
- 해당 글은 The SOPT 30기 글큐나 스터디를 준비하면서 kyY00n씨와 함께 작성한 글입니다.
1. GraphQL이란
- API를 만들 때 사용할 수 있는 쿼리 언어
- 쿼리에 대한 데이터를 받을 수 있는 런타임1-1. GraphQL의 탄생
2012년 페이스북 내부에서는 RESTful 서버와 FQL(페이스북의 sql) 테이블을 사용하고 있었어요. 성능도 별로였고, 앱은 자주 충돌이 났는데, 엔지니어들은 데이터를 클라이언트 애플리케이션로 전송하는 방식을 개선해야 해결할 수 있다고 결론 지었어요.
이 후 페이스북 개발 팀은 클라이언트 쪽 데이터를 다른 시각으로 바라보기 시작하면서 GraphQL을 만들기 시작했대요. 그저 페이스북의 클라이언트, 서버 애플리케이션 데이터 모델 요구사항과 기능을 정립하기 위한 쿼리 언어였어요.
2015년 7월 이 팀에서 GraphQL 초벌 명세와 graphql.js라는 자바스크립트 레퍼런스 서버를 공개했어요. 그리고 2016 9월 프리뷰 단계를 통과했다고 해요. 이미 이 시기 몇 년 전부터 페이스북에서는 GraphQL을 사내 제품에 사용했다고 해요.
현재 페이스북 내부의 데이터 페칭은 거의 다 GraphQL을 통해 이뤄지고 있고 많은 기업에서 gql을 사용하고 있다고 해요
1-2. 페이스북은 왜 GraphQL을 만들었을까
📍성능
REST 문제점
- Overfetching: 필요하지 않은 데이터를 너무 많이 받아오는 것 ⇒ 필요 없는 데이터를 전송하기 때문에 네트워크 낭비가 일어난다
- ex) SNS 친구 목록을 보여주기 위해 필요한 정보는 친구들의 ID, 이름, 프로필 사진인데 친구 목록 api를 호출하면 좋아요를 누른 페이지, 출신 등의 데이터가 함께 옴
- Underfetching: 필요한 데이터가 한 요청에 오지 않는 것 ⇒ 그래서 요청을 많이 보내야한다.
- ex ) SNS의 타임라인을 보여주기 위해 알림 정보, 사용자 정보, 타임라인 등 각 정보를 가져올 수 있는 API를 여려 번 요청해야 함
이 있죠.
이런 점들은 특정 조건에서 부하가 걸리게 하는 이유가 돼요.
GraphQL은 REST 척결자라기보다는 그저 부화완화용 쿼리언어 로 태어났다고 생각하면 좋을 것 같아요.
📍유연한 쿼리
GraphQL은 부하완화용 쿼리언어라고 했어요.
쿼리 언어 ⇒ 질의를 위해 존재하는 언어겠지요
그렇게 때문에 하나의 엔트포인트만 정의돼있어도 원하는 형태로 바꿔가며 질의하기에 좋아요.
📍미리보기
💡 viewer 라는 API 하나에서 여러 형태의 응답들을 받을 수 있어요 https://docs.github.com/en/graphql/overview/explorer# 원하는 필드만 쏙쏙 가져올 수 있어요!
query {
viewer {
name
bio
followers(first: 100) {
nodes {
login
name
}
}
}
}1-3. GraphQL의 원리
SQL이 떠오르지 않나요?
SQL처럼 GraphQL 쿼리도 데이터를 변경하거나 삭제할 때 사용하지요.
둘 다 쿼리 언어이기는 하나, 사용 환경이 완전히 달라요.
SQL은 데이터베이스로 보내고 GraphQL 쿼리는 API로 보내지요. 한 마디로 GrqphQL은 인터넷용 쿼리언어!
쿼리는 단순한 문자열로, POST 요청 본문에 담겨 GraphQL 서버 엔트포인트(custom, default: /graphq )에 전송돼요.
{
member {
name
}
}위에랑 똑같은 요청
curl 'http://localhost:5000/graphql'
-H 'Content-Type: application/json'
--data '{"query":**"{ member { name }}"**}'📍궁금티비 - 서버가 힘든 거 아녀?
gql은 sql처럼 직접 데이터를 가져올 수 있는 언어가 아니라, 서버에서 그걸 구현해줘야하잖아요
두가지 일이 있어요
- 그래프 만들어주기 ⇒ 타입 정의
- 엣지로 연결된 노드 가져오는 법 정의하기 ⇒ 리졸버 구현
gql 스키마에서는 타입의 각 필드마다 함수가 하나씩 존재하는데 그걸 리졸버라고 해요. 그리고 서버에서는 타입 리졸버를 구현해주면 되는 거죠.
