
지난 글에서 자동이체 서비스 코드를 어떻게 개선했는지 적었습니다.
오늘은 자동이체 시스템에서 존재했던 동시성 이슈를 살펴보고, 당시에는 개선하지 못했지만 어떻게 개선할 수 있었을지 적어보겠습니다.
전문번호와 동시성 이슈
전문과 전문번호
금융권에서는 연동을 위해 대부분 전문 통신을 하는데, 해당 통신에 사용되는 데이터를 전문이라고 합니다. HTTP 통신으로 치자면 JSON이 되겠네요. 그럼, 이 전문은 어떤 형식일까요?
약속된 위치와 길이에 데이터를 위치시키는 형식
가령, 다음과 같이 약속을 합니다.
1~6: 생년월일
7~9: 이름그럼 "090807김개똥"이라는 요청을 보내면, 090807은 생년월일로, 김개똥을 이름으로 식별하는 방식입니다.
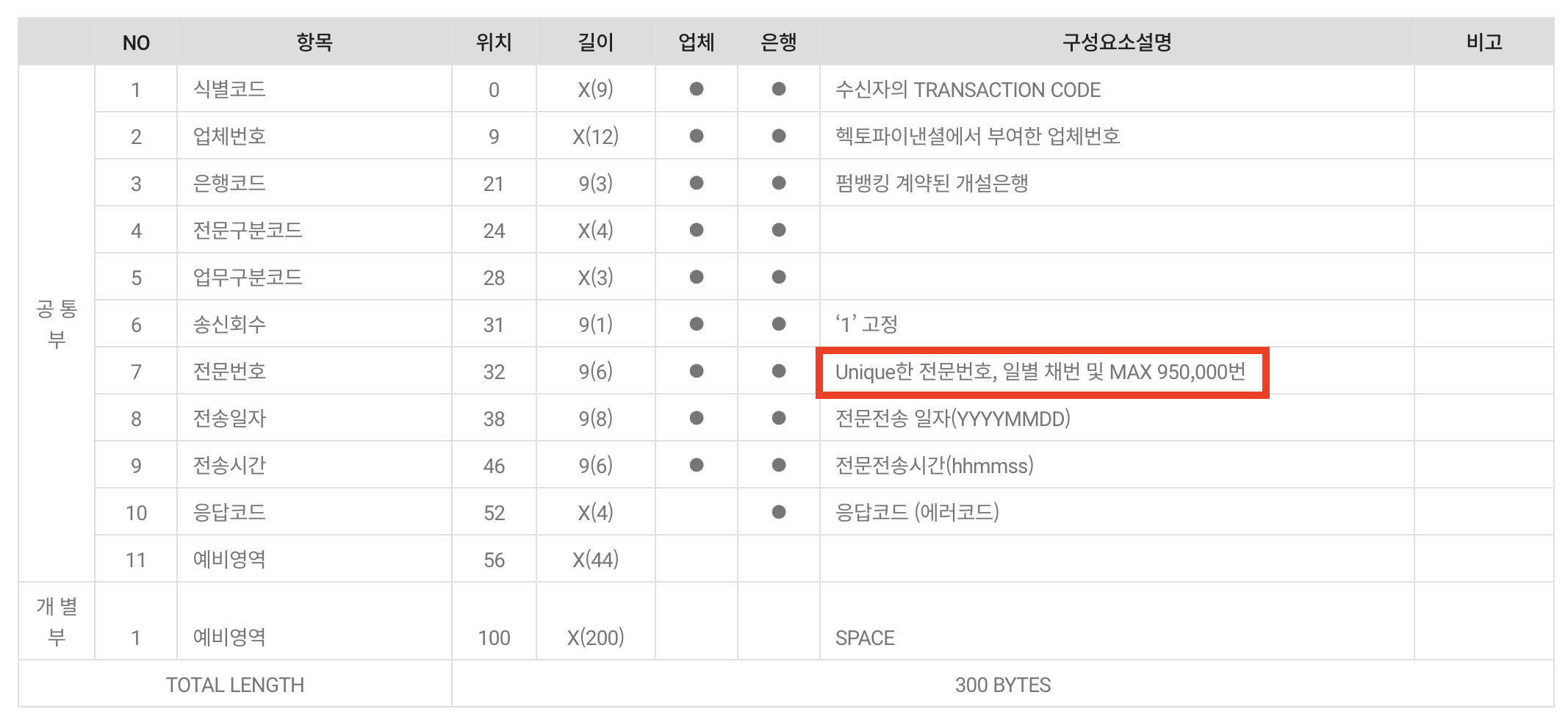
위 사진은 헥토파이낸셜에서 제공하는 개발가이드 문서입니다. 전문을 구성하는 내용을 살펴볼 수 있으며, 전문번호 필드도 존재합니다. 전문번호는 하단의 설명과 같이, 각 전문 요청에서 구분되도록 고유하게 설계되어야 합니다.
전문 요청은 출금, 송금, 예금주 조회 등 다양한 경우에 쓰입니다. 그리고 매번 고유한 전문번호가 필요합니다. 일반적으로는 하루 단위로 유일성 보장이 필요합니다. 예를 들면, 오늘 234567번을 사용했다면, 오늘 자정 이후에는 234567번을 사용해도 됩니다.
