
문법도 어느정도 갖추어졌으니 인터프리터가 어떻게 구성되는지 알아봅시다.
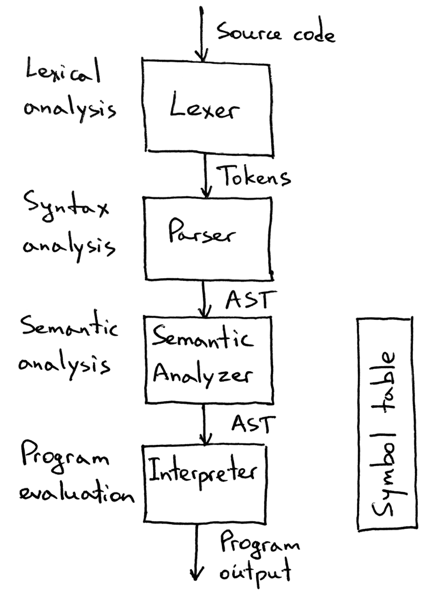
(이미지 출처: Let’s Build A Simple Interpreter. Part 13: Semantic Analysis.)
먼저 Lexer로 소스코드를 토큰 단위로 분석하고, Parser로 우선순위에 맞춰서 Abstract Syntax Tree를 만들어준 뒤, Semantic Analyzer로 Type checking 같은 의미 분석을 하고, 최종적으로 Interpreter가 연산해서 프로그램을 실행하는 것입니다.
그럼 먼저, Lexer를 만들어보도록 합시다.
0. 🚪 우리의 목표
토큰은 국어의 형태소와 비슷한 개념입니다. 형태소가 문장을 이루는 의미를 가진 가장 작은 요소인 것과 같이 토큰은 의미를 가지는 글자끼리 모아둔 소스코드를 이루는 가장 작은 요소입니다. 소스코드를 토큰으로 쪼개주는 것을 Lexer라고 합니다.
이를 테면, 다음과 같은 코드가 있습니다.
10*2+3이 코드를 다음과 같이 쪼갤 수 있어야 합니다.
NUMBER 10
STAR *
NUMBER 2
PLUS +
NUMBER 31. 🤔 토큰 구성
자 그럼 언어의 토큰들을 생각해봅시다.
토큰들은 구현할 떄마다 추가될 예정이지만, 현재 제가 구상하고 있는 토큰들을 Python Enum으로 정리하면 다음과 같습니다.
from enum import Enum, auto
class TokenType(Enum):
LEFT_PAREN = auto() # (
RIGHT_PAREN = auto() # )
LEFT_BRACE = auto() # {
RIGHT_BRACE = auto() # }
LEFT_BRACKET = auto() # [
RIGHT_BRACKET = auto() # ]
SEMICOLON = auto() # ;
COMMA = auto() # ,
DOT = auto() # .
PLUS = auto() # +
MINUS = auto() # -
STAR = auto() # *
SLASH = auto() # /
EQUAL = auto() # =
EQUAL_EQUAL = auto() # ==
EXCLAM = auto() # !
EXCLAM_EQUAL = auto() # !=
GREATER = auto() # >
GREATER_EQUAL = auto() # >=
LESS = auto() # <
LESS_EQUAL = auto() # <=
IDENTIFIER = auto() # Variable name, Function name, etc... ([a-zA-Z][a-zA-Z0-9]*)
BOOLEAN = auto() # true, false
NUMBER = auto() # Digit([0-9]+(.[0-9]*)?)
SINGLE_STRING = auto() # 'string'
DOUBLE_STRING = auto() # "string"
EOF = auto() # End of file
# Keywords
IF = 'if'
ELSE = 'else'
AND = 'and'
OR = 'or'
FUN = 'fun'
VAR = 'var'
TRUE = 'true'
FALSE = 'false'
NULL = 'null'
FOR = 'for'
WHILE = 'while'
IN = 'in'
RETURN = 'return'
@classmethod
def has_value(cls, value):
return any(value == item.value for item in cls)마지막에 has_value 메서드는 Lexer를 구현할때 키워드를 가져올떄 사용됩니다.
