
Intro
이전의 회사에서 public docs를 런칭하며 검색엔진 최적화를 신경써야 하는 일이 있었다! 그래서 web.dev 사이트의 Easily discoverable 파트의 아티클들을 읽고, 검색 엔진 최적화 방식에 대해 이해하기 쉽도록 정리해보았다
-
관련 링크
https://web.dev/how-search-works/
https://web.dev/pass-lighthouse-seo-audit/
https://developers.google.com/search/docs/fundamentals/seo-starter-guide#promote
1. 검색 작동 방식
💡 전제 : 웹에서 최대한 많은 정보를 얻어야 함 → 검색 엔진은 사이트 간에 이동하며 크롤러를 사용크롤러가 웹을 탐색하고 검색 엔진이 동작하는 방식
- 문서의 상태를 확인하기 위해 URL을 가져오려고 시도
- 오류코드를 반환하면 해당 콘텐츠 사용 불가
- 공개적으로 엑세스 할 수 있는 문서만 인덱스에 포함
- 여기서는 HTML에 언급된 모든 콘텐츠 (이미지, 비디오, js 등)들이 포함
- 링크된 URL을 방문할 수 있도록 HTML 문서에서 링크를 추출 → 적극적으로 링크나 버튼을 클릭하지 않고, 나중에 크롤링 할 수 있도록 대기열에 URL을 보냄! 그러나 이러한 새 URL에 엑세스 할 때 쿠키, 서비스 워커 혹은 로컬 저장소를 사용할 수 없다.
- 문서를 검색한 이후 크롤러는 해당 콘텐츠를 검색 엔진에 전달해 인덱스에 추가
- 검색 엔진은 콘텐츠를 이해하기 위해 렌더링하고 분석
- 이때 렌더링은 브라우저처럼 페이지를 표시하는 것을 의미하는데, 일부제한 이 있다고 함
- 키워드, 타이틀, 링크, 헤딩, 글자 등등을 보는데 이때 그 내용과 페이지의 맥락을 표현하는 것을 시그널이라고 함 → 시그널을 통해 검색엔지는 가능한 최상단의 페이지로 주어진 쿼리에 응답할 수 있음
- 검색엔진은 그 중에 가장 유용한 결과를 제공함
- 단순히 쿼리를 인덱스 키워드와 일치시키는 것이 아닌, 컨텍스트, 대체 문구, 사용자 위치 등을 고려함
- 페이지 순위 지정 혹은 순서 지정은 쿼리를 기반으로 발생
2. 검색 엔진 최적화를 위한 가이드
💡 구체적인 메타 테그 작성 등 가이드 : lighthouse-seo
💡 대표적 검색엔진 관련 가이드To learn more, check out Google's I/O talks:
- Build a successful web presence with Google Search
- Deliver search-friendly JavaScript-powered websites
2-1. Google Search 3단계
- 크롤링
- 기본적으로 방문 페이지를 렌더링 하여 발견된 자바스크립트를 실행함.
- 문제가 생긴다면, 서버 문제 / 네트워크 문제 / robots.txt 지시어 문제로 인해 크롤링이 막혀있거나
- 인덱스 생성
- 페이지의 내용을 파악함. 기본적으로 href의 링크는 대기열로 보내지는데 nofollow 옵션을 통해 막을 수 있음.