동시성 이슈
그렇다면 전문번호 채번 과정에서 어떤 동시성 이슈가 발생하는 걸까요?
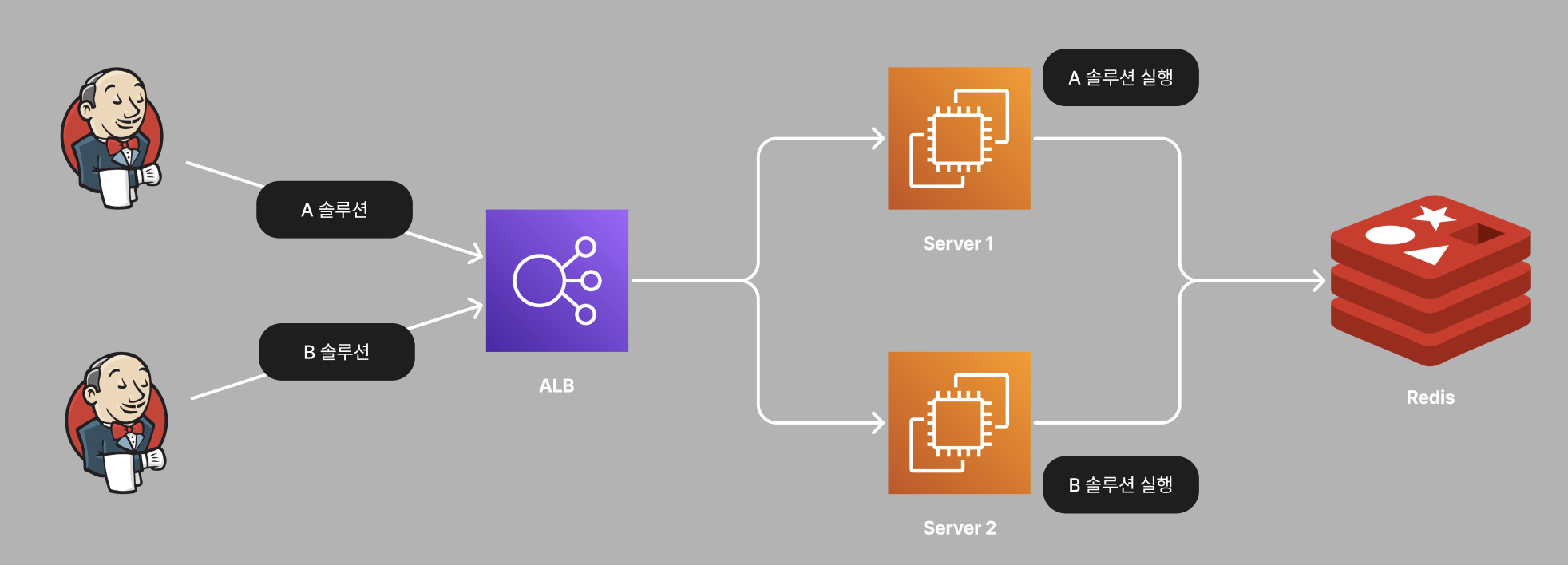
일반적으로 전문번호는 이전 요청에서 +1 한 값을 다음 요청에 사용합니다. 가장 직관적이고 단순한 방법입니다. 근데, 두 대 이상의 서버에서 이전 요청을 동시에 조회하는 경우 문제가 생깁니다.
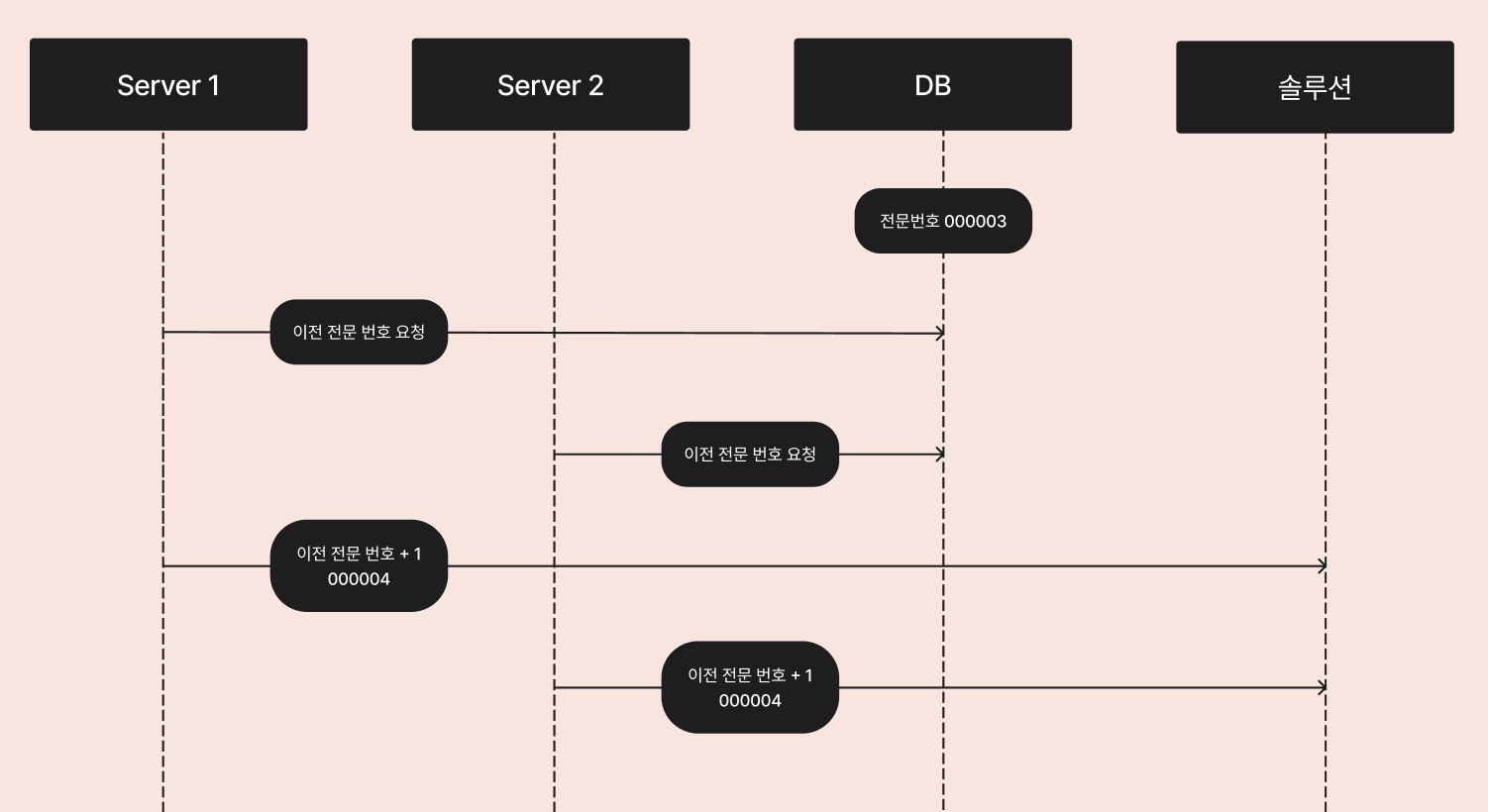
위의 사진 기준으로 Server1과 Server2는 같은 전문 번호인 "000004"를 가지고 솔루션에 요청을 보내게 됩니다. 