자료구조를 공부하다가 해시 테이블에 대해 살펴보던 중, 문득 이런 생각이 들었다.
자바스크립트에는 해시 테이블이라는 자료구조가 명시적으로 없는데... 그럼
Map이 해시테이블인가 ? 만약 그렇다면, 해시충돌은 어떻게 처리할까?
그래서 직접 V8 엔진의 소스코드를 분석해보며 Map객체의 내부 동작 방식과 해시 충돌 처리 방식에 대해 알아보았다.
이 글은 V8 엔진의 내부 구현을 중심으로, 자바스크립트에서의 해시 테이블 구조와 해시 충돌 처리 전략에 대해 정리한다.
❗ 이 글은 2025년 4월 기준으로 작성되었으며 V8의 내부 구현은 언제든 바뀔 수 있다.
0️⃣ 몇 가지 사전 지식
본격적으로 V8엔진을 분석하기 전에, V8엔진과 해시테이블에 대해 간단히 정리해보려고 한다.
1. V8엔진이란 ?
V8은 구글이 개발한 자바스크립트 엔진이다. 자바스크립트 런타임 환경인 Chrome 브라우저와 Node.js 모두 V8엔진 위에서 동작한다.
내부가 C++로 구현되어 있기 때문에 코드는 C++코드를 분석할 예정이다.
2. 해시, 해시함수, 해시테이블
- 해시
- 어떤 값을 특정한 규칙으로 변환한 결과값
- 해시 함수
- 어떤 값을 해시값으로 변환해주는 함수
- 내부에서 구현된 특정한 규칙에 따라 입력값을 해시값으로 변환한다.
- 예시)
SHA-256등
- 해시 테이블
- 해시 함수를 사용해
키-값형태로 데이터를 저장하는 자료구조 - 해시 함수를 통해 조회하므로 빠르다.
- 해시 함수를 사용해
- 해시 충돌
- 서로 다른 두 값이 같은 해시값을 가지는 것
function hash(k){ return k % 10; } hash(20) === hash(30) // 해시충돌 발생 ⚠️
- 서로 다른 두 값이 같은 해시값을 가지는 것
- 해시 충돌 해결방법
- 개방 주소법 (Open Addressing): 충돌 발생 시 빈 공간을 찾아 순차적으로 저장
- 체이닝 (Chaining): 하나의 버킷에 여러 값을 연결 리스트 형태로 저장
💡 간단한 비교를 통해 이해해보자
- 해시 : 학생의 학번
- 해시함수 : 학생의 학번을 정하는 규칙
- 해시테이블 : 학번을 기준으로 학생 정보를 빠르게 찾을 수 있도록 구성된 시스템
1️⃣ 해시테이블로 만들어진 맵
JavaScript는 Map, Set, WeakMap, WeakSet총 네가지 컬렉션이 존재하는데, 이 중 Map을 기준으로 V8 엔진 내부를 살펴보자
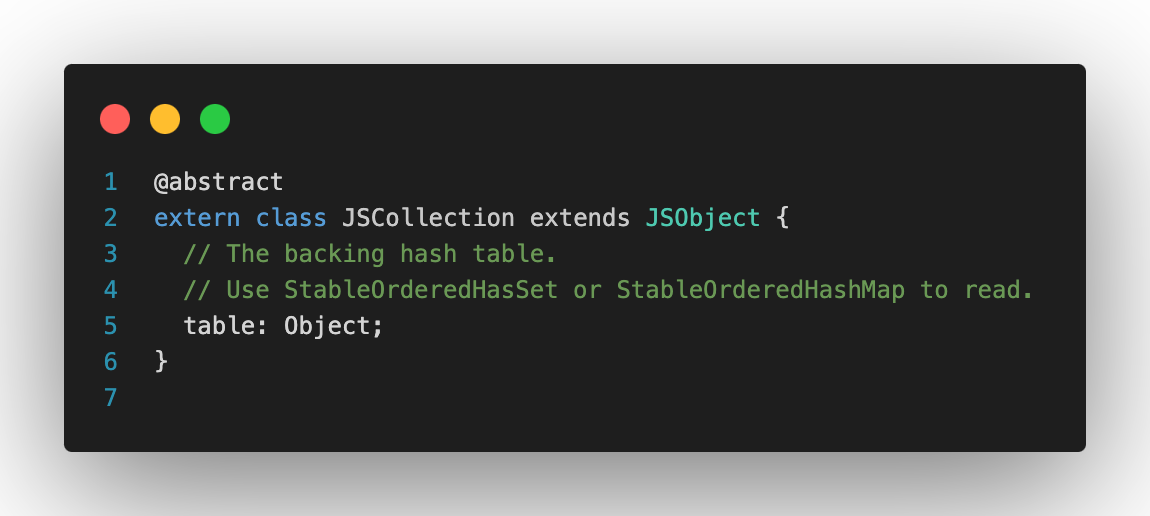
위 코드는 V8에서 사용하는 DSL인 Torque로 작성된 JSMap클래스의 선언부다.
JSMap은 JSCollection을 상속받으며, JSCollection은 내부적으로 table을 필드로 가진다. 이 table이 실제 데이터를 저장하는 해시테이블이다.
그렇다면 Map이 해시 테이블을 사용한다는 것은 어디에서 확인할 수 있을까 ?
