
0. 프롤로그
블록체인 업계에서 냅다 구르던 대학생 개발자인 내가 어느날 AI 회사에서 일하게 되었다? 기초부터 톺아보는 NLP 학습기.
1. NLP 분야의 테스크들은 어떤 것들이 있을까
전제
- NLP는 인간의 언어를 컴퓨터가 이해하고 처리할 수 있도록 하는 기술분야이다.
NLP 분야에서의 테스크들은 ..
- 텍스트 분류(Text Classification): 텍스트를 사전 정의된 카테고리나 라벨로 분류하는 작업. 뉴스 기사 분류, 감정 분석 등
- 텍스트 요약(Text Summarization): 긴 텍스트를 짧고 핵심적인 내용으로 요약하는 과제
- 대화 시스템(Dialogue Systems): 인간과 자연스러운 대화를 할 수 있는 시스템을 구축하는 과제.
- 자연어 이해(Natural Language Understanding, NLU): 텍스트의 의미를 파악하고, 다양한 하위 태스크(예: 의도 파악, 문장 관계 분석 등)를 포함하여 언어의 복잡성을 이해하는 과제.
등 …
현재 회사에서 주력으로 내세우고 있는 Saas 프로덕트는 이러한 NLP분야의 테스크들에 기반하고 있다. 특히나 내가 현재 빌딩하고 있는 프로덕트는 Text Summarization와 Dialogue Systems를 통한 문장 출력 모델이 주요 모델인데, 그렇다보니 언어 생성 모델의 성능 및 출력 문장의 품질을 평가하는 것이 굉장히 중요하다. 그렇다면 NLP 테스크들의 성능은 무엇으로 어떻게 평가할 수 있을까?
2. NLP 테스크의 성능은 무엇으로 평가할 수 있는가
2-0. 전제
1. 문장의 Quality 평가 vs 문장의 Diversirty 평가
-
문장의 Quality 평가 : 각 문장의 의미가 정확한지, 문법이 맞는지, 사람이 실제로 만들만한 문장인지
-
문장의 Diversirty 평가 : 모델이 얼마나 다양한 문장을 만들 수 있는지
-
Generated 문장 : 모델이 만든 문장
- Supervised: 모델이 만든 generated문장에 Ground-truth 문장이 있는 상황에서의 평가 - 지도학습, 정답이 있는 경우
- Unsupervised: 모델이 만든 generated문장에 Ground-truth 문장이 없는 상황에서의 평가 - 비지도학습, 정답이 없는 경우
2-1. 분류 성능 평가 지표
아주 단순하게 어떤 이미지가 동물인지 아닌지 분류하는 classifier를 작성하였다고 가정해보자.
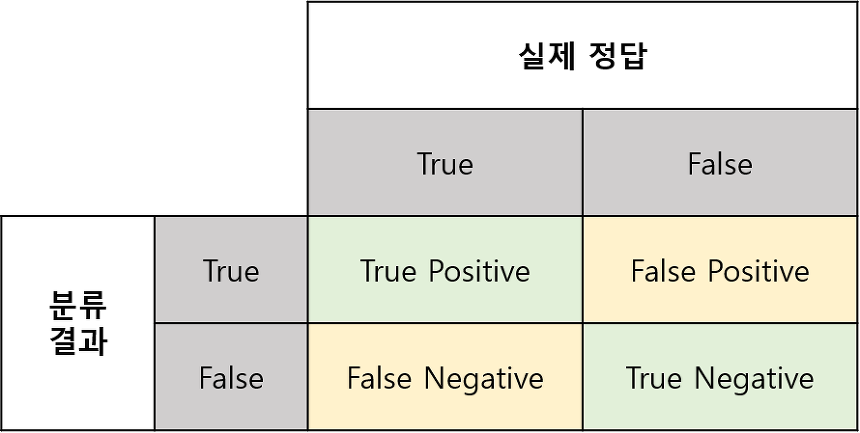
- 'True'는 모델이 맞춘 것 /'False'는 모델이 틀린 것'
- Positives'는 모델이 '예'라고 답한 것 / 'Negatives'는 '아니오'라고 답한 것
여기서 아래와 같이 분류되었다고 가정해보자.
