FlutterKaigi 2025 참가 세션 정리

느낀점
- 상상 이상으로 Flutter에 관심을 가지고 있는 회사/사람이 많았다.
- 역시 1년은 초보다. 전문 검색을 구현하기 위해 강의에서만 본 FFI를 활용해 Rust 코드를 Dart까지 끌어오는 테크닉에 경외심이 들었다. Rust -> Native Code -> Dart였는데 아직도 이해가 잘 안된다..
- Flutter 만지자마자 설렜다. 주변 스태프분들에게 열심히 내년 개발에 참여하고 싶다고 어필했는데 참여가능하면 좋겠다.
- 최근 회사 적응 + 업무량으로 인해 개발을 거의 놓다싶이 했는데 다시 동기부여가 되었다.
- 언어는 문제를 해결하기 위한 툴이라는걸 다시 한번 상기시켜주는 컨퍼런스였다. 문제 정의, 해결을 위한 to-do 정의, 각각의 to-do를 해결해주는 패키지/코드/언어의 특징 조사, 이후 적용. 이 순서를 유념하면서 일을 하면 생산성이 올라가지 않을까.
들었던 세션
- The Flutter Effect (Lucas Goldner)
- Hands on
- ユーザーのアクションを伴うWidgetのGoldenTest (유저의 액션에 따르는 Widget의 GoldenTest)
- Flutterアプリ運用の現場で役立った監視Tips 5選 (Flutter 어플 운용의 현장에서 도움이 되었던 감시 Tips 5선)
- モバイル端末で動くLLMはどこまで実用的なのか (모바일 단말에서 움직이는 LLM은 어디까지 실용적인가)
- オフライン対応!Flutterアプリに全文検索エンジンを実装する (온라인 대응! Flutter 어플로 전문 검색 엔진을 탑재하다)
The Flutter Effect (KeyNote)
- 게임을 하다가 작동방식을 궁금하게 되어 유니티 입문
- 이후 스타트업, 모바일 어플 개발 등을 경험하다가 플러터 입문
- 직장에서 지역 플러터 컨퍼런스가 있다는 소식을 듣고 참여했다가 여러 기술을 알게 되었고 다양한 이야기 및 여러가지 매력에 빠지게 됨
- 이후 기회가 되어 FlutterCon(?)에서 강연자가 됨
- 그렇게 GDE(Google Developer Experts) 한분을 만나게 됨
- 우연히 다른 컨퍼런스에서도 만나게 되었고, GDE가 되기 위한 추천을 받아 2개의 테스트를 볼 수 있게됨
- 합격! GDE가 되었습니다!
- '나비효과처럼 작은 행동이 GDE까지 이어지게 되었습니다.'
개발 기술과 관련된 내용은 아니었지만 이 강의로 열심히 다양한 활동을 해서 주도적으로 기회를 늘려야겠다는 생각을 하게 되었다.
Hands on
- 독서 동기를 높여주는 Flutter Application의 UI를 더 예쁘게 만들어보는 핸즈온
- 기본적으로 코드가 이미 주석처리로 작성되어 있고 주석 처리를 해제해가며 적용해보는 방식 (handson_document.md)
- 달성률에 따른 축하 UI를 여러 layer로 분리해 하나씩 층층히 쌓아가며 구현 (배경, 원 그래프 + 메세지, 컨페티)
unawaited(Future 안기다림), CustomPainter를 통한 원형 파문 그리기, 이전 데이터에서 새로운 데이터로 값 이동을 도와주는 Tween 위젯 등을 알게 되었다
ユーザーのアクションを伴うWidgetのGoldenTest (유저의 액션에 따르는 Widget의 GoldenTest)
- GoldenTest
- 어느 시점의 코드로 렌더링된 UI의 화면을 기대화면으로서 사진으로 저장해두고, 실제 렌더링 결과와 비교를 행하는 테스트.
- 비교해서 차이가 있으면 Test 실패 판정.