이에 따라 두 전문 번호가 유일성이 보장되지 않고, 뒤늦게 이루어진 요청은 실패하게 됩니다.
문제와 해결
문제의 발단
동시성 이슈 발생 가능성이 있는 상황이었으나, 실시간 요청이 많지 않았기 때문에 장애 상황이 발생하지는 않았습니다. 문제는 자동이체 서비스에 출금 솔루션을 추가하며 발생했습니다.
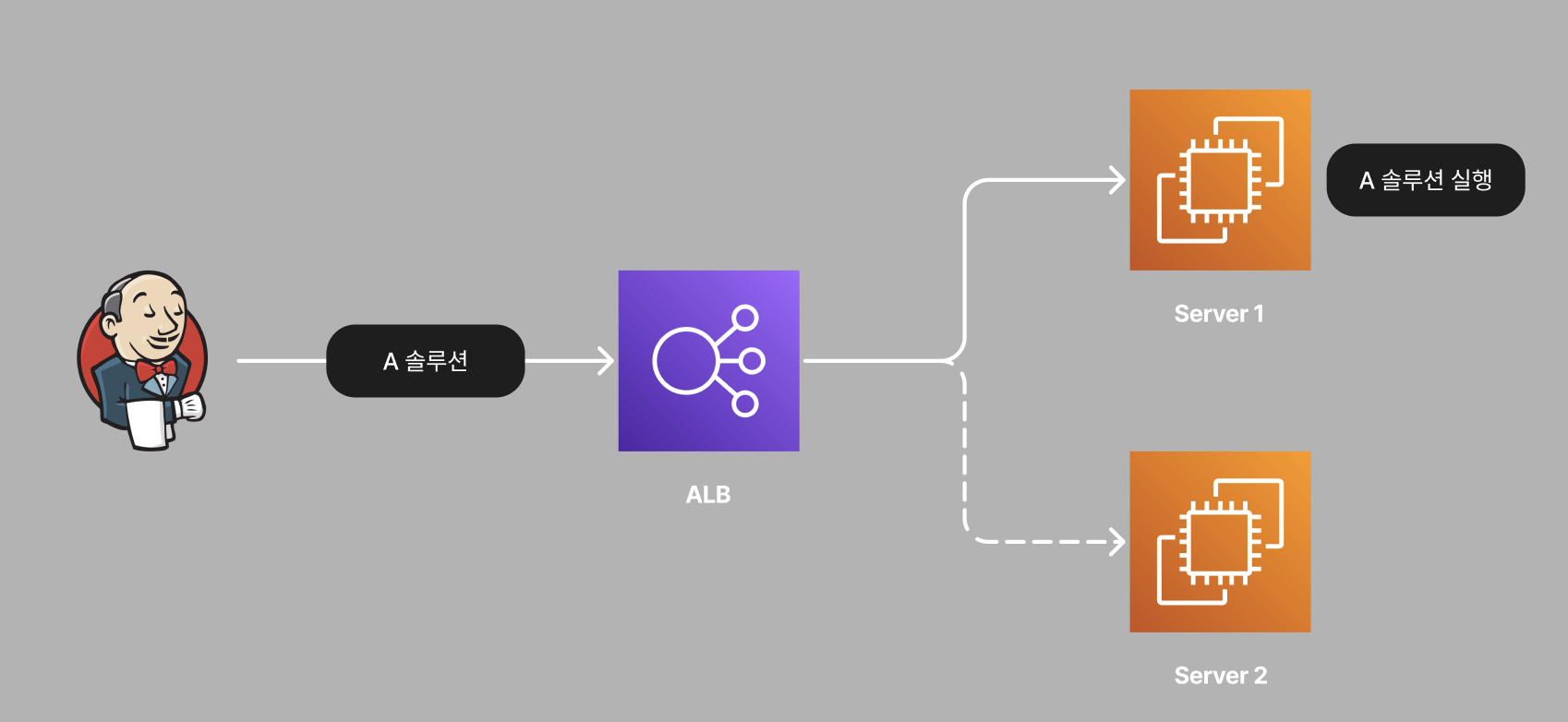
기존에는 JENKINS에서 자동이체 서비스를 실행하면, 두 대의 서버 중 하나에서만 자동이체 작업이 실행되었습니다. 그래서 동시성 이슈가 발생할 가능성이 작았습니다.