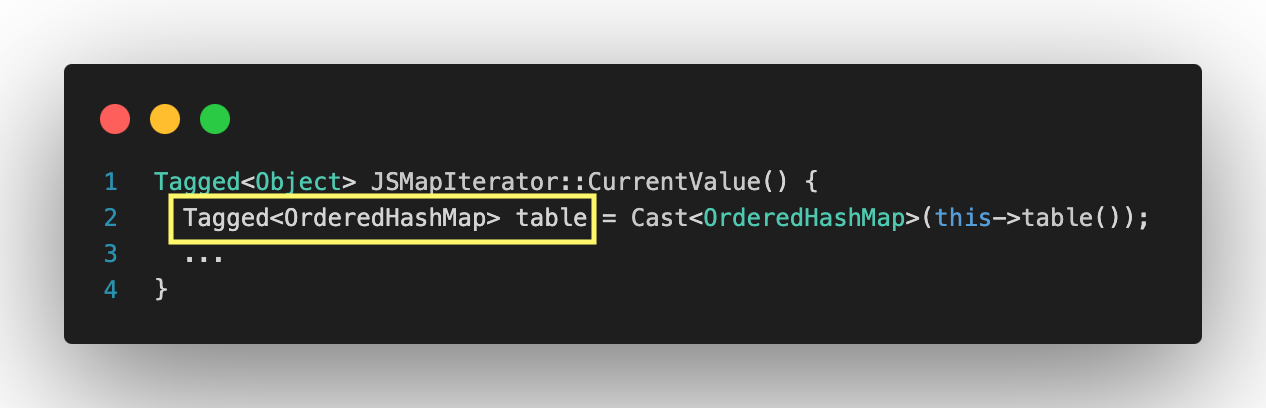
아까 Torque로 작성된 JSMap의 선언부에서, table은 Object 타입으로 선언되어 있었지만 실제 구현에서는 OrderedHashMap으로 캐스팅된다. 이는 JSMap이 내부적으로 OrderedHashMap를 사용해 table을 다룬다는 것을 의미한다.
📌 정리하자면
- JS의
Map객체는 V8 내부적으로JSMap클래스에 대응된다. - 이
JSMap은JSCollection을 상속하며,table이라는 필드에 데이터를 저장한다. - 이