- (ex:기대화면의 가운데 텍스트가 100인데 실제 가운데 텍스트가 0이면 Test 실패)
- VRT:(Visual Regression Testing): 시각적 회귀 테스트로서 이용됨
목적
- 의도하지 않은 UI의 변경을 막기
- 의도한건 사진을 재 랜더링해서 Commit
- 의도하지 않은 것은 (저장해둔)화면이 변경되지 않았기 때문에 Test실패
- 코드의 변경에 따른 UI의 영향을 가시화
- PR의 코드를 실행하지않고 어떤 UI가 변경되었는지 파악 가능
testWidgets('HomePage VRT', (WidgetTester tester) async {
// 描画
await tester.pumpWidget(
MaterialApp(
theme: ThemeData(fontFamily: 'NotoSans'),
home: const MyHomePage(title: 'title'),
),
);
// 確認
await expectLater(
find.byType(MyHomePage),
matchesGoldenFile('goldens/my_home_page.png'),
);
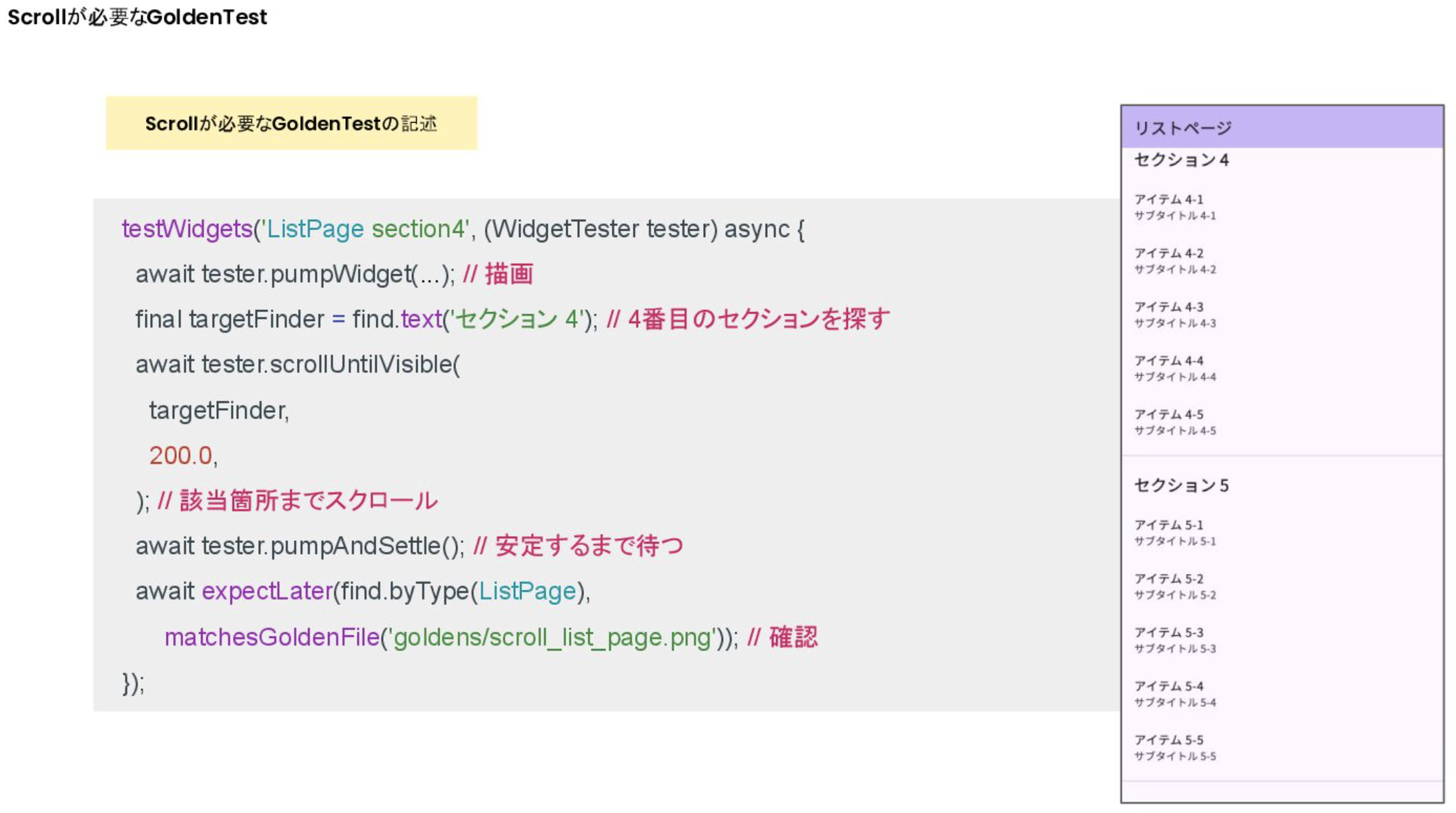
});Scroll이 필요한 GoldenTest 흐름