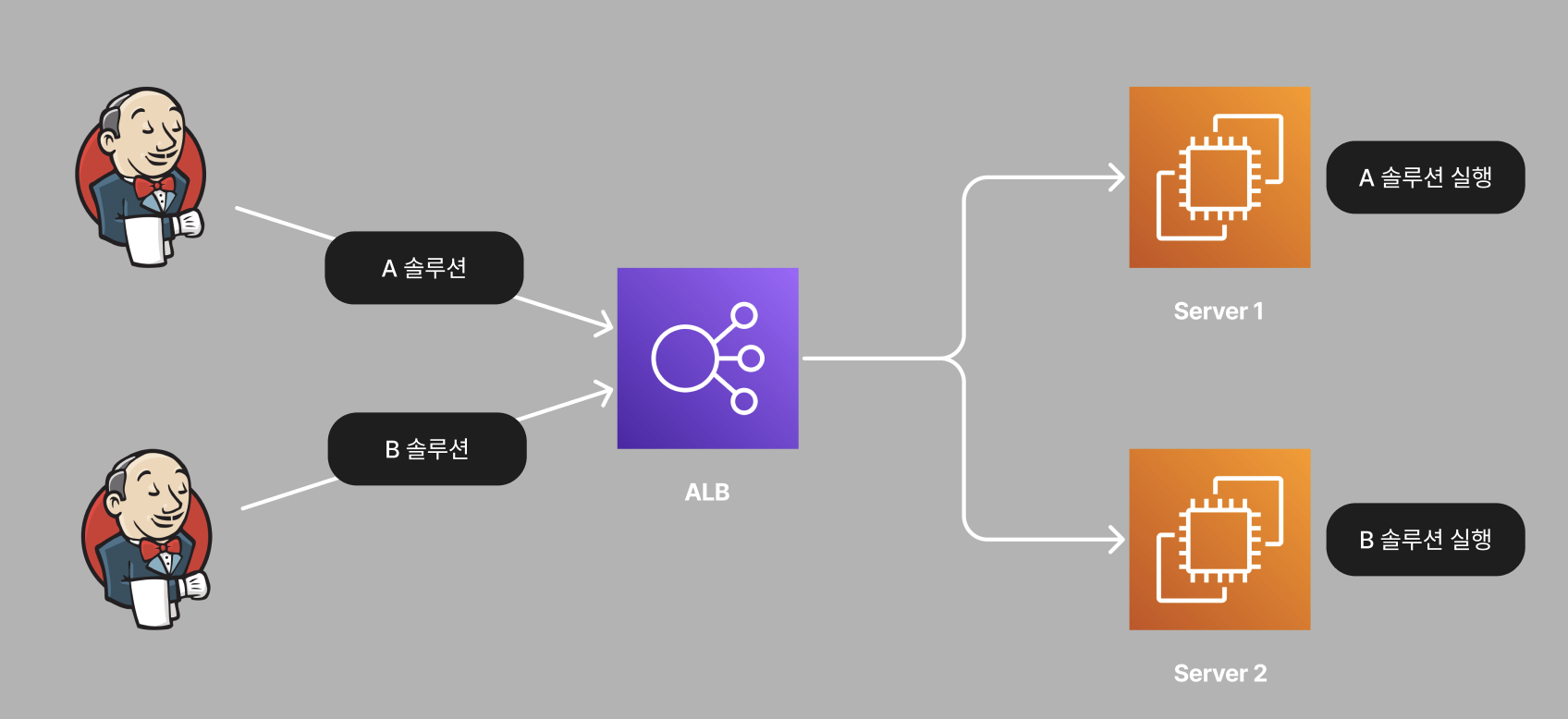
그러나 신규로 출금 서비스를 추가하면서, 두 대의 서버에서 자동이체 작업이 동시에 처리되었습니다. 두 개의 서버에서 전문번호 채번 작업을 진행하면서 동시성 이슈 발생 확률이 높아졌고, 자동이체 건수가 많은 날에 동시성 이슈가 발생했습니다.