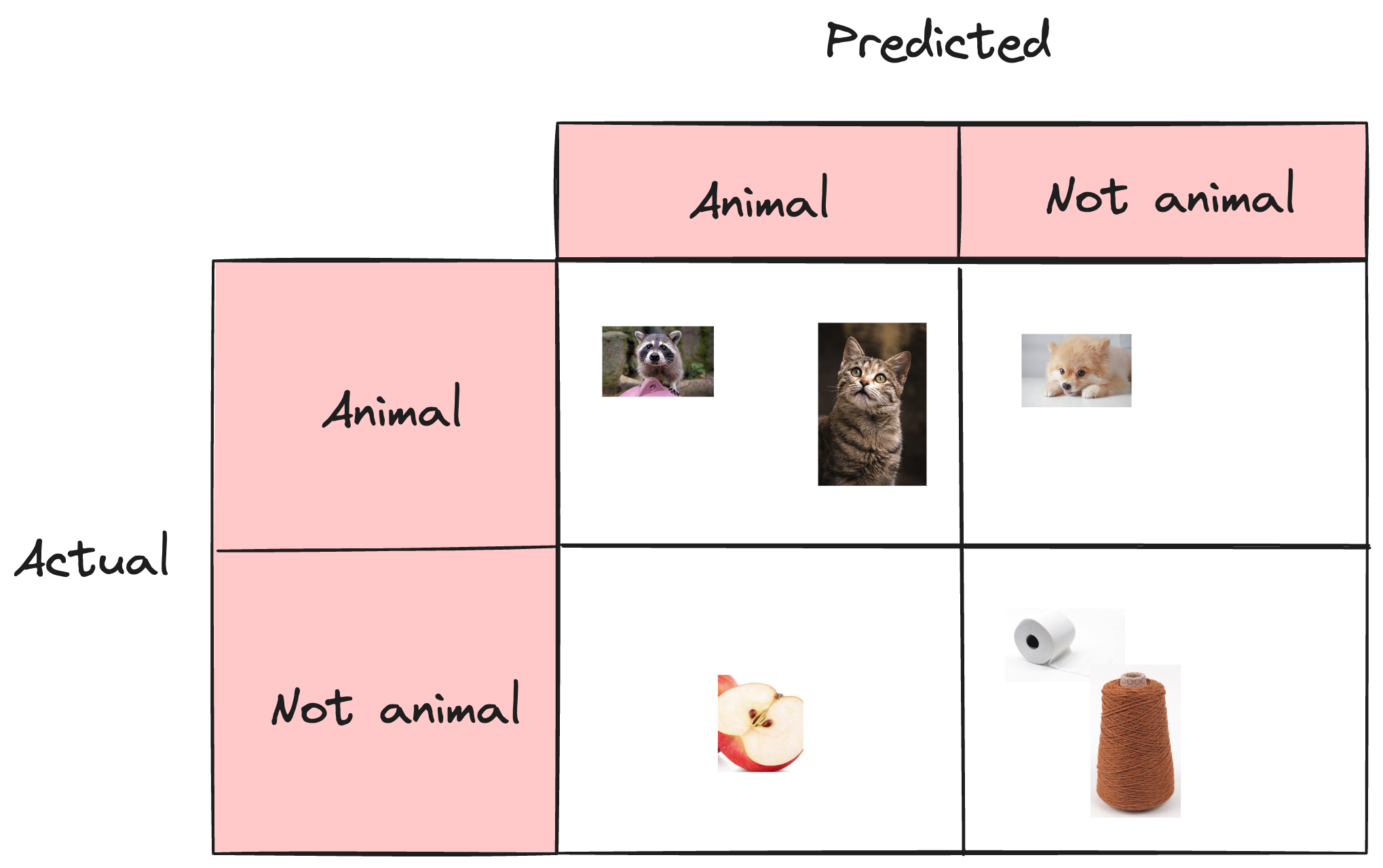
이 분류의 경우
- True Positives : 2
- True Negatives : 2
- False Positives : 1
- False Negatives : 1
일을 알 수 있다.