- 위젯을 그림
- Finder에 스크롤하는 위젯의 검색조건을 설정
- 해당조건을 만족할때까지 스크롤
- Golden화면과 확인
Scroll이 필요한 GoldenTest 실패 (1)
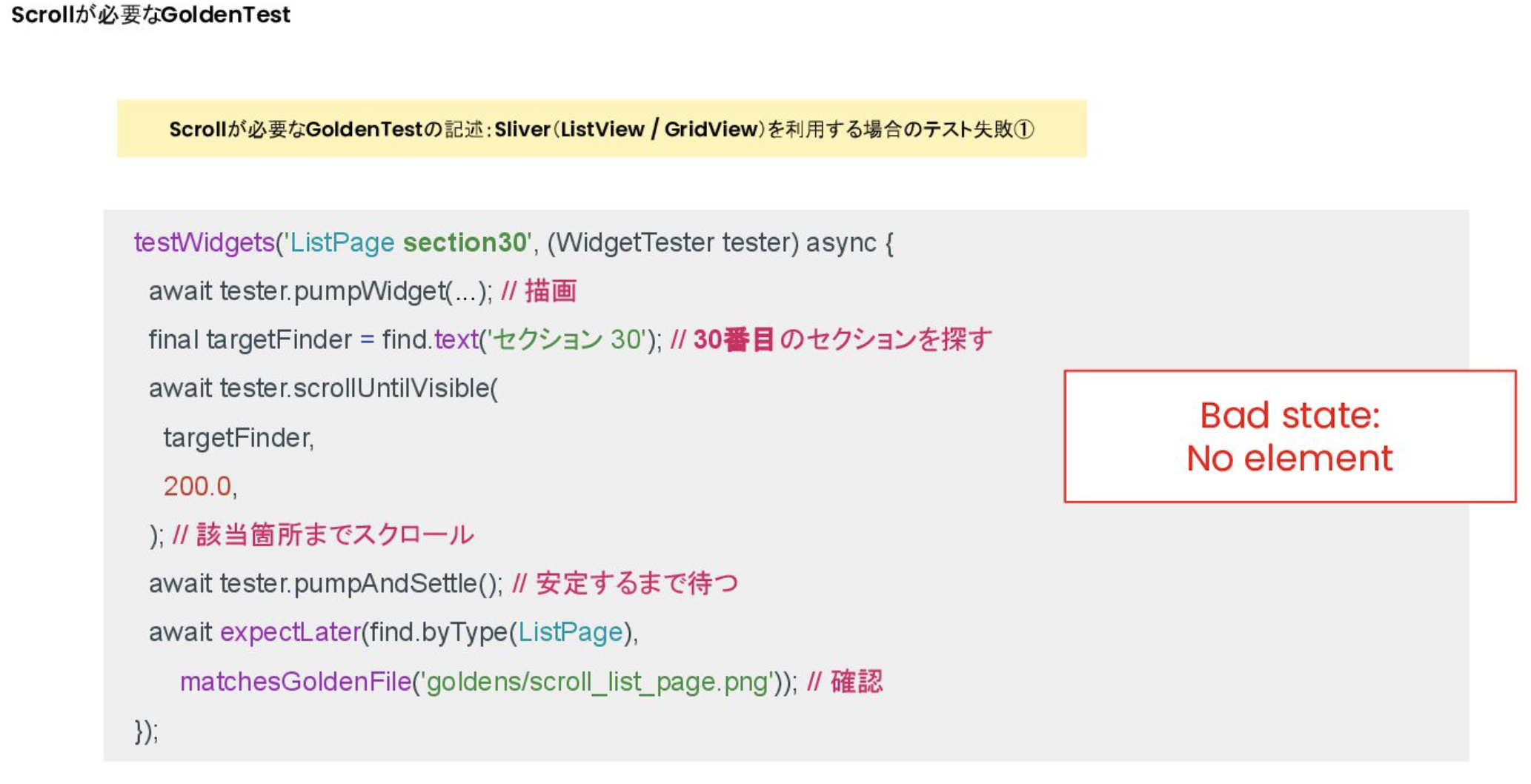
- Silver(ListView/GridView)에서는 화면이 표시되는 부분만 위젯이 렌더링 되기 때문에, 그려지기 전 까지 Finder에서는 알 수 없음
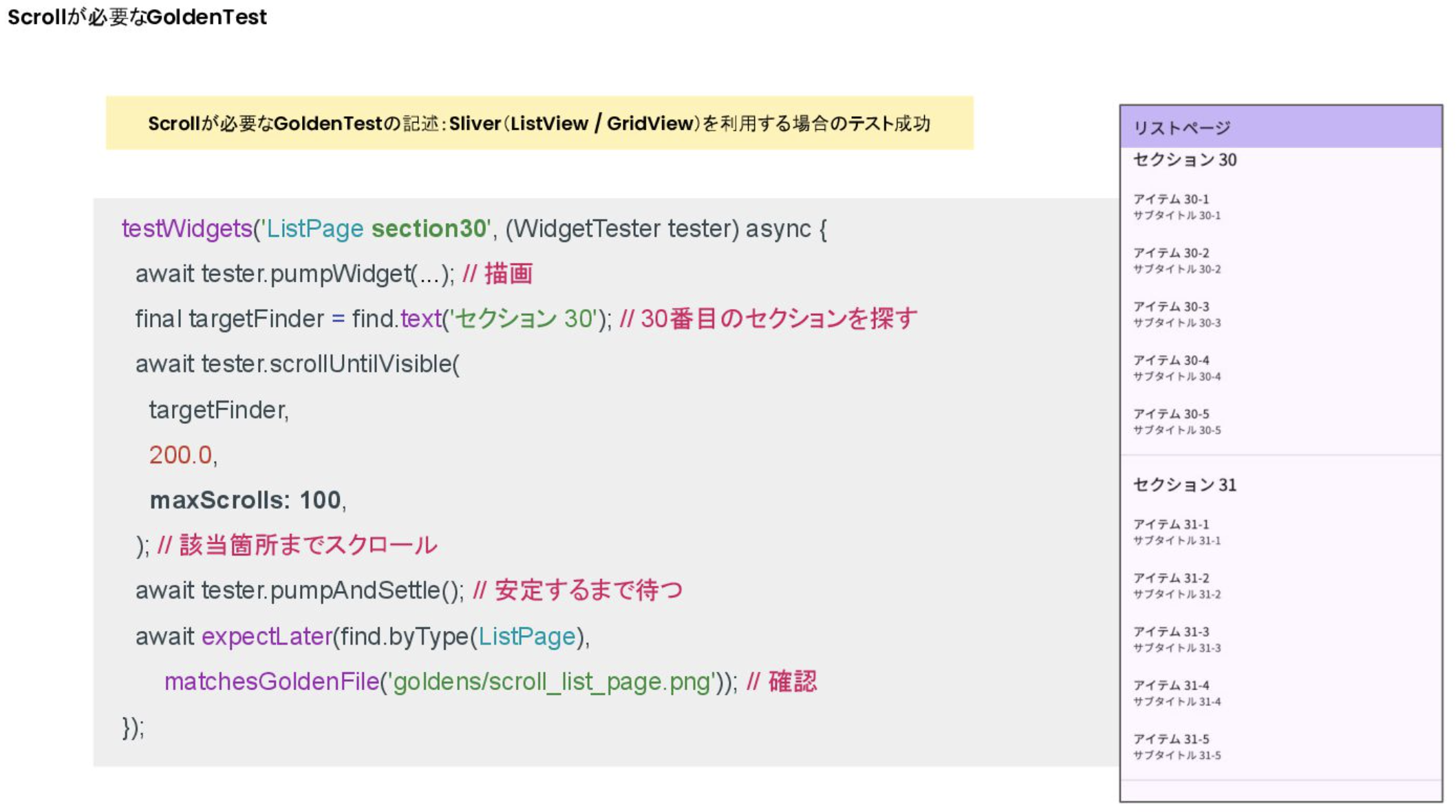
- 해결법1: Widget이 렌더링 될 때 까지 scrollUntilVisible의 maxScrolls을 늘린다
- 해결법2: Scroll이 불필요한 GoldenTest의 사이즈로 변경한다
Scroll이 필요한 GoldenTest 실패 (2)
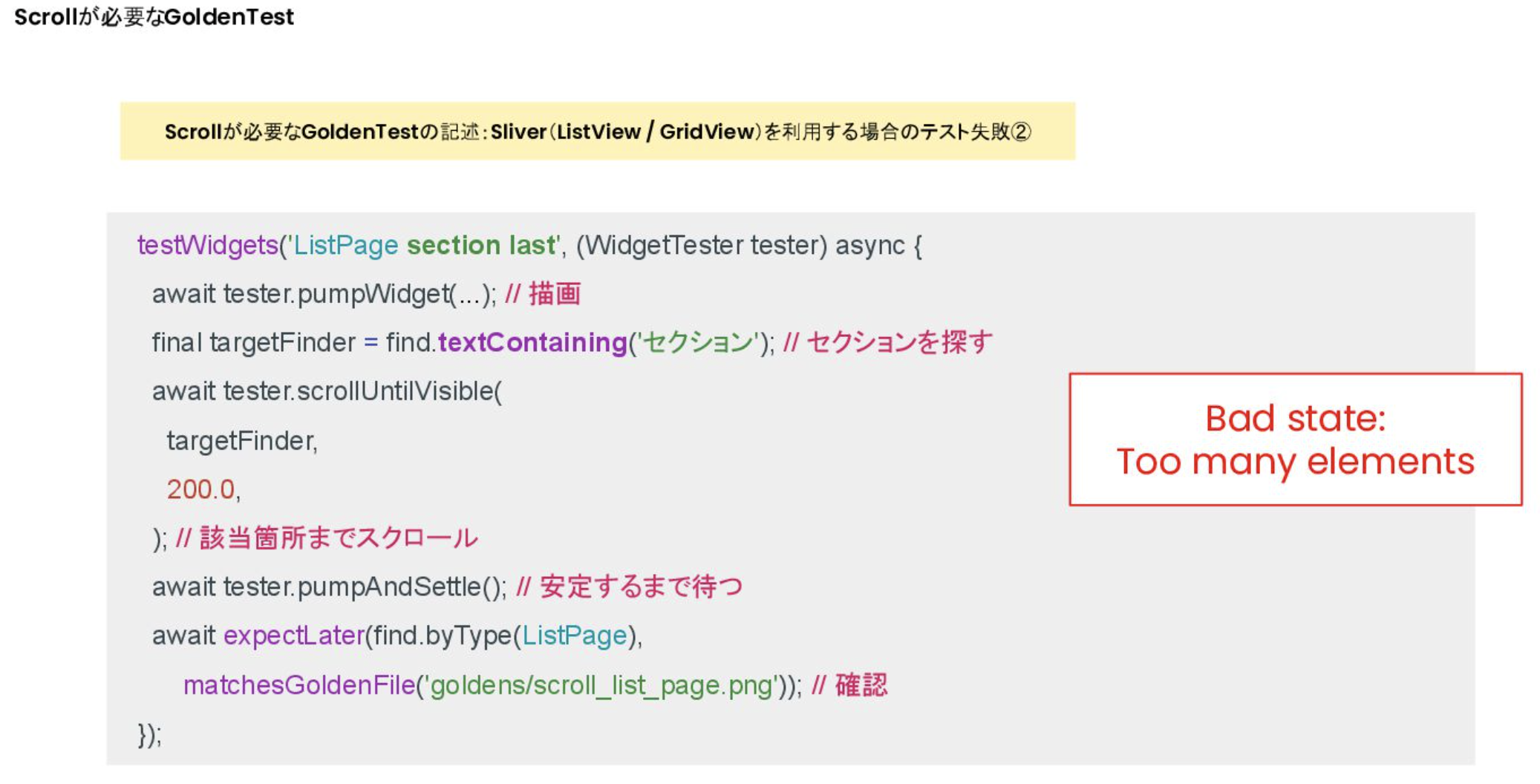
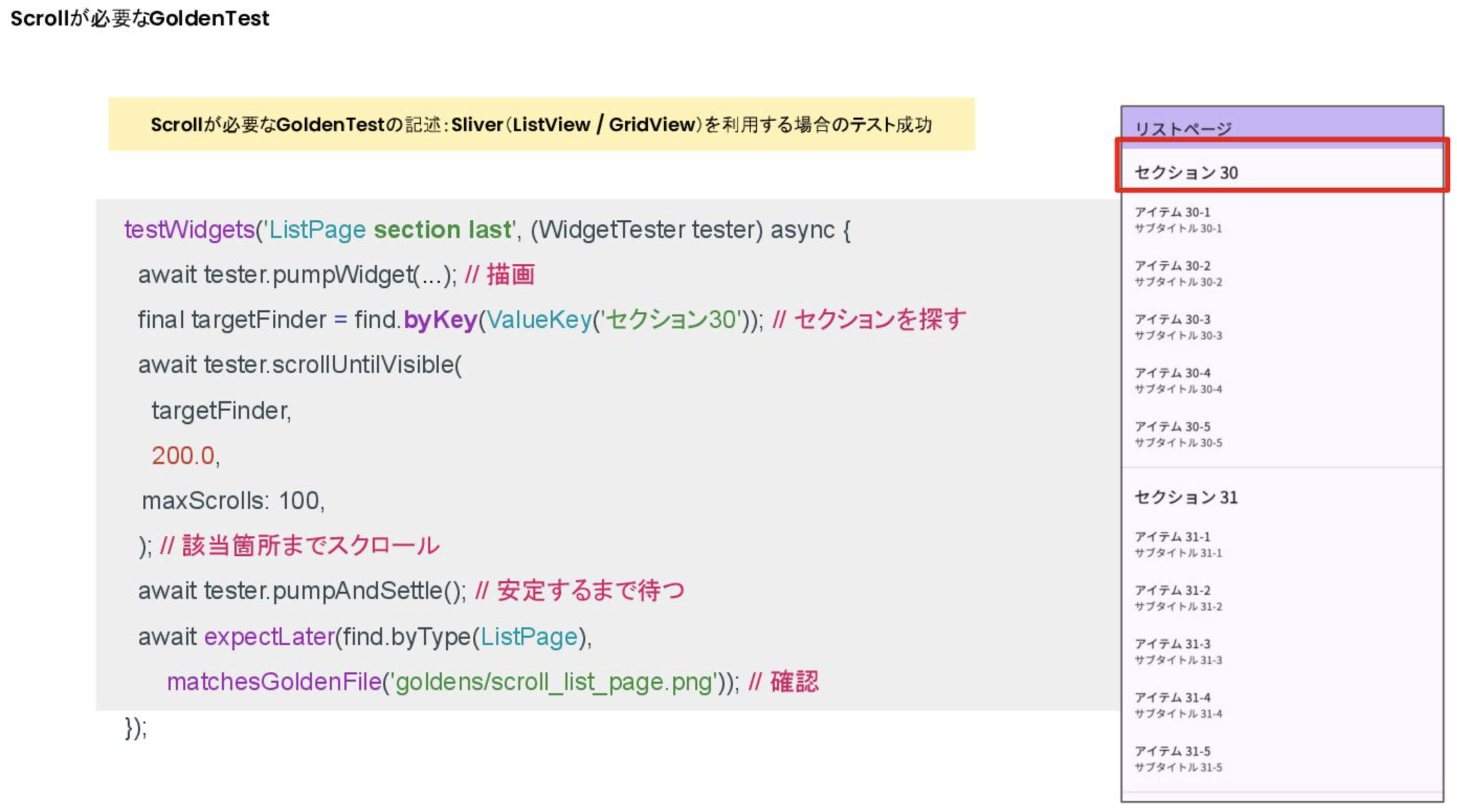
- scrollUntilVisible에서는 Finder에서 단일로만 사용가능
- 현재 섹션이 여러개 있기 때문에, セクション으로 찾으려 하면 여러 위젯이 나오기 때문에 에러 발생