문제의 해결
자바 개발자가 한 명인 상황에서, 다른 피처 개발로 인해 별도의 아키텍처를 구축할 상황은 되지 못했습니다. 그래서 코드 작업을 줄이고 해결할 방법을 모색했습니다.
자동이체 서비스는 각 솔루션이 하루에 2번씩 실행됩니다. 두 솔루션의 실행시간은 동일해서, 가령 오전 7시와 오후 7시에 실행된다고 하면, 두 서비스 모두 오전 7시와 오후 7시에 각각 실행됩니다.
동시성 이슈 발생을 회피하기 위해 한 솔루션의 실행 시간을 30분씩 늦추었습니다. 동시에 실행되는 건수를 줄여 이슈 발생 확률을 낮췄습니다. 물론 이렇다고 해도 가능성이 0%가 된 것은 아닙니다.
대안을 고민해보자
시스템을 개선한다면 API든 자동이체든 전문번호 채번 실패로 요청이 실패되는 케이스는 없게 만들고자 했습니다.
이러한 배경을 가지고 몇 가지 대안을 살펴보겠습니다.
대안1. UPDATE AND RETURNING
PostgreSQL은 UPDATE AND RETURNING 구문을 지원합니다. 해당 구문은 업데이트를 실행하고, 업데이트된 결과를 반환합니다. 즉 UPDATE 후 SELECT 한 것과 동일한 결과를 얻을 수 있는데, 별개의 쿼리가 아닌 하나의 쿼리로 실행됩니다.
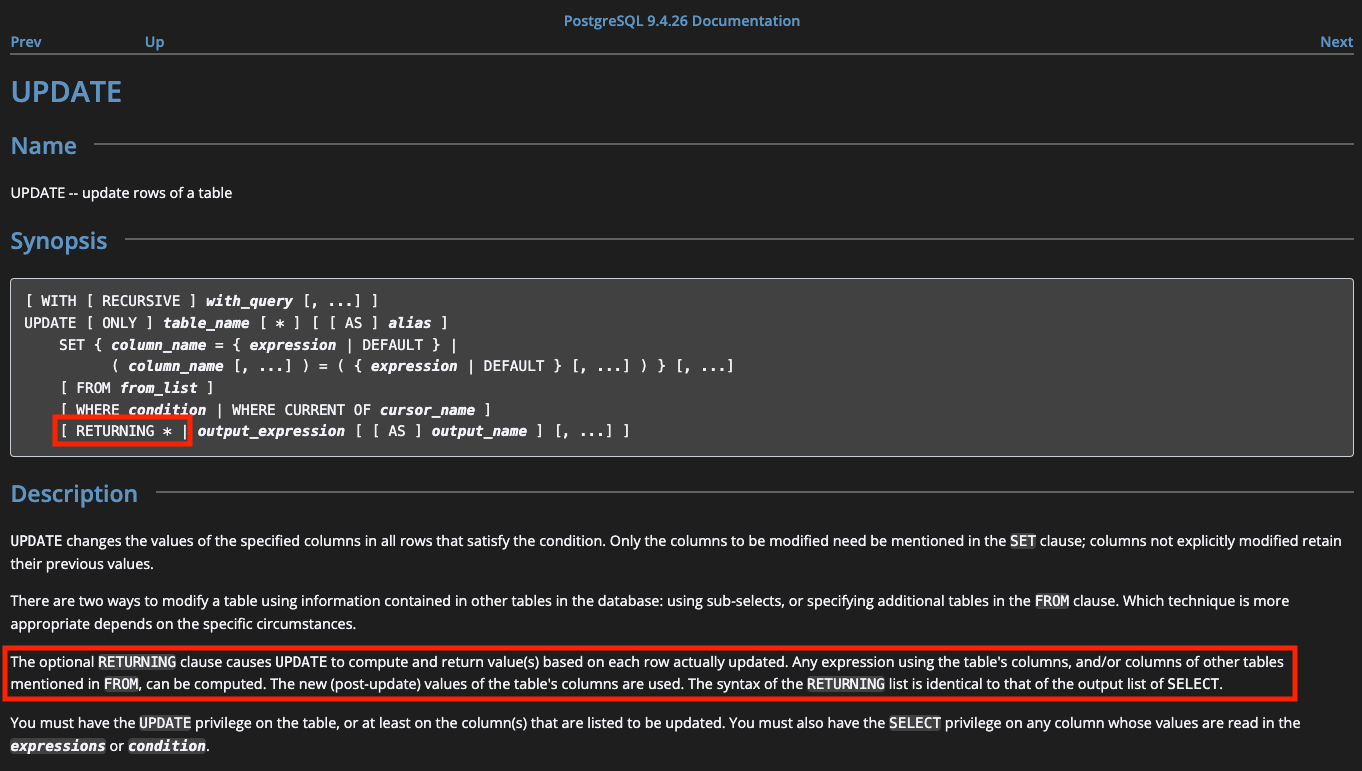
해당 쿼리를 사용할 경우, 전문번호 채번용 테이블을 별도로 생성할 수 있습니다. 해당 테이블에서 일자별로 row를 생성하고, 전문번호를 UPDATE AND RETURNING 한다면 가장 간단히 문제가 해결됩니다.