- 인덱스 생성과 관련해 문제가 생긴다면 일반적으로는 페이지 콘텐츠의 품질이 낮거나 / robots.txt 지시어가 인덱스 생성을 허용하지 않거나 / 웹사이트 디자인으로 인해 인덱스 생성이 어렵거나
- 검색 결과 게재
- 사용자가 검색어를 입력하면 구글 컴퓨터는 인덱스에서 페이지를 검색한 다음 품질이 가장 높고 관련성이 크다고 판단되는 결과를 반환
- 문제가 생긴다면 → 페이지 콘텐츠가 사용자랑 관련이 없음 / 콘텐츠 품질이 낮음 / robots.txt 지시어가 게재를 차단
2-2. 검색 엔진 최적화 방법
-
내 페이지의 인덱스가 생성되었는지 확인하기
site:example.com로 검색해보기
-
구글이 내 콘텐츠를 찾을 수 있도록 돕기
-
크롤링 하고 싶지 않은 페이지 알리기
-
robots.txt를 사용하여 알리기
# brandonsbaseballcards.com/robots.txt # Tell Google not to crawl any URLs in the shopping cart or images in the icons folder, # because they won't be useful in Google Search results. User-agent: googlebot Disallow: /checkout/ Disallow: /icons/ -
robots.txt의 한계: 크롤러에게 크롤링 대상이 아니라는 것은 알려줄 수 있지만, 페이지 게시 자체를 막진 않음 → 내가 크롤링을 막아둔 링크가 인터넷 어딘가 존재한다면 계속 참조되어 뜰 수 있음
-
그리고 robots.txt를 준수하지 않는 좀 모지란 검색엔진에서는 지시어를 따르지 않을 수 있음
-
결론
- 페이지가 구글에 표시되길 원칠 않지만, 링크를 알게된 사용자가 페이지 접근하는 것은 괜찮다면
noindex테그 사용 - 실제 접근 자체의 보안을 강화하려면 사용자 비밀번호를 요구
- 페이지가 구글에 표시되길 원칠 않지만, 링크를 알게된 사용자가 페이지 접근하는 것은 괜찮다면
-
-
구글 및 사용자가 내 콘텐츠를 이해할 수 있도록 돕기
- url 검사도구 이용하는 게 좋다고 함 ~ https://support.google.com/webmasters/answer/9012289
- 시맨틱하게 테그 이용하기
- 각 페이지에 고유한 요소 만들기
- 간단하지만 설명이 담긴 요소 사용하기
- 메타 설명테그 사용해 각 페이지별 콘텐츠 정확하게 요약하기 -? 각 페이지마다 콘텐츠를 기반으로 메타 설명 테그 자동으로 생성 가능
- 의미 있는 표제 테그를 사용하 계층 구조 만들기
-
구조화된 마크업 이용하기
- 예시
- 코드