- 해결법1: Silver(ListView/GridView)을 이용할 땐 Finder가 단일이 되도록 설정한다
- 해결법2: Type 지정이면 복수개가 될 때 ValueKey등으로 단일이 되도록 설정(ValueKey는 테스트 대상이 되도록 지정)
마무리
- GoldenTest를 이용할 때 VRT는 예상하지 못한 UI의 변경을 막아주거나 하는 편리한 기술
- scrollUntilVisible에 지정한 스크롤 위치의 GoldenTest가 가능
- Silver(ListView/GridView)를 이용한 GoldenTest에서 scrollUntilVisible을 이용할 때는 maxScrolls를 고려해서, Finder는 단일로 되도록 한다
Flutterアプリ運用の現場で役立った監視Tips 5選 (Flutter 어플 운용의 현장에서 도움이 되었던 감시 Tips 5선)
1. 여러 계층의 상태를 만든다(정보 수집의 다양화)
- 유저의 단말 내 설정(Shared Preference의 내부)
- Shared Preference는 유저에 따라 다르기 때문에 감시 가능한 상태가 바람직함(개인정보 수집 관련해서 조심히 접근하는 것도 중요)
- 단말의 스펙
- Sentry에는 기본으로 탑재되어있는 정보. 안드로이드는 특별히 단말 스펙이 다양하기 때문에 단말에 따라 일어나거나 일어나지 않는 상황이 다양함. Low 단말에서만 일어나는 문제는 우선도를 올리기/낮추기 등, 판단에 사용한다.
2. Alert 정보를 자세히 조사한다
- 모바일 어플의 성질상 하위버전의 서포트할 필요가 있고, 바이너리에 따라 발생하는 에러가 다르다. 어떤 플랫폼, 버전에서 일어나는지는 Alert에 필수 정보가 된다.
- 보통 최신 버전에서 발생하는 에러가 과거 버전에서 발생하는 에러보다 대응우선도가 높을 때가 많다.
3. 버전에 따라 감시하는 체제를 만든다
- Alert
- 모바일 어플에 있어서 최신 버전의 어플이 감시의 온도감(심각성)이 높은 대상이며, 특히 단계적 공개(점점 최신 버전을 유저에게 공개하는 방식)로 어플을 공개할 경우 전체 Alert만으로는 degradation(후퇴)를 깨닫는 것이 늦을 수 있다.
이를 위해 어플 릴리즈시 자동으로 관리하는 Alert를 최신 버전으로 갱신하는 로직을 도입한다.
- 모바일 어플에 있어서 최신 버전의 어플이 감시의 온도감(심각성)이 높은 대상이며, 특히 단계적 공개(점점 최신 버전을 유저에게 공개하는 방식)로 어플을 공개할 경우 전체 Alert만으로는 degradation(후퇴)를 깨닫는 것이 늦을 수 있다.