→ 예시
유저 타입을 정의했고, userId로 요청하면 해당 유저를 응답으로 받는 쿼리를 추가했어요.
extend type Query {
user(userId: ID!): User
}
type User {
id: ID!
name: String
followers: [User!]!
followings: [User!]!
organization: String
}그리고 서버에서는 이런식으로 User 리졸버를 만들었을거예요.
(이건 절대절대 실제 코드가 아니에요.. 이해를 위해 완전 야매로 만들었어요)
const resolvers = {
Query: {
user: (obj, args, context, info) => {
const { id } = args;
return db.user.findById(id);
}
},
User: {
// default resolver
// name: (parent, args, context, info) => parent.name;
//
followers: parent => {
const followers = db.follower.findByTarget(parent);
return followers
},
followings: parent => {
const followings = db.follower.findByFollower(parent);
return followings
}
}
}그 상황에서 우리가 이렇게 쿼리를 짜면 리졸버가 어떻게 해결할까요 봅시다.
user("kyY00n") { # User 타입 이네? => User 타입을 맡은 리졸버를 호출하자!
name # default resolver
followers { # User 타입에서 followers를 찾는 리졸버 호출
name # default resolver
followers { # 리졸버 호출 User 타입에서 followers 를 찾는 리졸버 호출
name # default resolver
}
}
}서버에서는 User 리졸버, follower리졸버 하나씩 만들었는데 graphql 이 알아서 필드 타입을 확인하며 호출을 해주어요!
1-4. GraphQL에서 뭘 알아야 할까?
기본적으로 graphQL을 사용하는 커다란 흐름은 아래와 같아요.
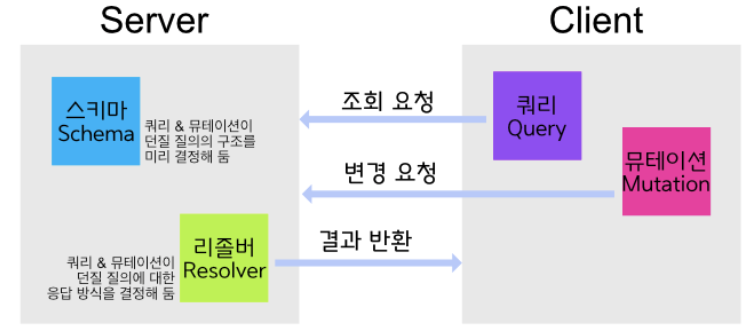
우리가 실제로 서버사이드와 클라이언트 사이드에서 GraphQL을 사용해보기 이전에 개념적으로 알아야 할 것은 크게 세 가지예요. 오늘은 넓은 시야로 대충 이런 것들이 이렇게 이렇게있다~ 정도의 큰 그림을 파악하고, 쿼리와 인스트로펙션에 대해 좀 더 자세히 알아볼 거예요.
GraphQL 자체의 구조
- 루트 타입
SQL에는 Select(read), Insert(create), Update, Delete 명령어가 있듯
GQL에도 Query(질의), Mutation(성숙) (+ Subscription, Instropection)이 있어요.