그러나 사용 중이던 DB는 MySQL 5.7 버전이었고, 9.1 버전인 현재에도 해당 쿼리는 지원되지 않고 있습니다.
대안2. Lock
동시성 이슈 하면 락을 거는 방법이 떠오릅니다. 락은 성능과 트레이드 오프가 있기 때문에 신중해야 합니다.
락을 걸면 전문번호 채번이 실패하는 케이스가 발생할 가능성이 높아집니다. 가령 자동이체 처리를 위해 배치가 돌아가는 시점에, 매 요청이 락을 잡게 되면 상당히 오랜 시간 락을 잡게 됩니다. 약 500건을 처리하는데 10분 정도 소요되기 때문에, 오랜 시간 락을 잡고 있게 됩니다.
문제는, 배치가 돌아가는 시점에 API를 통한 전문번호 채번도 이루어진다는 점입니다. 자동이체 배치 시스템에서 잡고 있는 락으로 인해 API 요청이 타임아웃 될 가능성이 높아집니다. 결국 요청이 많아질수록 Lock으로 인한 전문번호 채번이 실패할 가능성이 높아지게 됩니다.
대안3. Redis INCR
대안1과 대안2는 모두 기존 인프라에서 해결하고자 했던 고민이었습니다. 문제는 두 가지 대안 모두 적절한 해결책은 되지 못했다는 점입니다. 그렇게 몇 가지 방법을 찾다가 발견한 게 Redis INCR입니다.
Redis INCR은 문서에도 나와 있는 것처럼, 특정 key값의 value를 +1 한 값을 반환합니다. 이때 동시성 이슈는 발생하지 않습니다. 싱글 스레드인 Redis의 특성상 원자성을 보장하기 때문이죠. 이는 클러스터 환경이어도 마찬가지입니다.
이렇게 설계를 진행할 경우, (1) 자동이체를 처리하는 서버가 스케일 아웃하더라도 문제가 없고, (2) 원자성이 보장되어 전문번호가 중복되는 일이 없다는 점 (3) Redis를 사용하여 구현 난이도가 낮다는 점에서 적절한 해결책으로 보입니다.
대안 검토
간단한 테스트 코드를 작성하여 확인해보겠습니다. 전체 테스트 코드는 해당 링크에서 확인할 수 있습니다.
동시성 이슈 테스트를 위한 메서드
동시성 이슈 테스트를 위해 테스트 환경에서 다음의 메서드를 선언하여 테스트를 진행했습니다. 다음 링크에서 자세한 설명을 확인하실 수 있습니다.
private fun runConcurrentTask(numberOfThread: Int, repeatCountPerThread: Int, task: () -> Unit) {
val startLatch = CountDownLatch(1)
val doneLatch = CountDownLatch(numberOfThread);
val executor = Executors.newFixedThreadPool(numberOfThread)
repeat(numberOfThread) {
executor.submit {
try {
startLatch.await()
repeat(repeatCountPerThread) {
task()
}
} finally {
doneLatch.countDown()
}
}
}
startLatch.countDown()
doneLatch.await()
executor.shutdown()
executor.awaitTermination(1L, TimeUnit.SECONDS)
}기존 방식으로 채번하는 경우
예시 코드에서 실제로 솔루션에 요청을 보낼 수는 없으므로, 전문번호를 포함한 가상의 요청 기록을 DB에 저장하고, 전문번호의 중복 여부를 판단해 보겠습니다.
@Test
fun `INCR을 사용하지 않는 경우 동시성 이슈가 발생한다`() {
runConcurrentTask(2, 50) {
regularPaymentServices.single { it.solutionType == PaymentSolutionType.WINTER }.pay()
regularPaymentServices.single { it.solutionType == PaymentSolutionType.KARINA }.pay()
}
val logs = externalSolutionRequestLogRepository.findAll()
// 전문번호를 기준으로 distinct 처리
val distinctSize = logs.map { it.requestMessageNumber }.distinct().size
assertThat(logs.size).isGreaterThan(distinctSize)
println("전체 개수: ${logs.size} / 중복되지 않은 전문번호 개수: $distinctSize")
}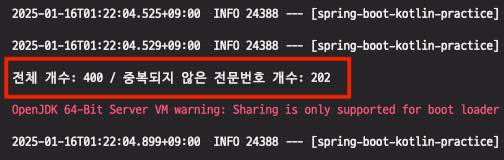
위의 사진과 같이, 전문번호를 포함한 요청은 198개가 중복 요청입니다. 실제 상황이었다면 절반에 가까운 요청이 실패한 것이죠.
(아마 동시성 테스트 관련 설정에서 디테일이 부족해서 발생한 이슈 같기도 합니다..?)
INCR을 활용하면?
@Test
fun `INCR을 사용하는 경우 동시성 이슈가 발생하지 않는다`() {
runConcurrentTask(2, 50) {
regularPaymentServices.single { it.solutionType == PaymentSolutionType.WINTER }.payWithRedisIncr()
regularPaymentServices.single { it.solutionType == PaymentSolutionType.KARINA }.payWithRedisIncr()
}
val logs = externalSolutionRequestLogRepository.findAll()
val distinctSize = logs.map { it.requestMessageNumber }.distinct().size
assertThat(logs.size).isEqualTo(distinctSize)
println("전체 개수: ${logs.size} / 중복되지 않은 전문번호 개수: $distinctSize")
}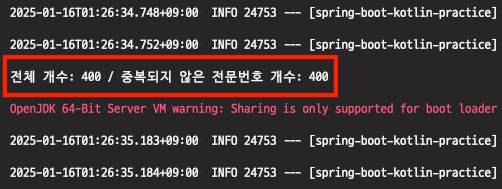
반면, INCR을 활용하여 전문번호 채번을 진행했더니 모든 요청이 전문번호 중복 없이 처리되었습니다. 동시성 이슈가 해결된 것이죠!