- 대시보드
- Alert와 동일한 이유로 버전 단위로 어플의 상태를 알 수 있는 대시보드를 생성.
버전 및 스펙, 플랫폼 등 다양한 정보를 통해 문제 원인 파악 정확도를 높이는 부분이 중요하지 않을까 생각
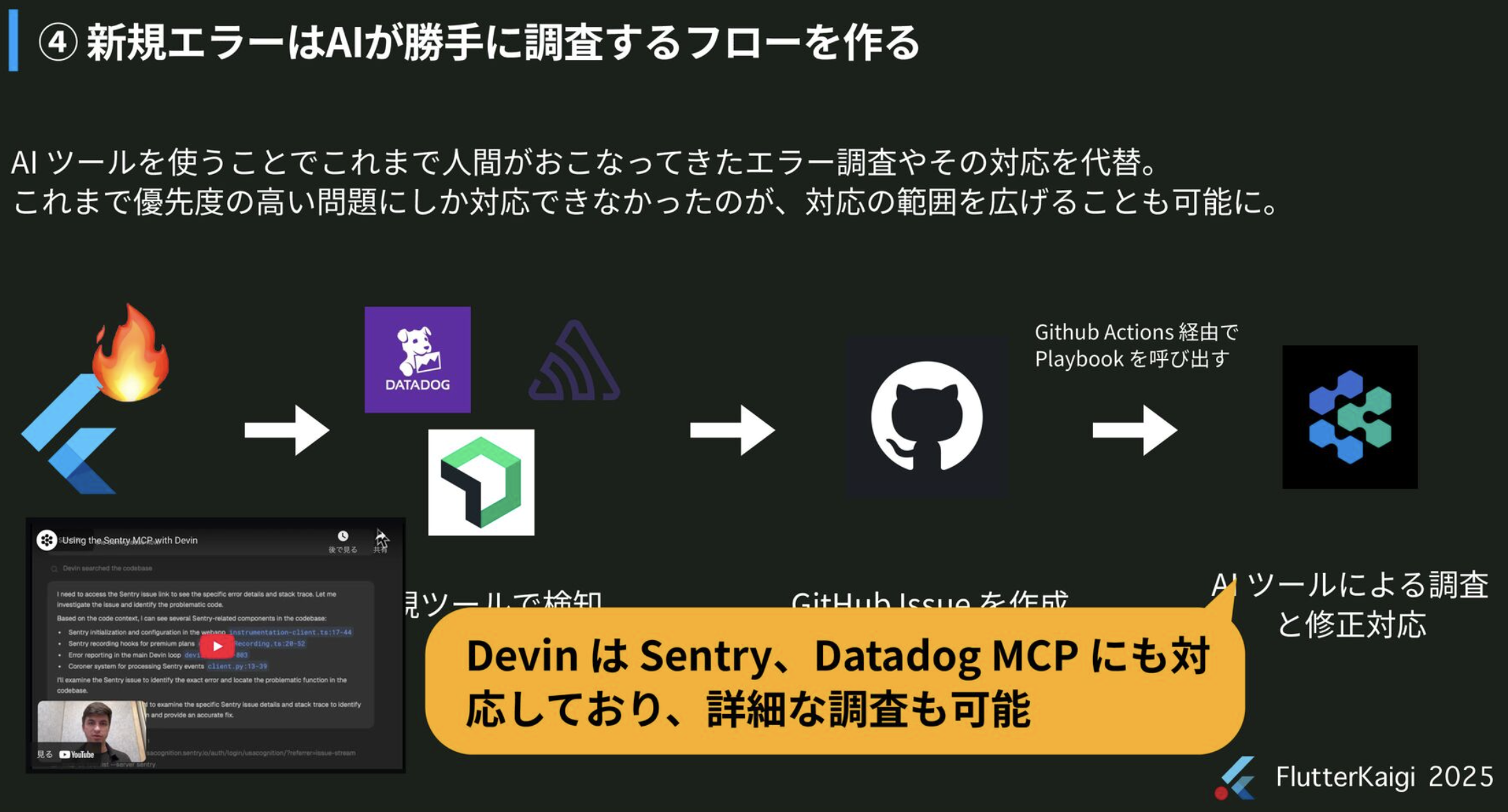
4. 신규 에러는 AI가 멋대로 조사하는 Flow를 만든다
- AI 툴을 사용하는하는 것으로 지금까지 인간이 했던 에러 조사와 대응을 대체.
지금까지 우선도가 높은 문제만 대응 가능했지만, 대응의 범위를 넓힐 수 있음.
5. 감시지표를 단계 릴리즈의 평가에 사용한다
-
모바일 어플리케이션을 안전하게 릴리즈하는 방법으로서 단계적 공개가 있다.
새로운 바이너리를 이용하는 유저를 단계적으로 넓힘으로서 장애가 있을 때 최소한의 유저 영향으로 끝낼 수 있다.
하지만, 어느 타이밍에 100% 공개할지 판단하는 것이 어렵다. -
WinTicket에서는 독자의 평가지표로 일정 샘플이 쌓였을 타이밍에 리포트를 작성.
이것으로 단계 공개중 바이너를 100% 공개해야 하는가 판단 가능.

-
어떻게 지표와 경계를 정하는게 좋은가? -> "프로덕트에 따라 다르다"
- E-Commerce 사이트에서 '99퍼의 유저가 구입 성공하는 상태'를 정상 상태라고 정상하면, (0.5% 오차 허용 범위에서) 2640건의 구입결과가 있으면 판단 가능하다.