1. Accuracy
- Accuracy(정확도)는 올바르게 예측된 데이터의 수를 전체 데이터의 수로 나눈 값이다. 수식은 아래와 같다.
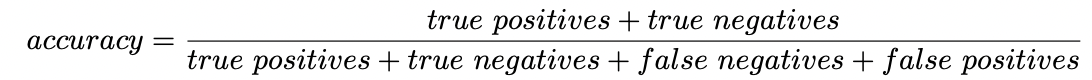
- 위의 분류의 경우 2/3의 Accuracy를 갖는다.
2. Recall
- Recall(재현율)은 실제로 True인 데이터를 모델이 True라고 인식한 데이터의 수이다.
- 내일 눈이 내릴지를 예측하는 모델에서 무조건 False를 출력하는 경우, 상당히 높은 accuracy를 갖지만, 쓸모가 없다.→ 이럴 때 Recall을 이용할 수 있다.
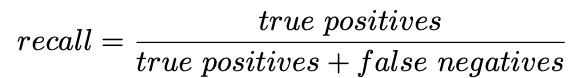
- 위의 분류의 경우 2/3의 Recall을 갖는다.
3. Precision
- 그렇지만 Recall의 경우, 항상 True를 출력하는 모델이라면 recall은 1이 되어버린다. → 이 모델은 항상 False로 예측하는 모델과 다를 바 없을 지라도 높은 recall 값을 갖게된다.
- Precision(정밀도)는 모델이 True로 예측한 데이터 중 실제로 True인 데이터의 수이다.
- 눈 예측 모델에서 항상 True로 예측하는 모델이라면 recall은 1이지만 precision은
실제로 눈이 내린 날의 수를 모델이 눈이 내릴 거라 예측한 수로 나눈 값이기 때문에 낮은 값을 갖게 된다.
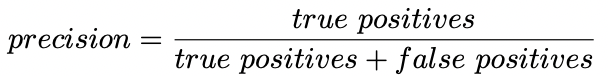
- 위의 분류의 경우 2/3의 Precision을 갖는다.
4. F1 Score
- F1 score는 precision 과 recall의 조화평균이다.
- 여기서 일반적인 평균이 아닌 조화 평균을 계산하였는데, 그 이유는 precision과 recall이
0에 가까울수록 F1 score도 동일하게 낮은 값을 갖도록 하기 위함이다.
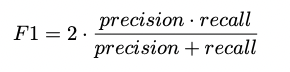
- 위의 분류의 경우 0.0370370370… 의 F1 Score를 갖는다.
결론
- 이 지표들은
sklearn의metrics모듈로부터accuracy_score,recall_score,precision_score,f1_score를 불러와 활용할 수 있다. - 만약 모델이 잘못된 예측을 많이 해도 상관이 없다면(== 많은 false positives를 보유해도 상관이 없다면, ex. 모든 스팸메일을 잡아내는 것이 목표인 모델) , 이러한 경우 precision은 별 의미가 없다 → 전적으로 위 지표들은 모델의 맥락에 달려있다.
2-2. 문장의 Quality 평가 Metrics
A. Supervised, Word-based
- 전제
- 모델이 만든 문장이 실제 정답 문장과 많이 닮을수록 좋은 문장이다.
- 두 문장에 같은 단어들이 많이 나오면, 그 두 문장은 비슷하다고 본다.
- 측정값
- 문장의 n-gram을 기반으로 한 precision, recall, f-score
- 문장의 n-gram을 기반으로 한 precision, recall, f-score
문장의 n-gram은 단어나 문자 같은 요소들이 연속적으로 이어진 일련의 조합!
ex) "나는 오늘 학교에 간다"라는 문장이 있을 때:
1-gram(유니그램): 각각의 단어나 문자를 개별적으로 봤을 때, 예를 들어 '나는', '오늘', '학교에', '간다' 처럼 각각 단어 하나하나를 의미.
2-gram(바이그램): 두 개의 단어나 문자가 연속해서 이루는 조합. '나는 오늘', '오늘 학교에', '학교에 간다'처럼 연속된 두 단어의 조합.
3-gram(트라이그램): 세 개의 단어나 문자가 연속해서 이루는 조합. '나는 오늘 학교에', '오늘 학교에 간다' 같이 연속된 세 단어를 묶어서 봄.
