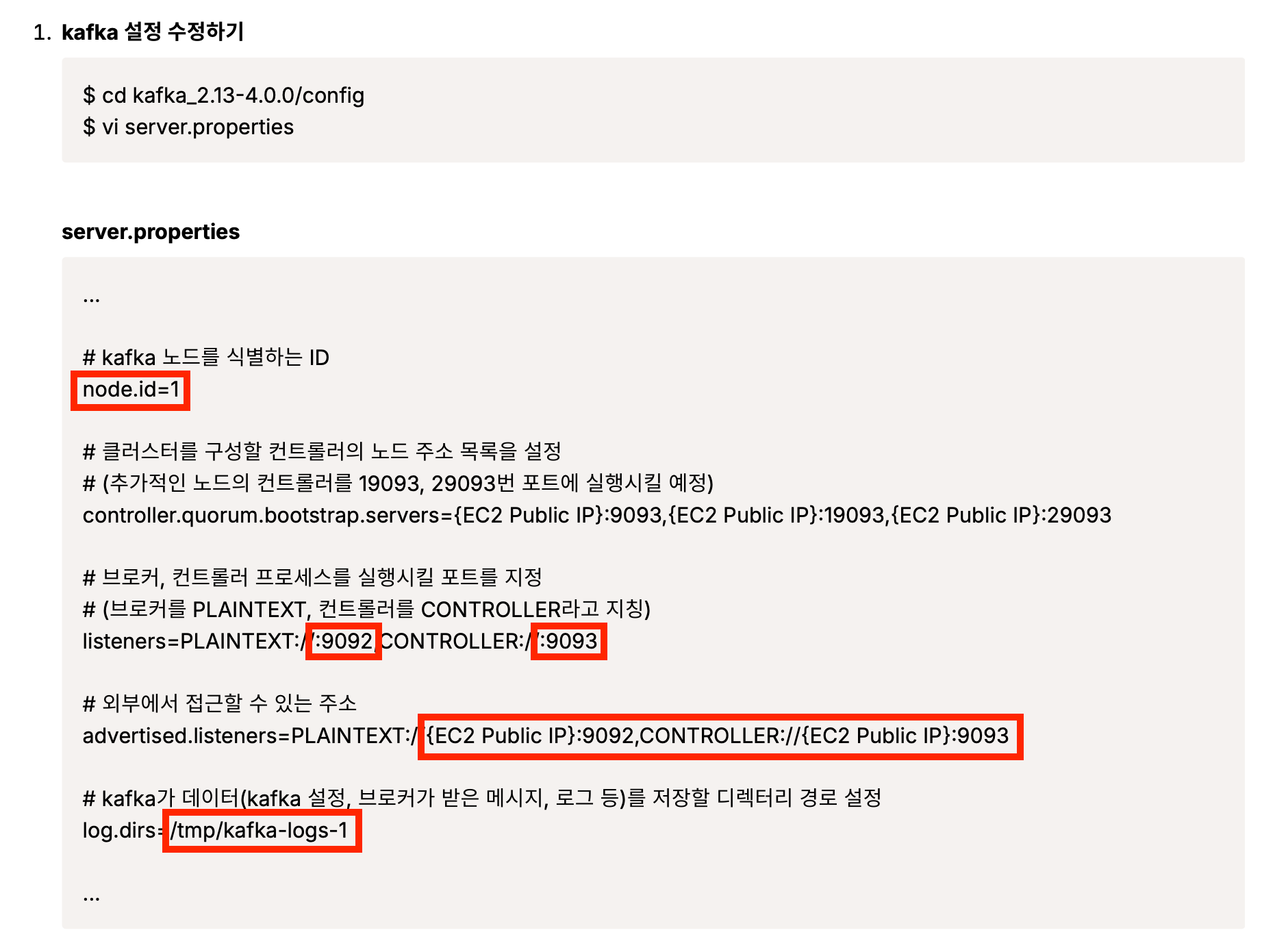
첫 노드는 클러스터를 초기화하고, 나머지 노드는 해당 클러스터에 연결하기
cd .. # kafka 디렉터리로 이동
# kafka 종료하기
$ bin/kafka-server-stop.sh
# 처음 실행하는 kafka 노드는 아래 명령어로 실행
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
$ KAFKA_CONTROLLER_ID="$(bin/kafka-storage.sh random-uuid)"
$ bin/kafka-storage.sh format \
-t $KAFKA_CLUSTER_ID \
-c config/server.properties \
--initial-controllers "1@localhost:9093:$KAFKA_CONTROLLER_ID"
