
올해 2월에 대학교를 졸업한다.
컴공과 학생으로 졸업하여 AI/ML Engineer로 커리어를 시작하게 됐는데
GPT, Gemini 등의 생성형 ai와 Cursor의 바이브 코딩에 익숙해져 코딩 실력이
"이게 맞아...?"라는 생각이 뇌리에 스쳐 입사하기 전에 30일간 Python 공부를 해보려고
한다.
# [문제의 코드]
data = [1, 2, 3, 4, 5, ..., 1000000] # 아주 큰 리스트
result = []
for i in range(len(data)):
if data[i] % 2 == 0:
result.append(data[i] * 2)
else:
result.append(data[i] + 1)위의 코드는 문법적으로 완벽한 코드이다. 하지만 AI/ML 엔지니어 관점에서 이 코드는 '성능'과 '확장성'이라는 큰 숙제를 안고 있다.
이 코드는 3가지 문제가 존재한다.
-
for 루프의 속도 문제
Python의 for문은 매우 느리다. 데이터가 100만 개라면, 파이썬 인터프리터는 100만 번의 루프를 돌며 매번 객체의 타입을 확인하고 조건문을 검사한다. -
메모리 비효율성
result = []를 만들고 append()를 하는 방식은 리스트의 크기가 커질 때마다 컴퓨터가 메모리 공간을 재할당하게 만든다. -
가독성과 유지보수
range(len(data))를 써서 인덱스로 접근하는 방식은 C언어 스타일이다. Python에서는 데이터 자체를 바로 꺼내거나, 더 간결하게 표현할 수 있는 도구들이 많다.
위 코드를 2가지 방식으로 수정해 보겠다.
방법 A(List Comprehesion) -> 가장 대중적인 파이썬 스타일
result = [x * 2 if x % 2 == 0 else x + 1 for x in data]방법 B(NumPy 사용) -> AI/ML 엔지니어의 필수 스킬
import numpy as np
data_np = np.array(data)
result = np.where(data_np % 2 == 0, data_np * 2, data_np + 1)파이썬의 time 모듈을 사용해서 직접 속도를 비교해 보겠다.
import time
import numpy as np
# 1. 데이터 준비 (100만 개)
data = list(range(1000000))
# [실험 1] 일반 for문 + append 방식의 시간 측정
start = time.time()
result = []
for i in range(len(data)):
if data[i] % 2 == 0:
result.append(data[i] * 2)
else:
result.append(data[i] + 1)
print(f"일반 for문 소요 시간: {time.time() - start:.4f}초")
# [실험 2] List Comprehension 방식의 시간 측정
start = time.time()
result = [x * 2 if x % 2 == 0 else x + 1 for x in data]
print(f"List Comprehension 소요 시간: {time.time() - start:.4f}초")
# [실험 3] NumPy 방식의 시간 측정
data_np = np.array(data)
start = time.time()
result = np.where(data_np % 2 == 0, data_np * 2, data_np + 1)
print(f"NumPy 소요 시간: {time.time() - start:.4f}초")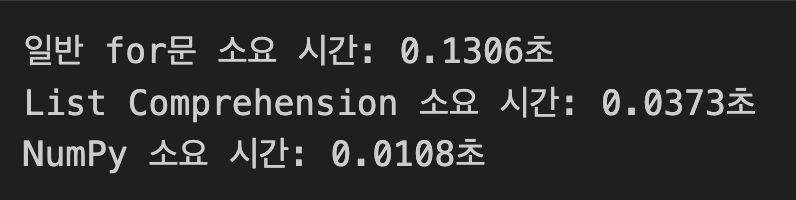
import time
import numpy as np
def compare_performance(n_samples: int):
data = list(range(n_samples))
data_np = np.array(data)
# [실험 1] 일반 for문 + append 방식의 시간 측정
start = time.time()
result = []
for i in range(len(data)):
if data[i] % 2 == 0:
result.append(data[i] * 2)
else:
result.append(data[i] + 1)
print(f"일반 for문 소요 시간: {time.time() - start:.4f}초")
# [실험 2] List Comprehension 방식의 시간 측정
start = time.time()
result = [x * 2 if x % 2 == 0 else x + 1 for x in data]
print(f"List Comprehension 소요 시간: {time.time() - start:.4f}초")
# [실험 3] NumPy 방식의 시간 측정
data_np = np.array(data)
start = time.time()
result = np.where(data_np % 2 == 0, data_np * 2, data_np + 1)
print(f"NumPy 소요 시간: {time.time() - start:.4f}초")
print(f"--- 데이터 {n_samples}개 테스트 완료 ---")
compare_performance(1000000)
compare_performance(5000000)
데이터가 커질수록 NumPy의 효율이 압도적으로 볼 수 있다.

AI/ML Engineer 🧑💻