- 장점
- 사용하기 쉽다.
- 모델이 만든 문장과 실제 정답 문장만 있으면 되기 때문에, 복잡한 준비가 필요 없다.
- 많은 generation task 들이 이 지표들을 사용하고 있어, 다양한 태스크에서 어떻게 이 지표들을 사용했고 변형시켰는지 검색하면 잘 나온다.
- 단점
- 두 문장이 같은 단어를 사용했다고 해서 반드시 같은 의미를 갖는다고 보지 않기 때문에, 의미는 같지만 다른 단어를 사용한 경우나, 특히 한국어처럼 동사 변형이 많은 언어에서는 정확하게 평가하기 어렵다.
- 정답 문장과 비슷한 문장만이 좋은 문장이라는 가정이 틀린 경우들도 많다.
- 보완 방법
- 여러 개의 정답 문장이 있다면, 모델이 만든 문장을 각각의 정답 문장과 비교해서 평균 점수를 낼 수 있다.
- 한국어의 경우 두 문장을 형태소 단위로 나누어, 자주 등장하는 조사나 어미에 단어 수 upper limit을 두면, 의미가 담긴 단어 위주로 점수를 측정할 수 있다.
- 언제 유용한가
- 정답의 범위가 좁은 태스크 (ex. Summarization) 에서는 모델이 만든 문장에 포함되어야 할 단어가 정해져 있기 때문에 상대적으로 좋은 지표
- 정답의 범위가 넓은 태스크 (ex. Dialog generation) 에서는 실제 정답 문장과 전혀 겹치는 단어가 없어도 똑같이 말이 될 수 있기 때문에 상대적으로 나쁜 지표
- 종류
BLEUROUGEMETEOR
B. Supervised, Edit-distance-based
- 전제: 생성된 문장이 정답 문장과 얼마나 가까운지를, 문장을 바꾸기 위해 필요한 단어의 추가, 삭제, 교체 횟수로 측정 → 이 편집 횟수가 적은 문장이 좋은 문장이다.
- 장점: 가볍다.
- 단점
- Edit 할 단어들을 찾기 위해 greedy search 필요
- 상대적으로 굉장히 옛날에 나온 지표들 (WER: 1966, TER: 2006) 이고, 기존에 음성 인식 태스크에 최적화되어 등장했기 때문에 현재 여러 자연어 딥러닝 테스크에 사용하기엔 상당히 1차원적인 지표이다.
- 언제 유용한가
- Word-based metric 과 마찬가지로 답의 범위가 좁은 경우 상대적으로 괜찮은 지표이지만, 답의 범위가 넓은 경우 별로인 지표이다.
- 종류
WER- TER
- PER
C. Supervised, Embedding-based
- 전제: 정답 문장과 생성된 문장의 단어들을 벡터로 변환(== 단어 임베딩)한 뒤, 이 벡터들이 얼마나 비슷한지를 측정해서 문장의 품질을 평가한다. 벡터가 비슷하면 문장의 의미도 비슷하다고 본다.
- 측정값
- 정답 문장과 생성된 문장에서 나온 단어 벡터들 사이의 cosine similarity를 계산.
- 값이 0 에 가까우면 두 벡터는 멀리 떨어져있다, 즉 의미가 다르다.
- 값이 1 에 가까우면 두 벡터는 가깝다, 즉 의미가 비슷하다.
- 장점: 단어가 표면적으로 다르더라도 의미적 유사성을 잘 포착할 수 있다 (ex. 빠르다, 신속하다 -> 서로 다른 표현이지만 비슷한 의미를 지닌 단어들을 유사하다고 평가)
- 단점
- 문장의 길이가 길어지면 각 단어에 대한 벡터를 만들고 이들을 비교하는 계산량이 커진다.
- 단어임베딩은 그 단어의 문장에서의 위치, 같이 쓰이는 단어 등으로 만들어 지는데, 이런 경우에 완전히 의미가 바뀌는 단어도 비슷한 임베딩이 될 수 있다.