1-1. Query
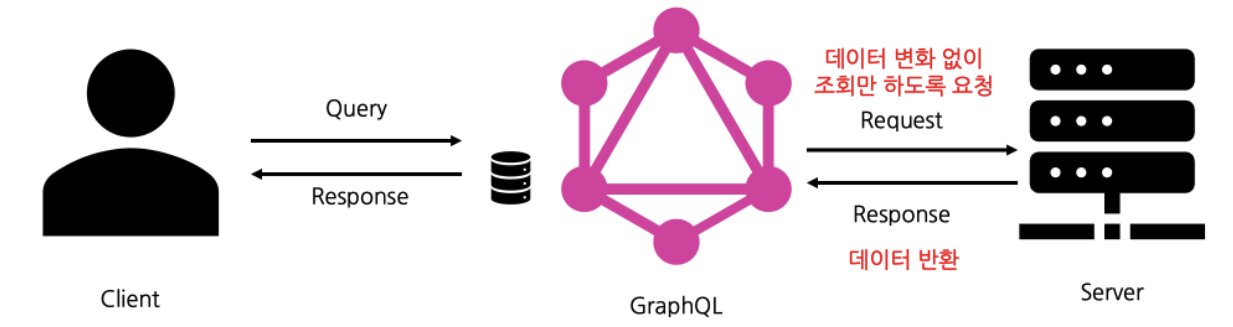
- 읽기 전용, 데이터를 가져오기 위한 메서드
- 데이터가 변화될 필요 없이 단순한 조회가 필요할 때 사용
1-2. Mutation
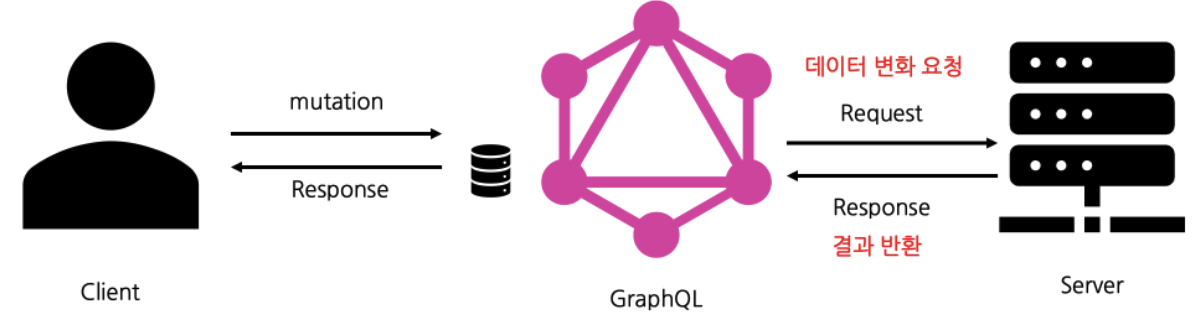
- 데이터를 변경한 후 가져오기 위한 메서드
- 요청으로 데이터를 변화시켜야 하는 경우에 사용
1-3. Subscription
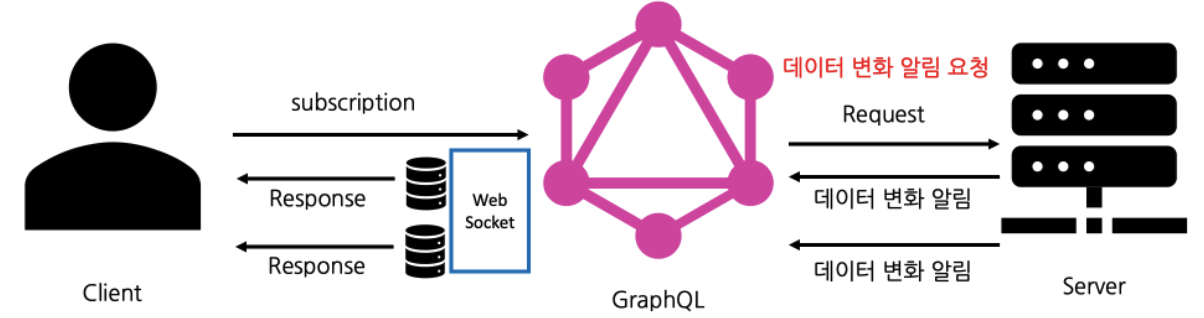
- 실시간으로 변경된 데이터를 가져오기 위한 요청 방식
- 웹소켓을 통해 소켓 통신을 열어두고, 데이터 업데이트 시 알리는 방식으로 이뤄짐
- 스키마와 타입시스템
- GraphQL 타입 시스템과 데이터를 표현하는 방법
인트로스펙션 (Introspection)
- API명세서, Swagger 없이 api 명세 공유를 할 수 있는 기적의 기능 !
오늘은 가장 흔히 쓰이는 Query에 대해 자세히 알아보고 인트로스펙션 (Introspection)이 도대체 무슨 놈인가 정도에 대해 알아보려고 해요. Mutation에 관한 부분과 타입 시스템에 대한 부분은 다음주 발표를 기대해주세요 :D
2. Query
2-1. 기본 용어 정리
query {
member {
name
}
}- Query는 루트 타입
- 타입: 하나의 작업 (읽기, 데이터 변경 등등)
- Selection set: 중괄호로 묶인 블록 필요한 필드를 중괄호로 감싸서 쿼리를 만들잖아요? 그 블록을 selection set이라 합니다.
