
기존 구현 방식
아래와 같이 상품과 좋아요를 다대 1로 구현했다.
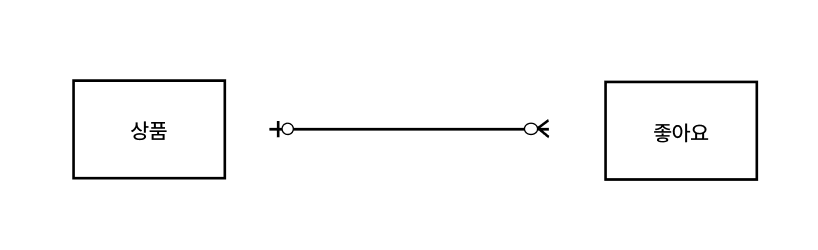
이렇게 일대다로 테이블을 구성했을 때, 기존에 좋아요의 개수를 받아오는 방법은 다음과 같았다.
public int getHeartAmount(final Long productId) {
return heartService.findByProductId(productId).size();
}위 처럼 product 테이블의 식별자 값으로 List<Heart>를 찾고 사이즈를 반환하는 것이다.
정규화를 하면서 이와 같은 로직으로 구현하게 되었는데, 단순 List의 크기를 반환하고자 모든 좋아요를 조인해야하는 것이 비효율적이라는 생각이 들었다.
이 때 정규화는, 쉽게 말하자면 테이블 간에 중복된 데이터를 허용하지 않는 것이다.
그러면 이것을 반정규화 하게 되면 어떻게 될까?
반정규화 과정
좋아요 개수를 상품 테이블에 저장하게 되면, 여러 개 좋아요 테이블에 대한 join을 한 개의 select 문으로 해결할 수 있다.
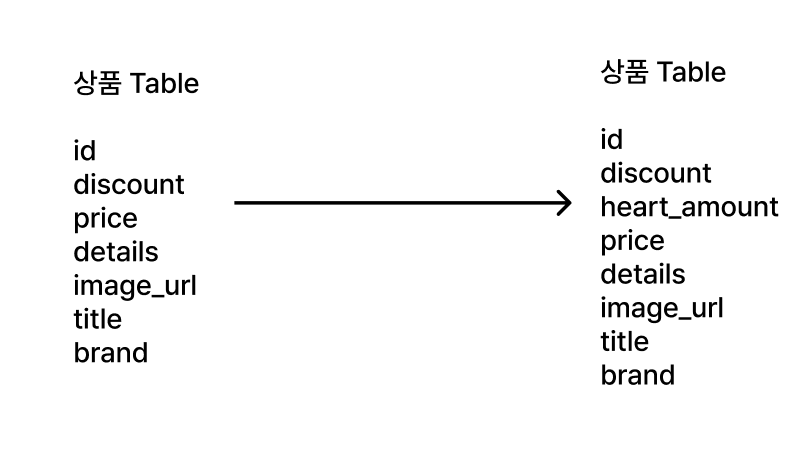
이렇게 heart_amount를 추가하고 좋아요를 누를 때 마다 +1, 좋아요를 취소할 때마다 -1 하게끔 다음과 같이 구현했다.
Product.java
public void increaseHeart() {
this.heartAmount++;
}
public void decreaseHeart() {
this.heartAmount--;
}ProductJpaRepository.java
@Query("select p.heartAmount from Product p where p.id = :productId")
int findHeartAmountByProductId(final @Param("productId") Long productId);
ProductService.java
public void decreaseHeart(final Long productId) {
getProductById(productId).decreaseHeart();
}
public void increaseHeart(final Long productId) {
getProductById(productId).increaseHeart();
}
public int getHeartAmountFromProduct(final Long productId) {
return productJpaRepository.findHeartAmountByProductId(productId);
}성능 개선
이렇게 반정규화를 진행했을 때, 성능 차이가 얼만큼 발생하는지 10만개의 요청이 있을 때 테스트를 해보았다.
1번 째 실험

2번 째 실험

- 사용 도구 : apach jmeter 5.6.2
이렇게 반정규화를 통해 근소하지만, 성능 차이를 확인하였다.
💡 이번 기회를 통해 성능 차원을 고려하면서 DB 테이블을 짜야겠다고 느꼈다!
하지만, 반정규화는 성능 향상을 위해 정규화를 포기하고 연산 처리에 대해 최적화하여 설계하는 것이고, 데이터 무결성이 보장되지 않으므로 제한적으로 사용해야 한다.

하루에 한 걸음씩