- 종류
BERTScoreEmbSimFISD
D. Supervised, Model-based
- 전제
- ground truth 문장과 generated 문장이 얼마나 비슷한지에 대한 가장 좋은 척도는 human rating.
- 이 human rating 이 달린 데이터셋으로 모델을 학습시키면 그 모델은 추후에 다른 문장 쌍이 주어져도 이 모델은 그 문장들 사이의 유사성을 사람처럼 평가할 수 있다.
- 종류
BLEURT: 구글에서 개발한 모델로 BERT같은 전처리된 언어 모델을 기반으로 하며, 대규모 데이터셋에 포함된 사람들의 평가 점수를 학습해 문장 쌍의 유사도를 평가화는 데 사용된다.
E. Upsupervised, Probability-based
- 전제
- 언어 생성 모델은 궁극적으로 각 문장에 확률값을 부여한다.
- 이 확률이 높다는 것은 문장이 자연스럽고 진짜 같다는 의미이다.
- 좋은 모델은 진짜와 같은 문장에 높은 확률을 부여할 것이다.
- 방법
- 모델에 실제 문장들을 넣어서, 모델이 이 문장들에게 얼마나 높은 확률을 부여 하는지 보는 것 (우리가 만든 문장이 아닌 실제 문장을 사용하기 때문에 이 방법은 비감독 학습에 속한다.)
- 장점
- 가볍다.
- 동일한 문장들을 넣어서 확률값을 비교했을 때, 각 모델에서 확률값이 점차 올라간다는 것은 모델의 성능이 좋아짐을 뜻한다. 즉, 모델 학습 상황을 볼 수 있다.
- 모델 간의 성능비교를 할 수 있다. 동일한 진짜 문장들을 두 모델에 넣었을 때, 이 문장들에 대해 더 높은 확률을 부여하는 모델이 이론적으로 좋은 모델이다. (사실상 객관적 비교는 어려울 수 있다.)
- 단점
- 각 generated 문장의 품질을 개별적으로 평가할 순 없다.
- 예를들어 모델의 "성능"이 90% 정도의 경우에서 좋은 문장들을 만들어 낸다 하면, 당장 내 눈 앞에 있는 문장이 나머지 10% 경우에 해당하는 나쁜 문장인지 모른다. 당장 dialog 에서 유저에게 내뱉는 말이 좋은 문장인지 아닌지 알 수 없다. -> 대부분의 경우에 좋은 문장을 만들어내더라도, 특정 문장이 좋지 않을 수도 있지만 그걸 구별하기 어렵다.
- 각 generated 문장의 품질을 개별적으로 평가할 순 없다.
- 종류
Perplexity (PPL): 모델이 문장을 얼마나 잘 이해하고 있는지를 나타내는 지표로, 낮은 PPL 값이 좋은 성능을 의미
F. Unsupervised, Model-based
- 전제
- Human evaluator 은 어떤 문장을 보고 인간이 만든 real 문장인지, 모델이 만든 fake 문장인지를 잘 알수 있을것이다.- 주어진 문장이 real 문장인지 fake 문장인지 이진분류하는 binary classifier에 우리 모델이 만든 generated 문장을 보여줬을 때 real 문장이라 분류한다면, 그것은 우리의 모델이 진짜같은 문장을 만들고 있음을 뜻한다.
- 방법
- real 문장들 set 과 fake 문장들 set을 준비한다. 이때 fake 문장들은 우리의 generation 모델에서 나오는 문장들이 아닌, 어떤 다른 문장들 이여야 한다.
- binary classifier가 이 real 문장들과 fake 문장들을 분류하도록 학습시킨다.
- 이 binary classifier에 우리 모델에서 나온 generated 문장을 넣는다. real 로 분류된다면 그 generated 문장은 좋은 문장이고, fake 로 분류된다면 그 generated 문장은 나쁜 문장이라 말할 수 있다.
- 이렇게 모든 generated 문장을 binary classifier로 inference 하여, real로 분류된 비율이 우리 생성 모델의 성능이라고 할 수 있다. - 장점
- binary classifier 에 generated 문장을 1개씩 넣어서 real / fake 으로 분류되는지를 볼수 있기 때문에, 문장 하나하나의 퀄리티를 판단할 수 있다.