table은 실제로OrderedHashMap타입으로 처리되며, 해시 테이블 구조를 사용한다.
2️⃣ 해시테이블 메모리 구조
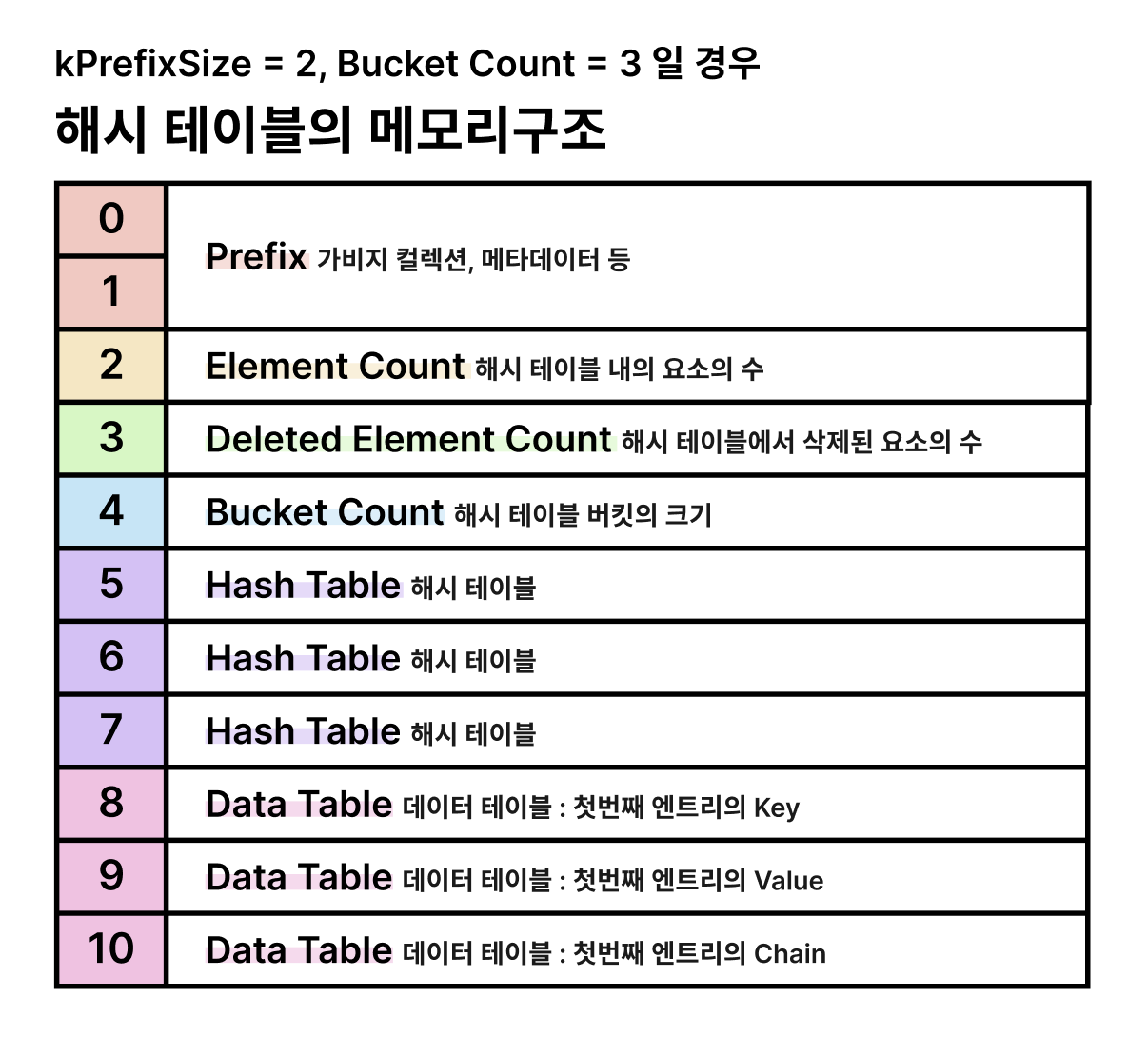
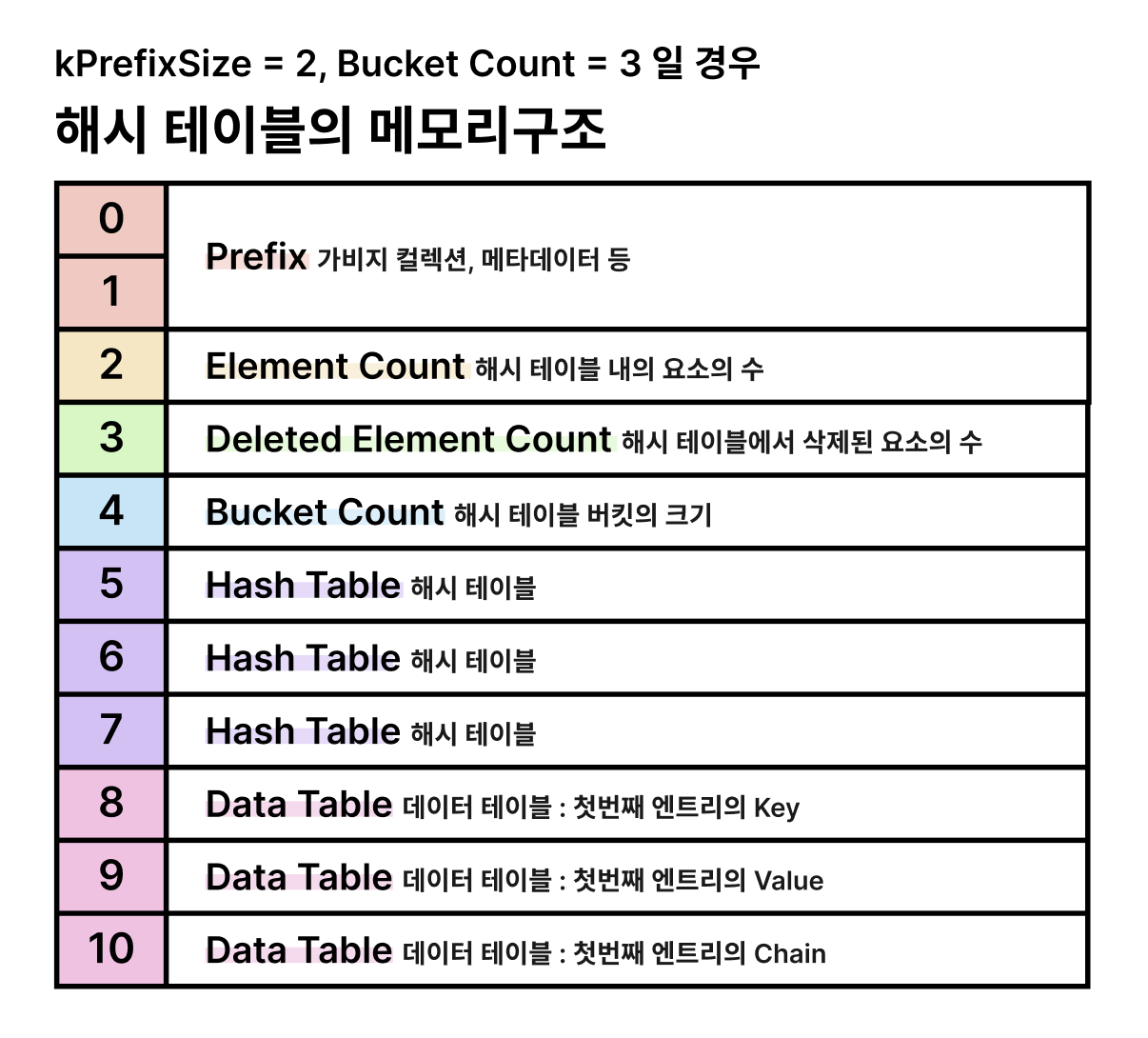
위 그림은 V8 소스코드의 주석을 기반으로 해시테이블의 메모리 구조를 시각화한 것이다.
그림에서는 11칸만 표현되었지만, 실제 메모리에서는 해시테이블의 전체 용량만큼 공간을 차지한다.