2. 📝 Lexer 작성
일단 Lexer 클래스를 작성해줍니다.
class Lexer:
def __init__(self, source: str):
self.source = source # 소스 코드
self.tokens = [] # 파싱된 토큰
self.start = 0 # 토큰의 시작
self.current = 0 # 토큰의 끝
self.line = 1 # 라인2.1 scan_token 메서드
토큰 하나를 분석하는 scan_token 메서드를 만들어봅시다.
def scan_token(self) -> None:
ch = self.advance()
if ch == '(':
self.add_token(TokenType.LEFT_PAREN)
elif ch == ')':
self.add_token(TokenType.RIGHT_PAREN)
elif ch == '{':
self.add_token(TokenType.LEFT_BRACE)
# ...
elif ch == '!':
self.add_token(TokenType.EXCLAM_EQUAL if self.match('=') else TokenType.EXCLAM)
elif ch == '=':
self.add_token(TokenType.EQUAL_EQUAL if self.match('=') else TokenType.EQUAL)
elif ch == '<':
self.add_token(TokenType.LESS_EQUAL if self.match('=') else TokenType.LESS)
elif ch == '>':
self.add_token(TokenType.GREATER_EQUAL if self.match('=') else TokenType.GREATER)
elif ch == '/':
if self.match('/'):
while self.peek() != '\n' and not self.is_end():
self.advance()
else:
self.add_token(TokenType.SLASH)
elif ch.isspace():
pass
elif ch == '\n':
self.line += 1
elif ch == '"' or ch == '\'':
while self.peek() != ch and not self.is_end():
if self.peek() == '\n':
self.line += 1
self.advance()
if self.is_end():
raise InvalidSyntaxError('Unterminated string')
self.advance()
self.add_token(
TokenType.DOUBLE_STRING if ch == '"' else TokenType.SINGLE_STRING,
self.source[self.start: self.current].strip(ch)
)
elif Lexer.is_digit(ch):
while Lexer.is_digit(self.peek()):
self.advance()
if self.peek() == '.':
self.advance()
while Lexer.is_digit(self.peek()):
self.advance()
self.add_token(TokenType.NUMBER, float(self.source[self.start: self.current]))
elif ch.isalpha():
while self.peek() and self.peek().isalnum():
self.advance()
text = self.source[self.start: self.current]
if TokenType.has_value(text):
self.add_token(TokenType(text))
else:
self.add_token(TokenType.IDENTIFIER)
else:
raise InvalidSyntaxError('Unexpected token: ' + ch)2.2 lex 메서드
그리고 이 토큰 찾는 것을 소스코드가 끝날때까지 반복해주는 lex 메서드를 만들어 봅시다.
def lex(self) -> List[Token]:
while not self.is_end():
self.start = self.current
self.scan_token()
self.tokens.append(Token(TokenType.EOF, ''))
return self.tokens이것이 간략하게 중요 메서드를 소개한 것이며, 자세한 코드는 여기를 참고하면 될것 같습니다.
3. ✅ 테스트 코드 작성
from rectapy import Lexer
if __name__ == '__main__':
lexer = Lexer('10*2+3')
tokens = lexer.lex()
print('\n'.join(map(str, tokens)))일단 소스코드를 넣은 상태에서 Lexer 클래스를 만들고 lex한 결과를 출력하도록 했습니다.
NUMBER 10 10.0
STAR *
NUMBER 2 2.0
PLUS +
NUMBER 3 3.0
EOF성공적이군요! 이제 다음에는 아까 말했듯이 AST라고 불리는 Parser를 짜서 Abstract Syntax Tree를 만들어볼거에요!
4. 📚 참고 문서

It's quite a pleasure to watch this project :)
Keep it going!