더 나은 해결책?
서비스가 확장한다면
현재의 서비스에서는 Redis의 INCR을 통해 동시성 이슈를 충분히 해결할 수 있을 거 같습니다. 그러나 만약 서비스가 엄~청나게 성장해서, 이런저런 서버 어플리케이션에서 전문번호 채번이 필요한 경우엔 어떻게 될까요?
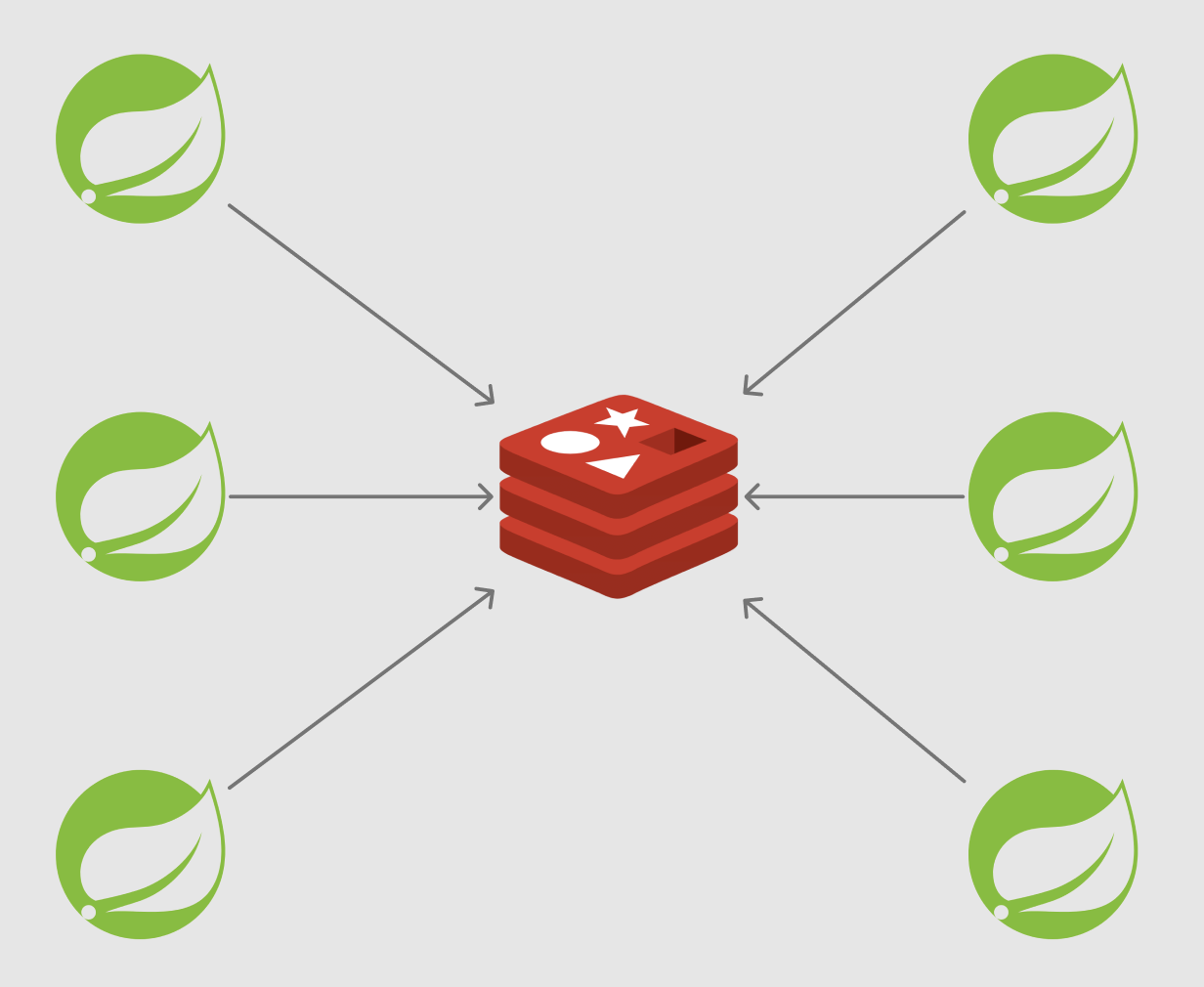
레디스에 대한 의존성, 공통 전문번호 채번을 위한 코드가 모든 어플리케이션에 퍼지게 됩니다. 썩 유쾌한 상황은 아닙니다. 만약 전문번호 채번을 위한 key 규칙에 변경이 생기는 경우, 모든 어플리케이션에서 같은 코드를 변경해 줘야 합니다.
한 곳으로 모아볼까?