- 문장을 단어 단위로 나누지 않고 문장 그 자체를 파악한다고 볼 수 있다. - 단점
- binary classifier에 매우 의존적이다.- binary classifier가 generated 문장이 fake 라고 너무 잘 분류한다면, binary classifier의 학습이 지나치게 잘 된 것인지 우리의 generation 모델이 문장을 잘 못만드는 것인지 평가하기 어렵다. 반대로 binary classifier 가 generated 문장을 real 이라고 분류하는 것이, binary classifier의 학습이 잘 안된 것인지 우리의 generation 모델이 문장을 너무 잘 만드는 것인지 평가하기 어렵다.
- 이에 따른 binary classifier의 architecture, size, 학습시킬 real/fake 데이터셋 등 여러 면에서 좋은 설계가 필요하다.
- 어떤 binary classifier를 쓸지에 대한 많은 결정이 추가적으로 필요하다 보니, 하나의 객관적 지표가 되기 어렵다. 많은 성능평가는 아직 모델을 사용하지 않는 metric 을 이용하여 진행 되고 있다.
- binary classifier가 generated 문장이 fake 라고 너무 잘 분류한다면, binary classifier의 학습이 지나치게 잘 된 것인지 우리의 generation 모델이 문장을 잘 못만드는 것인지 평가하기 어렵다. 반대로 binary classifier 가 generated 문장을 real 이라고 분류하는 것이, binary classifier의 학습이 잘 안된 것인지 우리의 generation 모델이 문장을 너무 잘 만드는 것인지 평가하기 어렵다.
- 종류
-Adversarial Evaluation
2-3. 문장의 Diversirty 평가 Metrics
A. Unsupervised, Word-based
- 전제: 모델이 만드는 문장들의 Diversity는, 각 문장에 겹치는 단어가 얼마나 있는지로 평가할수 있다.
- 장점: ground-truth 문장도 필요 없이, generated 된 문장들만 있으면 아주 쉽게 계산할수 있다.
- 단점
- Word-based Quality 평가와 같이 단어들의 semantic variation 고려하지 못함
- generation 시의 sampling hyperparameter (top_k, top_p, temperature 등) 에 의해 측정값이 많이 바뀔수 있다. → 고로 여러 모델에서 나오는 문장들의 diversity를 비교하려면 이러한 hyperparameter을 동일하게 설정하고 평가해야 한다.
- 종류
- Self-BLEU
- Distinct-N
- Unique-N
- MSTTR
A. Unsupervised, Probability-based
- 전제: 모든 generated 문장을 모았을 때 그 모음의 단어 entropy 가 크다는 것은, 문장에서 쓰인 단어가 다양하다는 뜻이다.
- 측정값: 단어 분포의 엔트로피 - 전체 문장들에서 각 n-gram이 등장한 비율을 x라 할때, shannon entropy = -(x)log(x) 를 모든 n-gram에 대해 더한 값
- 범위: (0,∞), 높을수록 좋다.
- 예시
- generated 문장1: "아니 내말은"
- 1-gram 비율: "아니"=0.5, "내말은"=0.5
- shannon entropy = -0.5log0.5 + -0.5log0.5 ~ 0.3 - generated 문장2: "아니 진짜 아니 그게 아니 라니까"
- 1-gram 비율: "아니"=0.5, "진짜"=0.17, "그게"=0.17, "라니까"=0.17
- shannon entropy = -0.5log0.5 + -0.17log0.17 + -0.17log0.17 + -0.17log0.17 ~ 0.5 - 문장2의 shannon entropy 가 더 높으므로, 문장2가 더 diverse 한 문장.
- 물론 실제로는 하나의 문장에 대해서가 아니라, 모든 generated 문장을 합쳐서, 모델이 만든 모든 문장들의 엔트로피를 계산한다.
- generated 문장1: "아니 내말은"
어떨 때 어떤 Metric을 사용해야 하는가
- 모든 metric은 각각의 한계가 있고, 하나의 측정값이 문장의 Quality나 Diversity를 말해주지 않는다.
- 각 generation model을 평가할 때에는 여러 metric 을 다양하게 써야할듯 하다.
