
내가 필요한 정보를 제공해주는 API가 없을 땐 어떻게 할까?
보통 API -> Pandas Data Frame으로 변환해서 사용할 수 있음.
없다면 web scraping 이나 web crolling 을 해야함.
web scraping 은 내가 request한 webpage를 잘 parsing 해서 필요한 데이터를 추출해내는 일!
🔣 예시: 책 쪽수 정보가 필요함
-> Yes24 스크래핑

request.get()으로 검색 결과 페이지 html을 가져올 수 있음.- 전달 받은 html 에서 도서 상세 페이지로 연결되는 링크 url 추출
- 다시
request.get()으로 도서 상세 페이지 html 가져오기 - 도서 상세 페이지 html 에서 쪽수 추출
html에서 특정 정보를 추출하는 것은 생각보다 까다롭다.
=> python 의 BeautifulSoup library 를 써보자
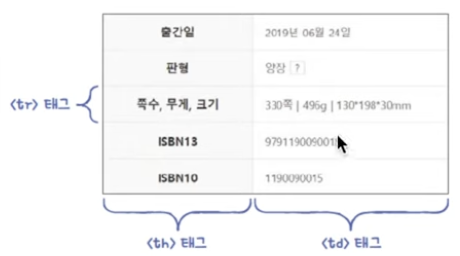
find()메서드를 사용하면 특정 attribute 값을 가진 element 를 찾을 수 있다.find_all()사용하면 해당 되는 모든 element 를 list 로 받는다.- list (여기서는 list of tr)를 iterate 하면서
tr_find('td').get_text() == "쪽수"조건문으로 원하는 데이터를 찾는다.
웹 스크래핑 주의할 점
- 유지보수하기 어려움: 웹사이트가 바뀌면 html 코드가 바뀔 것이기 때문에
- 웹사이트에서 스크래핑을 허락했는지 확인 (robots.txt)
- html 태그를 특정할 수 있는지 확인 (유사한 태그가 여러개 있진 않은지)
- 페이지가 동적으로 생성되는지 확인 (ajax 가 쓰였다면,,, 어렵다)
- 웹사이트 디자인이 자주 바뀌나요?