각 요소를 하나씩 살펴보자
Prefix: 해시테이블 자체의 메타데이터나 가비지 컬렉션에 사용되는 내부 정보를 저장하며,kPrefixSize만큼의 고정된 크기를 갖는다.Element Count: 현재 테이블에 저장된 요소 수Deleted Element Count: 테이블에서 삭제된 요소 수Bucket Count: 해시 테이블의 버킷 개수를 나타내며, 해시값을 어떤 버킷에 저장할지 결정하는 데 사용된다.Hash Table: 실제 해시테이블. 버킷마다 연결된 체인의 시작점을 나타낸다.Data Table: 엔트리(실제 데이터)가 저장되는 데이터 테이블이다. 참고로 그림은 10번 인덱스까지 표현되지만, 실제로는 해시테이블 용량의 끝까지 차지한다.
각 엔트리는 [key, value, next] 형식으로 구성되어 있으며, 이 세 개의 슬롯이 연속된 메모리 공간에 플랫하게 저장된다. V8의 해시테이블은 체이닝 방식으로 연결 리스트를 구성하여 해시 충돌을 처리한다.
요소를 추가하고 삭제할 때, V8엔진이 어떤 방식으로 해시 충돌을 처리하는지 살펴보자
3️⃣ 해시테이블 요소 추가(충돌 해결)
다음은 OrderedHashMap::Add함수의 내부 동작을 분석한 것이다. 이 함수는 새로운 키-값 쌍을 해시테이블에 추가한다.
키 중복 확인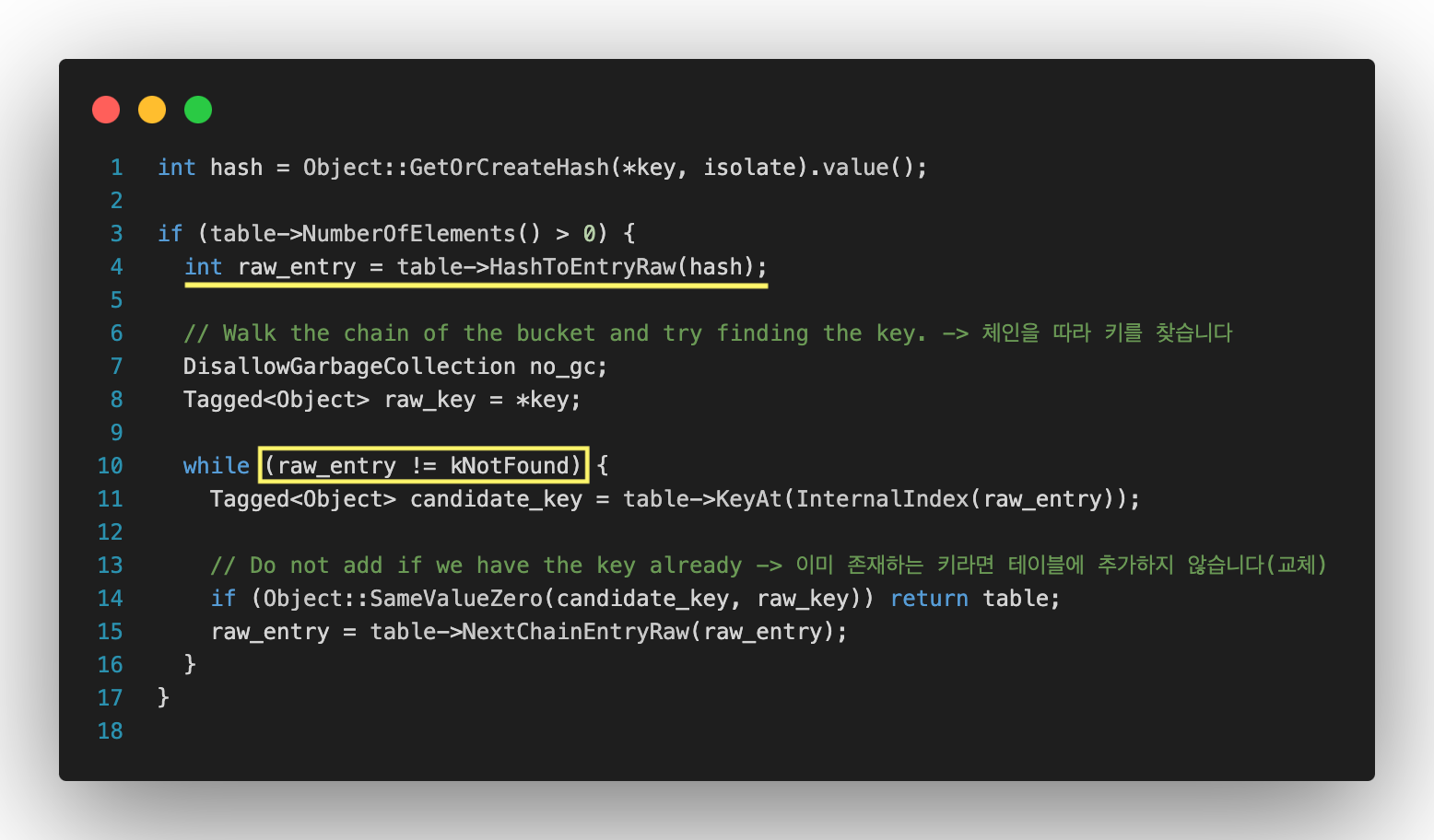
키 값을 해시 값으로 변환한 뒤, 해당 해시값을 가진 엔트리가 이미 존재하는지 확인한다. 만약 테이블 요소 수가 0이라면 중복 확인할 필요가 없으므로 조건을 걸어 최적화한다.