- 모비율 신뢰구간의 오차를 기준으로 표본수 n은 다음식으로 구할 수 있다.
- Z: 신뢰수준에 대응하는 표준 정규분포의 수 (95% -> 1.96, 99% -> 2.58 등)
- E: 허용오차 (예: 0.01)
- p: 성공률(예: 0.99)
モバイル端末で動くLLMはどこまで実用的なのか (모바일 단말에서 움직이는 LLM은 어디까지 실용적인가)
- 왜 온디바이스LLM?
- 통신불필요, 어디서든 사용 가능, 단말안에 있음, API이용료X
- 대신 소형모델 or 기능제한
- 시장동향
- Apple Intelligence
- Gemini Nano
- 기술진화
- 모바일칩 성능 향상
- 저전력화
- 모델
- 아키텍쳐 진화
- 파인튜닝
- 경량화
온디바이스 LLM의 기초지식
- 주목 모델
- Google Gemma:Google AI Edge 최적화
- Meta Llama: 오픈소스
- Microsoft Phi-3: 소규모인데 고성능
- DeepSeek: 높은 추론, 코딩능력
- Qwen: Alibaba의 다언어 대응 모델
- 파라미터수
- 파라미터: 학습으로 얻은 지식을 유지하기위한 변수의 총수, 주로 가중치와 bias 두종류의 수치로 구성되어있음
- 높으면 표현력이 높고, 고품질 응답이 옴
- 대신 모델의 파일 사이즈가 거대하게 되기 때문에, 동작하기 위한 대량의 메모리와 계산능력 필요
- 양자화
- 파라미터수를 바꾸지 않고 파라미터에 사용하는 데이터 사이즈를 작게하는 기술
- 계산속도 오름
- 대신 퀄리티 떨어질 가능성 있음
- 32bit → 8bit → 4bit 처럼 압축
- 이러면 파라미터수 7b기준 28G.B → 3.5GB까지 축소됨
- gemma-3n-E4B-it-int4.task
- E4B: 40억 파라미터
- it: 지시 튜닝(파인 튜닝)
- int4: 4bit 양자화
Flutter에서 LLM을 구동하는 선택지
- GGUF → llama.cpp
- 모델이랑 토크나이저 일체화
- 양자화 모델도 있음
- 일부 모델에서 멀티모델 가능
- Task(LiteRT-LM)
- 멀티모달 대응
- GPU, NPU활용 가능
- 파일은 unzip 가능, 안쪽 확인 가능
- flutter_gemma 연계 가능
- Cactus
- ARM CPU 아키텍쳐에 최적화
- FFI 이용해서 크로스플랫폼 대응
- Flutter, React Native, KMP에서 이용 가능
- cactus-flutter 패키지로 이용가능
- 음성도 있다! (whisper-tiny model)
- 이용 주의점
- 메모리는 모델사이즈에 따라 4-8기가 이용 필요
- 모델 사이즈가 크면 어플의 설정이 필요
- 거대한 모델 어플의 bandoru는 불가능
- increased-memory-limit + largeHeap=”true”
- HuggingFace로 모델 찾기 가능
- 라이센스 잘 보고 사용하기
온디바이스 LLM 응용기능
- LLM 그 자체는 정보가 옛날 → Function Calling 사용
- Function Calling
- 외부 함수나 API을 호출
- 흐름
- 이용가능한 함수의 스키마(이름, 인수,설명) 정의
- 유저 request랑 스키마를 LLM에 넘김
- LLM에게 필요한 인수를 JSON으로 전달
- 등등
- SaaS API랑 연동하면 최신정보 얻기 가능
- 주의점
- LLM가 의도하지 않은 값을 JSON으로 넘겨줄 가능성 있음
- security 조심
- FST 제약?
- LLM의 출력을 특정 형식으로 룰을 따르도록 제약하는 기술
- JSON 등의 구조화 포맷 지키도록 강제
- 출력의 일관성 신뢰성이 올라감
- 하지만 내용이 맞다는 보장은 아님
- front-end 엔지니어링 주의점
- 함수 호출 포맷 명확하게 정의MCP서버랑 연계할 수 있을 것 같은데 그러면 오프라인 온디바이스의 의미가 퇴색 될 것 같다..
퍼포먼스 실천을 위한 선택지
- 모델 선택
- 어느 정도의 복잡한 태스크?
- 멀티 모델 대응 필요?
- 일본어 응답 속도(자국언어)
- 디바이스에 대해
- memory 4-8GB 이상 추천
- 실제 기기로 추론속도는 1B-4B 모델로 5-20토큰/초 정도
- 어플 임베딩
- 모델 사이즈가 커서 application에 번들은 곤란
- 다운로드 하는 작동이 필요
- 큰 모델을 이용할 때는 어플의 설정변경이 필요
- UX
- 문장 아니면 음성 입력에 대한 입력체험을 생각해야함
- 토큰수의 상한이 적어서 긴 회화의 이력 보관은 어려움
- 글자출력은 스트리밍이 좋지만 Function Calling등과의 궁합은 별로 좋지 않음
- Function Calling이 답변을 전부 받고나서 작동하기 떄문
- Function 단계에 따라 알려주는 UI를 보여주기?