# 추가로 연동시킬 kafka 노드는 아래 명령어로 실행
# 주의 : server.properties가 아니라 server2.properties를 사용해야 한다.
$ bin/kafka-storage.sh format \
-t $KAFKA_CLUSTER_ID \
-c config/server2.properties \
--no-initial-controllers
# 추가로 연동시킬 kafka 노드는 아래 명령어로 실행
# 주의 : server.properties가 아니라 server3.properties를 사용해야 한다.
$ bin/kafka-storage.sh format \
-t $KAFKA_CLUSTER_ID \
-c config/server3.properties \
--no-initial-controllerskafka 노드 3대 전부 실행하기
$ bin/kafka-server-start.sh config/server.properties
$ bin/kafka-server-start.sh config/server2.properties
$ bin/kafka-server-start.sh config/server3.propertieskafka 노드 3대가 전부 잘 실행됐는 지 확인하기
# kafka 노드들의 브로커 실행 확인
$ lsof -i:9092 # 노드 1의 브로커
$ lsof -i:19092 # 노드 2의 브로커
$ lsof -i:29092 # 노드 3의 브로커
# kafka 노드들의 컨트롤러 실행 확인
$ lsof -i:9093 # 노드 1의 컨트롤러
$ lsof -i:19093 # 노드 2의 컨트롤러
$ lsof -i:29093 # 노드 3의 컨트롤러클러스터에 컨트롤러 등록하기
$ bin/kafka-metadata-quorum.sh \
--command-config config/server2.properties \
--bootstrap-server localhost:9092 \
add-controller
$ bin/kafka-metadata-quorum.sh \
--command-config config/server3.properties \
--bootstrap-server localhost:9092 \
add-controller컨트롤러끼리 잘 연동됐는 지 확인하기
$ bin/kafka-metadata-quorum.sh \
--bootstrap-server localhost:9092 describe \
--status
위 명렁어를 입력했을 대 CurrentVoters에 3개의 컨트롤러 정보가 찍히면 클러스터에 3개의 컨트롤러가 정상적으로 잘 등록된 것입니다.
💡 참고: 위 코드는 학습의 편의를 위해 각각의 EC2 인스턴스 kafka 노드를 따로따로 설치한 것이 아닌, 하나의 서버에 3개의 kafka 노드를 한꺼번에 셋팅한 코드입니다.
토픽 생성하기 (+ 레플리케이션 생성)
$ bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create \
--topic email.send \
--partitions 1 \
--replication-factor 3
# 토픽 세부 정보 조회하기
$ bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--describe \
--topic email.send
Replicas와 Isr에 3개의 숫자(1, 2, 3)가 다 있다면 3개의 Kafka 서버가 정상적으로 잘 연동되고 있다는 뜻입니다.
토픽 세부 정보 출력값 정보 해석하기 (Isr, Leader, Replicas 등)

- PartitionCount : 해당 토픽의 파티션 수
- ReplicationFactor : 해당 토픽의 레플리케이션 수
- Partition : 파티션 번호
- Leader : 해당 토픽의 리더 파티션을 가지고 있는 노드 id
- Replicas : 해당 토픽의 파티션을 복제하기로 설정된 노드들의 id
- Isr(In-Sync Replicas) : 리더 파티션과 똑같은 상태로 복제(동기화)가 완료된 노드들의 id
팔로워 파티션에 메시지를 넣으면 어떻게 될까?
리더 파티션은 프로듀서나 컨슈머가 직접적으로 메시지를 쓰고 읽는 파티션, 팔로워 파티션은 프로듀서나 컨슈머가 직접적으로 메시지를 쓰고 읽지 않는다고 하였습니다.
그러나 팔로워 파티션에 메시지를 넣어도 정상 동작합니다.!
💡 그 이유는?
Kafka 프로듀서는 메시지를 보내기 전에 해당 파티션의 리더가 누구인지 확인하고, 자동으로 리더 파티션에 메시지를 전송해줍니다. 이게 가능한 이유는 kafka 노드들끼리 서로 연동되어 있어서, 리더 파티션을 가진 kafka 노드가 누군지에 대한 정보를 주고 받을 수 있기 때문입니다.
리더 파티션에 장애가 발생하면 어떻게 될까? / Kafka 서버 1대가 고장나면 어떻게 될까?

- 1번 노드가 장애가 발생했다고 가정하고 토픽 세부정보를 조회해보니
Leader리더 파티션이 2로 바뀌었습니다. 즉, 리더 파티션에 장애가 발생해서 팔로워 파티션이 리더 역할을 대신 수행하게끔 승격되었습니다. Isr1번 노드가 빠졌다는 것은 1번 노드의 네트워크가 끊겼거나, 서버에 장애가 생겼거나, 아직 리더 파티션의 데이터와 동기화 되지 않았다는 뜻입니다.
Kafka 서버는 몇 대를 운용하는게 좋을까?
kafka 서버를 많이 운용할수록 시스템 전체가 중단될 확률이 줄어들기 때문에 좋기는 하나, 많은 서버를 운용하게 되면 서버 비용이 많이 나옵니다.
그리고 kafka 서버를 1대로 운용한다고 해서 서비스를 아예 운영하지 못할 정도의 치명적인 장애가 발생하는 건 아닙니다. 따라서 아래 지침을 통해 kafka 서버 개수를 정하는 걸 추천합니다.
1. 초기 스타트업, 초기 단계 서비스, 개발/테스트 단계
- 추천 kafka 서버 수 : 1대
- 비용 절감이 중요한 단계이므로, 최소 구성으로 시작하고 추후 트래픽 증가나 장애 이슈가 발생할 때 점진적으로 확장하는 전략을 추천합니다.
- 서비스의 안정성이 중요한 중견 기업 또는 대기업
- 추천 kafka 서버 수: 최소 3대 이상
- 서비스에 장애가 나는 게 회사에 더 큰 손실이 생기는 단계입니다. 이 때는 서버 비용이 크게 부담이 안되는 경우가 많아, 서비스 장애가 최대한 발생하지 않도록 더 신경을 써야합니다.
이 링크를 통해 구매하시면 제가 수익을 받을 수 있어요. 🤗
출처: https://inf.run/wQkoW