동일한 해시값을 가진 키들은 체이닝 방식으로 연결되어 있기 때문에, 이를 따라가며 SameValueZero로 실제 키와 비교하여 중복 여부를 확인한다.
중복일 경우 키를 추가하지 않고 종료한다.
테이블 용량 확보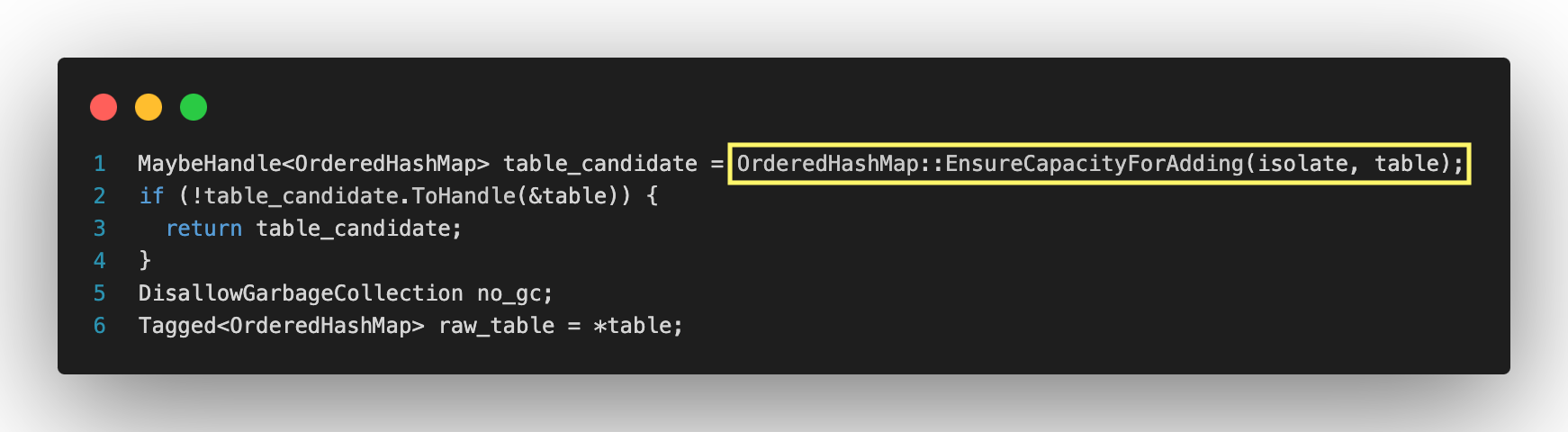
새로운 엔트리를 추가하기 전에, EnsureCapacityForAdding 함수를 통해 테이블의 용량이 충분한지 확인하고, 부족할 경우 리사이징을 수행한다. 후술할 예정이지만 V8은 테이블의 용량을 조절하며 최적화를 수행한다.
새로운 엔트리 추가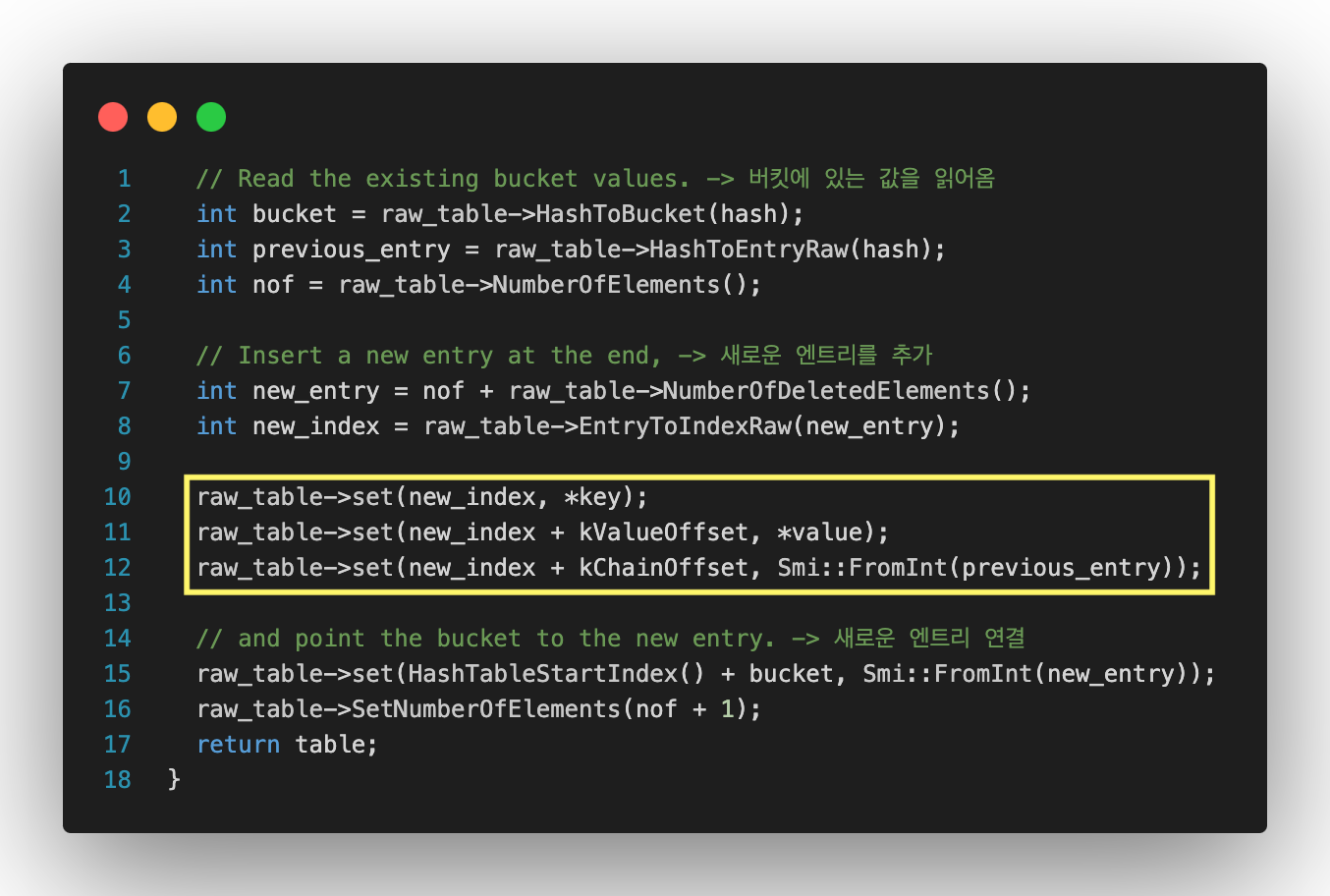
새로운 엔트리를 추가하는 로직이다. 해시값 기반으로 어느 버킷에 넣을 지 결정한 뒤, 해당 버킷에 이미 엔트리가 있다면, 그 엔트리의 인덱스를 가져온다. 가져온 인덱스를 통해 테이블에 있는 요소의 개수(nof) + 삭제된 요소의 개수와 새로운 엔트리 위치(인덱스)를 계산한다.
그 후, new_index 위치에 [key, value, next]형태로 엔트리를 추가한다. 주목할 점은 새로운 엔트리의 체이닝에 이전 엔트리의 인덱스 값을 추가한다는 점이다.
다음 줄을 보면 버킷에 새로운 엔트리를 연결하는데 이 말은 HashTable 영역에 맨 처음 추가된 엔트리가 아닌 가장 마지막에 추가된 엔트리가 들어간다는 의미이다. 즉 선입후출(LIFO) 구조로 데이터를 추가한다.
마지막으로 전체 요소 개수를 증가시키고, 테이블을 반환하며 엔트리 추가 작업을 마무리한다.
4️⃣ 해시테이블 요소 삭제