- selection set은 서로 중첩시킬 수 있어요
query { viewer { name bio followers(first: 100) { nodes { login name } } } }
- selection set은 서로 중첩시킬 수 있어요
2-2. 인자
위에 followers 필드는 괄호안에 first 인자를 넣어주었죠
저렇게 쿼리에 필요한 인자들을 추가해주면 서버에서 받아서 api를 처리해줄 거예요.
2-3. 별칭
우리는 gql을 날렸을 때 똑같은 형태로 json 응답을 받아요. 그런데 필드 이름을 다르게 받고 싶다면 어떻게 해야할까요? 이 때 바로 별칭을 써주면 돼요. 그리고 이미 우리는 썼었어요.
query {
me: viewer {
login
organizations(first: 2) {
nodes {
name
membersWithRole(first: 10) {
nodes {
login
name
}
}
}
}
}
}+) 이럴 때 써먹으면 좋아요 - 중복 필드

별칭을 사용하면 다른 인자를 사용하여 같은 필드를 직접 쿼리 할 수도 있습니다!
2-4. 더 편하게 쿼리하기
📍 Fragment
복잡한 페이지일경우, 쿼리또한 복잡해질 수 있어요.
특히 같은 형태의 selection set을 여러번 사용하고 싶을 때가 생긴다면 그걸 저장해두고 쓰면 좋겠죠?
이럴 때 Fragment를 만들면 돼요!
{
me: viewer { # User 타입
login
organizations(first:2) {
nodes { # Organization 타입.
...OrgNameAndMembers
}
}
}
# you:
}
# OrgNameAndMembers라는 이름으로 재사용 가능한 selection set을 저장해 두고 이걸 불러와서 씀!
# fragment 프래그먼트이름 on 타입
fragment OrgNameAndMembers on Organization {
name
membersWithRole(first: 10) {
nodes {
login
name
}
}
}📍 Operation
- 루트 타입: Query(읽기), Mutation(데이터를 변경하고 가져옴), Subscription(실시간으로 변경된 데이터를 가져옴)
- 루트 타입 하나 ⇒ Operation 하나
operation 은 이름을 지정할 수 있어요.
# query를 루트 타입으로 하고, GitHubViewerInfo를 operation으로 함
query GitHubViewerInfo {
viewer {
name
bio
followers(first: 100) {
nodes {
login
name
}
}
}
}📍 변수
gql에서도 변수를 사용할 수 있어요!
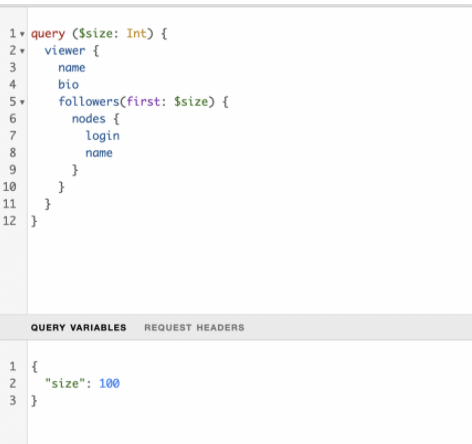
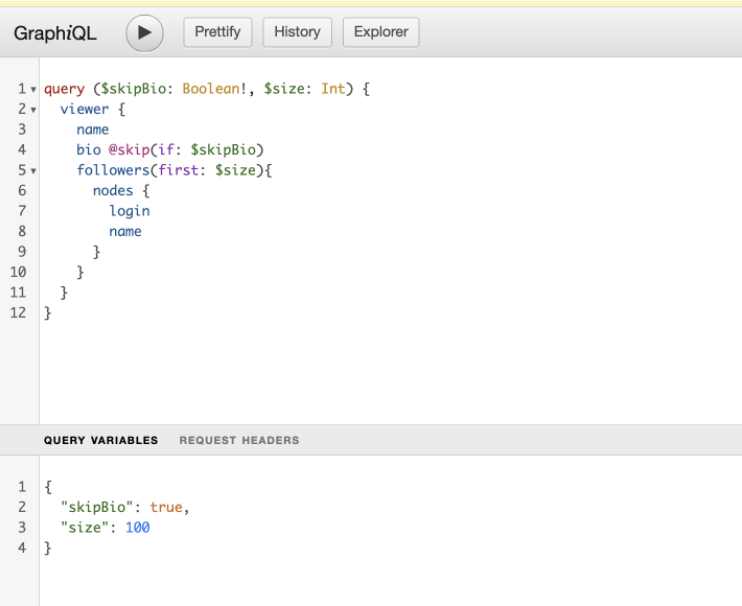
📍 Directives
쿼리와 구조, 형태를 동적으로 할 수도 있어요
• @include(if: Boolean): 인자가 true 인 경우에만 이 필드를 결과에 포함합니다.