외부 솔루션 처리를 하는 서버 앞단에 프록시 서버를 두는 방법은 어떨까요? 프록시 서버의 역할을 전문번호 채번으로 한정 짓는 건 아닙니다. 프록시 서버가 하는 다양한 일은 수행하되, 전문번호 채번도 함께 진행하는 것이죠. 이 경우, 여러 어플리케이션이 추가되더라도 전문번호 채번에 대한 고려는 하지 않아도 됩니다.
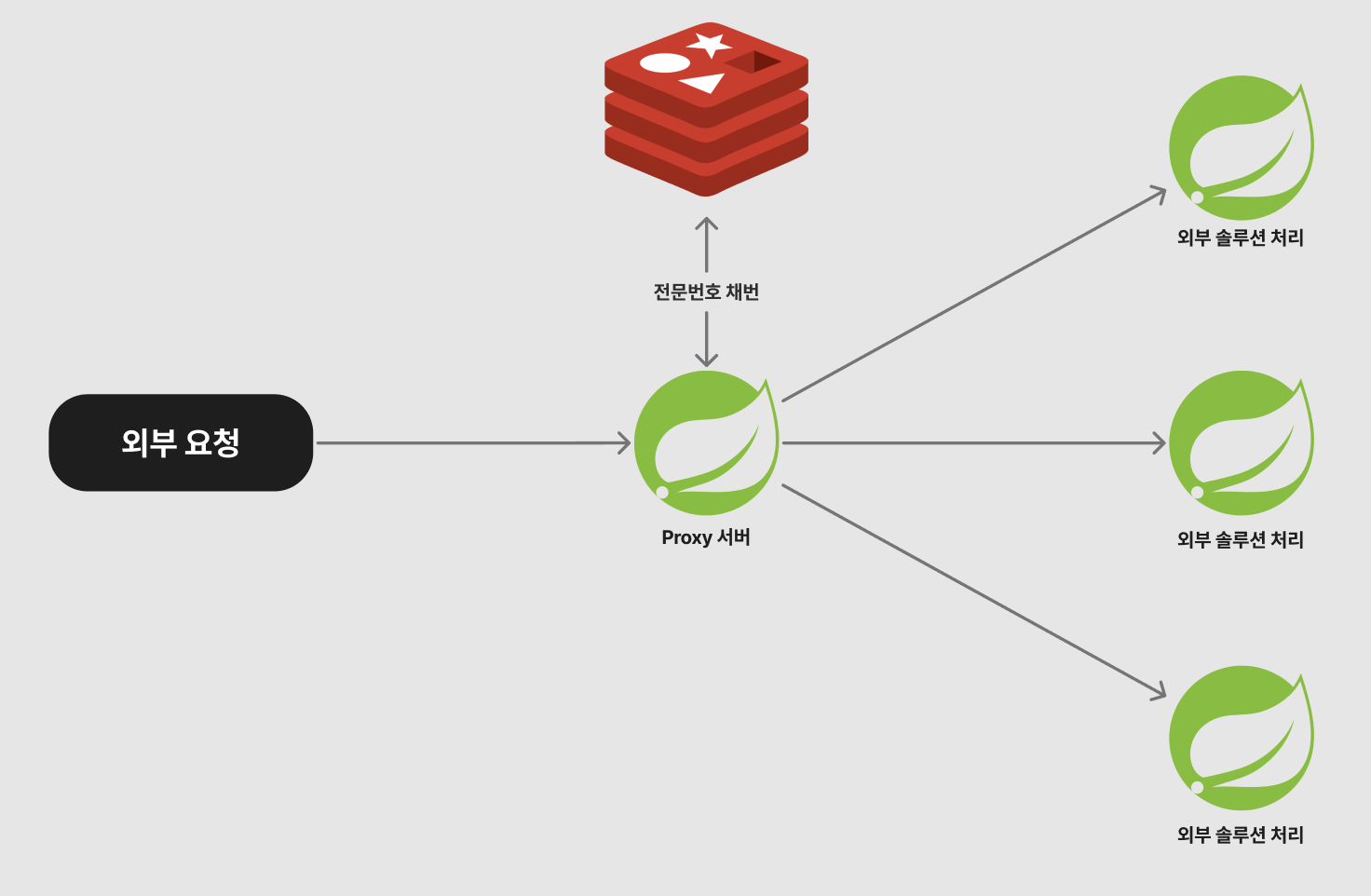
다만 이런 방식은 서비스가 상당히 커졌을 때 유효할 거 같습니다. 작은 서비스에서 도입하기엔 오버 엔지니어링 요소가 강하다고 여겨집니다.
결론
결과적으로 도입하지는 못했지만, 이 도메인에서만 발생할 수 있는 동시성 이슈에 대한 경험과 해결 방법에 대한 고민은 너무 뜻깊었습니다. 실제로 적용해 봤으면 더할 나위 없이 좋았겠지만요.
참조
박준하 토스뱅크 CTO - 전문 통신
헥토파이낸셜 개발 가이드 문서
PostgreSQL Docs 9.4.26 - UPDATE
MySQL Docs 9.1 - UPDATE
Redis Docs - INCR
레디스 incr, decr를 활용해서 동시성 테스트하기(kotlin, spring)
Redis의 Increment는 왜 원자적으로 동작하는 것일까?