다음은 OrderedHashTable::Delete 함수의 내부 동작을 분석한 것이다. 이 함수는 V8의 OrderedHashMap 또는 OrderedHashSet에서 특정 키를 삭제할 때 호출되는 함수이다. 핵심은 값을 제거하는 것이 아니라 '비었다'는 표시를 남기는 것에 있다.
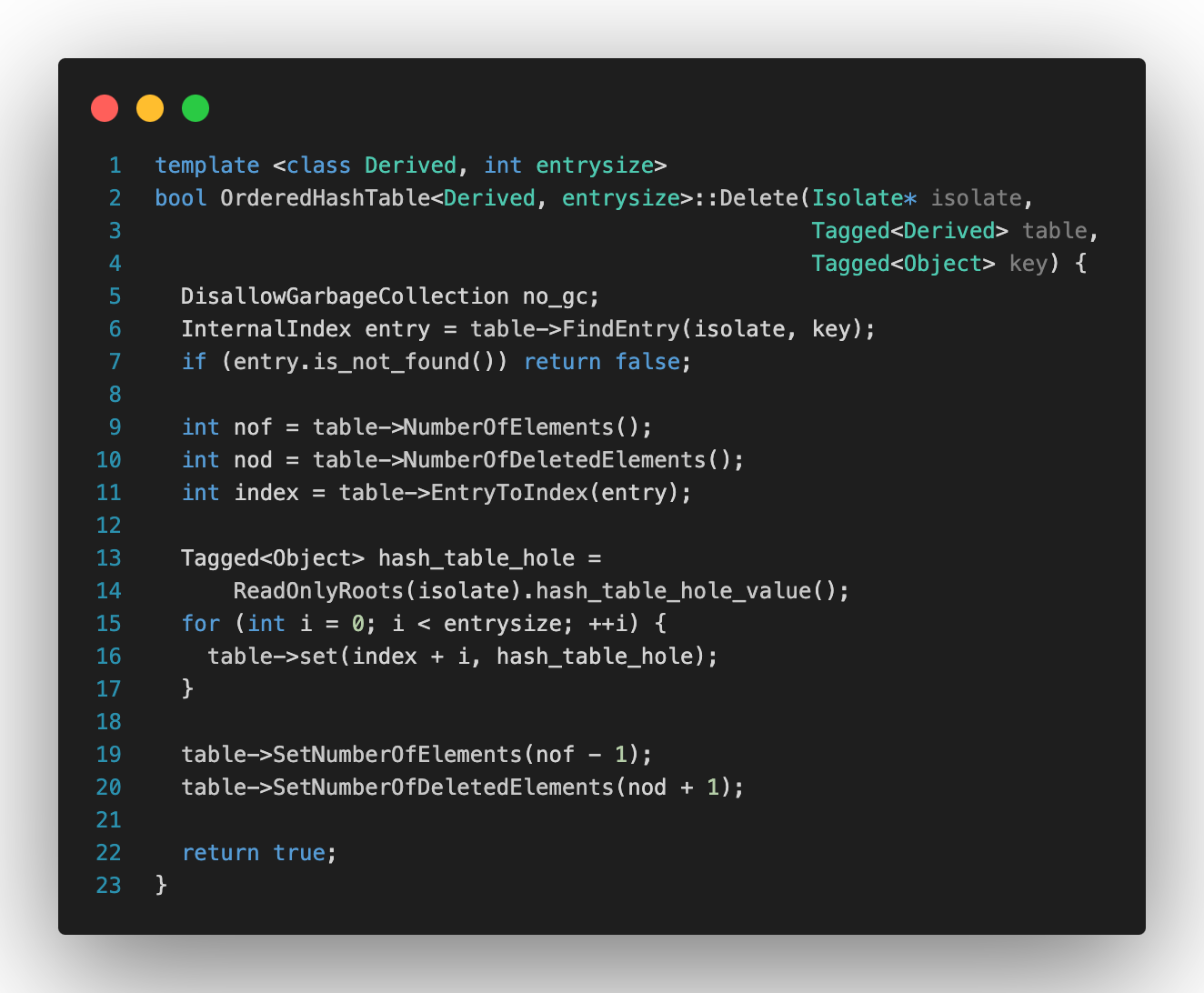
FindEntry()를 통해 해당 키가 존재하는지 확인한다. 없으면 바로 false 리턴한다.
EntryToIndex() 를 통해 실제 메모리상의 위치를 받아온 뒤, 메모리 위치부터 entrysize만큼 반복하며 hash_table_hole이라는 특수 값으로 비었음을 표시한다. (이 때 entrysize는 Map인지, Set인지에 따라 달라진다. Map은 key, value, chain으로 구성되어 entrysize가 3이고, Set은 key, chain만 있어 entrysize가 2다.)
위 과정을 마치면 유효한 요소 수인 NumberOfElements는 감소시키고, 삭제된 요소 수 NumberOfDeletedElements는 증가시킨다.
이러한 방식을 통해 삭제된 공간을 추적하면서도 기존의 해시테이블 체인 구조를 유지할 수 있게 된다.
5️⃣ 해시테이블 최적화
해시테이블 구조를 분석하며 알게된 V8 엔진의 해시테이블 최적화방식을 알아보자. V8의 OrderedHashTable은 컬렉션을 효율적으로 구현하기 위해 다양한 최적화 기법을 사용한다. 요소를 추가하거나 삭제할 때, 테이블 용량을 줄이거나 늘리면서 메모리를 효율적으로 관리하고, 해시 충돌이 발생할 가능성을 최소화한다.
SmallOrderedHashTable : 미니 해시 테이블