• @skip(if: Boolean) 인자가 true 이면 이 필드를 건너뜁니다.
필드나 프래그먼트 안에 삽입될 수 있으며 서버가 원하는 방식으로 쿼리 실행에 영향을 줄 수 있어요. 이는 GraphQL 서버에서 지원해줘야 쓸 수 있어요.
skipBio에true인자를 넘겨주고 있으므로 bio필드를 건너뛰어요.
3. 인트로스펙션 (Introspection)
사실 서버 개발자 분들도, 클라이언트 개발자 분들도 프로젝트를 진행하며 API명세서 관리가 제대로 되지 않아 킹받는 상황들이 생겨본 적이 있을 거예요. (....) API 명세서를 사용하자니 api 수정할 때마다 바로바로 업데이트를 해줘야 하고 swagger를 사용하자니 부가적인 설정들을 해주어야 하고 .. 그런 문제를 해결하고자 Graphql에서는 인트로스펙션 (Introspection) 기능을 제공해주고 있어요.
gql의 인트로스펙션은 서버 자체에서 현재 서버에 정의된 스키마의 실시간 정보를 공유할 수 있게 한다.
클라이언트 사이드에서는 실시간으로 현재 서버에서 정의하고 있는 스키마에 맞게 쿼리문을 작성하면 된다.인트로스펙션용 쿼리는 일반 gql 쿼리문을 작성하듯이 작성하면 되며, 실제로는 굳이 스키마 인트로스펙션을 위해 gql을 작성할 필요가 없습니다. 대부분의 서버용 gql 라이브러리에는 쿼리용 IDE를 제공합니다. 다음 화면은 apollo server라는 서버용 gql 라이브러리에 포함 되어있는 웹 IDE 화면입니다.
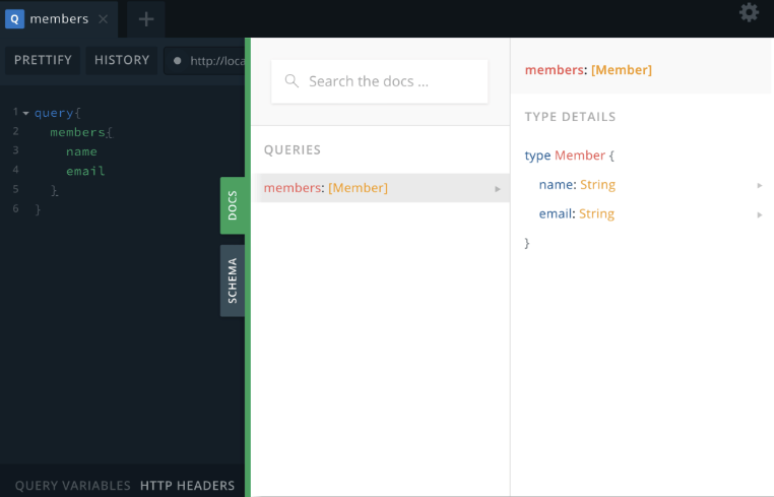
인트로스펙션을 활용하여, 직접 쿼리 및 뮤테이션, 필드 스키마를 확인할 수 있으나, 보안상의 이슈로 상용환경에서는 이러한 스키마는 공개하지 않도록 하는 것이 좋다고 합니다. 대부분의 라이브러리는 해당 기능을 켜고 끄는 옵션이 존재합니다.
추후 적용할 때 이걸 이용한다면 개발환경 상에서 클라이언트 - 서버 간의 소통이 더욱 원활할 수 있을 것 같습니다 :D



GraphQL에 대해 공부중인데 좋은 글 감사합니다!