- 응답속도 응답품질 개선
- 파라미터 크면 고품질 경량은 응답 빠름
- 영어가 전체적으로 유리 (코스트, 속도)
결론
- 일반유저에게 공개하기엔 아직은 무리에 가까움
- 사내용 어플에 도입하는게 좋을수도
オフライン対応!Flutterアプリに全文検索エンジンを実装する (온라인 대응! Flutter 어플로 전문 검색 엔진을 탑재하다)
LLM ↔ Cloud ↔ Flutter
Problem, motivation
- API형 LLM은 네트워크 없이 이용 곤란
- On device를 이용해서 AI를 활용
- LLM제약: Knowledge Cutoff가 있다.
- Knowledge Cutoff: AI가 학습한 순간부터 현재까지의 정보가 없음
- RAG를 활용해서 Knowledge Cutoff를 보완
- RAG 방법
- 프롬프트 context 제공
- Vector Database 활용
- 하이브리드 검색
- 웹검색
- 프롬프트 context 제공
- 이제 필요한 정보만 넣는것도 중요해지고 있다. → 유의도 검사로 여러개 검색 결과중 필요한 정보만 추리기
Vector Database
- ChromaDB
- Milvus
- Qdrant
- Pinecone
- DuckDB
- ElasticSearch
- OpenSearch
Embedding text
- Embedding Gemma
- 300M parameter
- Dimension size가 768
- QwenEmbedding
- 0.8M이 있음
- Embedding text text + 유의도 검사는 한계가 있다
- 다언어대응의 관점으로부터 제한이 있음
→ 이걸 위해 전문 검색
- 다언어대응의 관점으로부터 제한이 있음
파라미터
| 파라미터 수 | 대략적 위치 |
|---|---|
| 10M ~ 50M | 아주 가벼움 (정확도 낮음) |
| 100M ~ 300M | 실무 임베딩에 충분 |
| 1B 이상 | 고성능 (비용·지연 큼) |
| GPT-3 | 175B |
차원
| Dimension | 의미 |
|---|---|
| 128 | 거칠고 단순 |
| 256 | 가벼운 검색 |
| 512 | 실무 기본 |
| 768 | 표준 고품질 |
| 1024+ | 고정밀 (비용 증가) |
전문검색
- 문장의 전체적 파악 (형태소까지?)
- 조건은 오프라인!
- 스마트폰에서 LLM 동작 가능
- embedding text, 유의도 검사도 가능
- 일본어, 한국어, 중국어는 개선 필요
- Flutter + 오프라인이어도 전문검색 엔진이 필요
어떻게?
- FTS(Full Text Search) 엔진, 라이브러리 확인
- 작성된 Flutter 패키지 있는지 확인
- CJK(중국어, 일본어, 한국어) 대응 확인
- 존재하지 않으면 자작
- 결과 테스트 + 벤치마크
전문검색용 DB(SQLite FTS5 Extension)
- SQLite FTS5 Extension가 있음
- Flutter에는 drift 2.29.0라는 패키지로 활용 가능
- sqlite3_flutter_libs 0.5.40도 활용 가능
- 토크나이저 문제가 있음
- 4개의 빌트인 토크나이저가 있어서 영어는 대응, CJK는 한정적..
→ CJK대응 가능한 토크나이저를 조사하자. Flutter 패키지도.
형태소분석기(Tokenizer)
- jieba: 중국어, Flutter 패키지 있었음
- mecab - ipadic: 일본어, Flutter 패키지 없음.
- mecab - ko&kiwi: 한국어, Flutter 패키지 없음.
Tantivy
- Rust로 개발된 고속전문검색 엔진 라이브러리
- Rust
- 메모리 안전성 보증
- 고속 퍼포먼스
- 병행처리 강함
- C/C++와의 호환성 굳
- 크로스플랫폼 대응에 용의함
→ Tantivy로 해결해보자
탑재 단계
- rust로 코딩, rust FFI로 연결 (cargo 사용, rust용)
- Cargo.toml로 c로 되도록 정의
- FFI하려면 함수명이 변환되지 않도록 #[unsafe(no_mangle)] 매크로가 필요!
- pub extern “C” 필요
- ios는 runner에서 library 추가해야함
- pub extern “C” 할때 함수명, 리턴타입, 파라미터 등 맞춰서 적어주기
→ rust로 코드를 적고, android/ios native code를 작성, Flutter C용 FFI를 사용?
- Native API 설계
- tantivy_init으로 함수명 정의
- ffigen으로 rust 코드가 android/ios native code로 자동 작성되도록 하자
벤치마크
- 100개에 0.095ms
- 일본어 검색 문제 있음..
과제, 개선점
- tantivy는 flutter에 임배딩, 개선점 확인
- 영어는 좋지만, CJK 대응 문제 있음.
- 중국어 대응 flutter tantivy package가 있었지만 일본어, 한글 문제가 있음..
- Libera-Tantivy
- CJK 대응
- 하지만 Flutter에서 대응 가능한 패키지를 찾지 못함.
Flutter Rust Bridge 사용하면 코드 생성 간단
- Rust, Flutter 코드 생성 가능
- Flutter rust bridge codegen으로 코드 생성 가능
- 구조
- crate::api: 어느 부분을 Dart에 공개?
- rust: Cargo.toml가 있는 Rust project 경로
- 사용 방법
- 특정 매크로를 이용해서 Flutter+Rust둘다 대응 가능
- native code build는 flutter rust codegen 사용
- wrapper class로 생성해줌!
- flutter rust codegen 어쩌구 —template plugin
- 벤치마크
- 문서 100개에 128ms
- 문서 1000개에 222ms
- test device: Nothing 3s 12G
- flutrer_lindera_tantivy로 0.0.1 있음

アイコン:https://x.com/xx_chon_xx