SmallOrderedHashTable은 V8에서 작은 용량의 해시테이블을 효율적으로 처리하기 위해 만들어진 가벼운 해시테이블 구조다. 일반 해시테이블과 달리 바이트 단위로 데이터를 저장해 메모리 사용량을 최소화하고, 가비지 컬렉션의 부하를 줄인다. 엔트리 수가 적고 구조가 단순하기 때문에 탐색 속도도 최적화되어 있어, 자주 생성되고 폐기되는 임시 객체나 작은 맵을 처리할 때 유리하다.
EnsureCapacityForAdding : 용량 확보 (자세한 코드 분석 보기)
V8엔진은 해시테이블에 새로운 요소를 추가하기 전에 EnsureCapacityForAdding함수를 통해 용량이 충분한지 검사한다. 아래의 조건에 따라 동작한다.
nof + nod < capacity- 현재 요소 수 + 삭제된 요소 수 < 테이블 총 용량
- 이 경우,
Rehash할 필요가 없어 테이블을 그대로 리턴한다.
capacity == 0- 비어 있는 해시테이블에 처음으로 엔트리를 삽입할 때, 최소 크기(
kInitialCapacity)로 테이블을 생성한다.
- 비어 있는 해시테이블에 처음으로 엔트리를 삽입할 때, 최소 크기(
nod >= (capacity >> 1)- 삭제된 엔트리가 너무 많은 경우,
Rehash를 수행하면 삭제된 공간을 재사용 할 수 있기 때문에 기존 용량을 유지한다.
- 삭제된 엔트리가 너무 많은 경우,
- 그 외
- 용량이 부족하므로 2배로 늘려
Rehash를 수행한다.
- 용량이 부족하므로 2배로 늘려
Rehash - 재배치 (자세한 코드 분석 보기)
V8엔진은 Rehash는 요소 추가나 삭제가 많아 해시 분포가 비효율적으로 바뀌엇을 때 새로운 테이블을 생성하고 기존 엔트리를 옮기는 함수다. 용량이 부족하거나, 삭제 된 요소가 많아 테이블을 정리해야 할 때, 내부 요소가 적어 용량을 줄일 때 수행된다.
동작 과정은 아래와 같다.
- 새로운 버킷 수 (
new_capacity)만큼 새로운 테이블을 할당 및 초기화 - 기존 해시 테이블 엔트리를 순회하면서 삭제된 엔트리는 건너뛰고, 유효한 엔트리만 복사
- 체인 헤드를 갱신
- 요소 개수, 삭제 인덱스 동기화
- 기존 테이블에 새로 만들어진 테이블을 연결
Shrink : 테이블 축소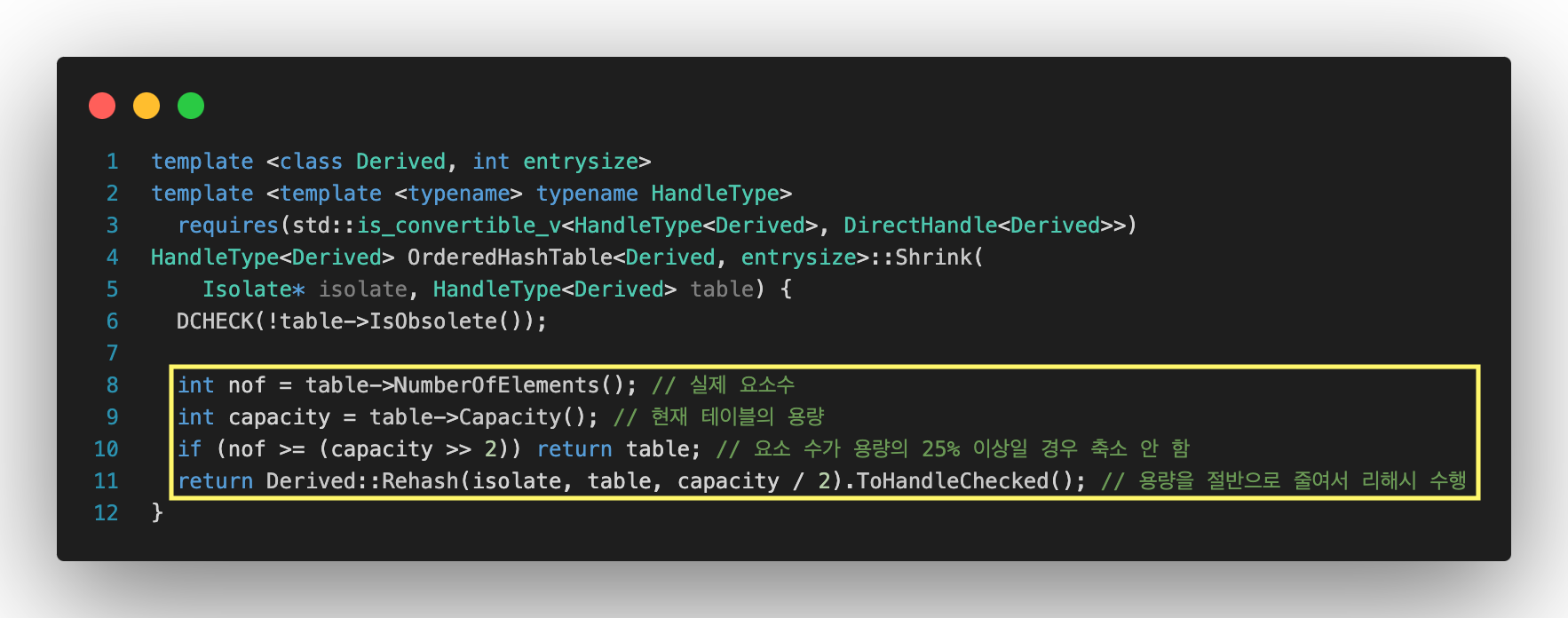
Shrink는 테이블의 크기를 축소하는 함수다. 요소 수가 현재 용량의 25% 미만일 때, 테이블의 용량을 절반으로 줄여 메모리 공간을 더 효율적으로 활용하고, 이를 위해 Rehash를 호출해 더 작은 새 테이블을 생성하고 기존 데이터를 옮긴다.
📌 결론
- 자바스크립트의 컬렉션은
JSCollection을 상속하며, 데이터를 저장하는table필드는OrderedHashTable을 사용한 해시 테이블 구조로 처리된다. - 해시테이블은
FixedArray형태로 구현되어 체이닝 방식으로 연결 리스트를 구성하여 해시 충돌을 해결한다. - V8 엔진은 요소를 추가하거나 삭제할 때, 테이블 용량을 조절하며 메모리를 효율적으로 관리하고, 해시 충돌이 발생할 가능성을 최소화한다.
🚀 느낀점
- C++ 코드를 보느라 눈알이 빠지는 줄 알았다. 하지만 해시테이블 구조를 깊이 이해하는 데 정말 큰 도움이 되었다. 나중에 간단한 버전으로 구현해 볼 예정이다.
- 알고리즘 풀 때를 제외하고 비트연산의 실사용을 직접 눈으로 확인할 수 있어서 진~짜 흥미로웠다.
- 테이블 축소용
Shrink는 별도로 존재하면서 확장용 함수는 왜 따로 없을까 ? 어차피Rehash로 확장을 수행하는거면 축소도Rehash로 해도 될 것 같은데.. - 위의 의문에 대한 GPT의 답변 : 두 함수는 트리거 되는 시점이 다르고 목적이 다르다.
EnsureCapacityForAdding: 요소를 추가하기 전 트리거되며, 초기화나 용량확대가 목적Shrink: 요소를 삭제한 후 트리거되며 용량축소가 목적