<html> <head> <title>Apple Pie by Grandma</title> <script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Recipe", "name": "Apple Pie by Grandma", "author": "Elaine Smith", "image": "https://images.edge-generalmills.com/56459281-6fe6-4d9d-984f-385c9488d824.jpg", "description": "A classic apple pie.", "aggregateRating": { "@type": "AggregateRating", "ratingValue": "4.8", "reviewCount": "7462", "bestRating": "5", "worstRating": "1" }, "prepTime": "PT30M", "totalTime": "PT1H30M", "recipeYield": "8", "nutrition": { "@type": "NutritionInformation", "calories": "512 calories" }, "recipeIngredient": [ "1 box refrigerated pie crusts, softened as directed on box", "6 cups thinly sliced, peeled apples (6 medium)" ] } </script> </head> <body> </body> </html> - 노출 이미지
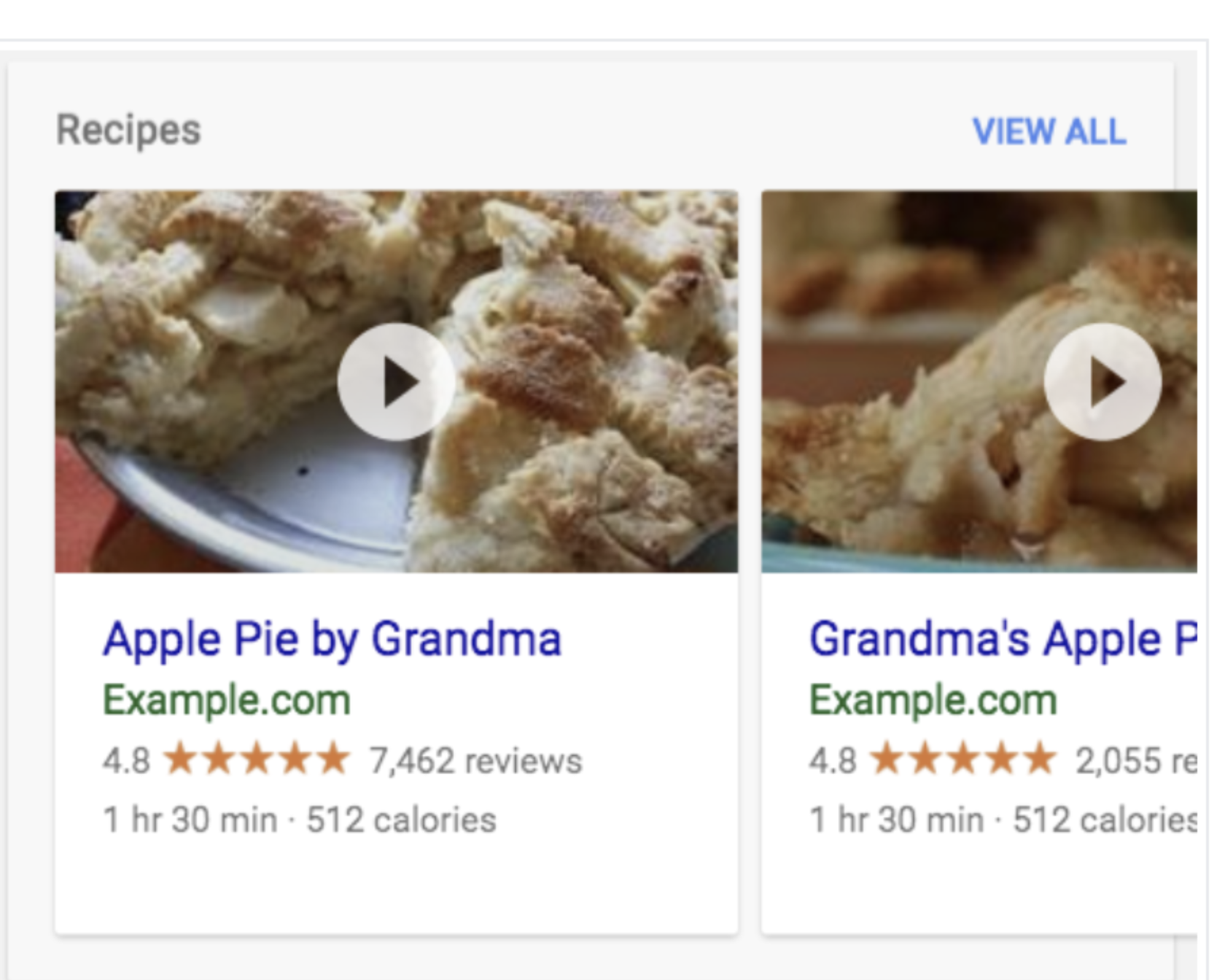
- 코드
- 단순히 사이트 설명만 기재되는 것이 아닌, 위치, 판매중인 제품, 영업 시간 등이 예쁘장하게 나올 수 있다!
- 리치 결과 테스트 를 통해 구현에 실수가 없는지 확인 가능
- 예시
-
사이트 계층 구조 구성하기
- 검색엔진에 있어서 탐색기능은 중요하다
- 다른 페이지들을 한 눈에 탐색할 수 있는 탐색페이지가 있으면 좋은데 → 탐색할 때 스크립트 기반의 이벤트 처리를 요구하는 것은 피하는 것이 좋다
- 404 페이지 표시하기
- 콘텐츠 정보를 전달하는 URL 사용하기
-
콘텐츠 최적화하기 - 좋은 콘텐츠, 독창적인 콘텐츠 ~
-
링크를 현명하게 사용하기
-
앵커 텍스트를 지나치게 일반적으로 쓰지 말 것
-
But. 내 사이트를 다른 사이트에 링크하면 내 사이트의 평판 중 일부를 해당 사이트에 넘겨주게 됩니다. 때때로 내 사이트의 댓글 섹션이나 메시지 보드에 자신의 사이트로 연결되는 링크를 추가함으로써 이를 노리는 사용자도 있습니다. 또는 특정 사이트를 부정적으로 언급하거나 해당 사이트에 내 사이트의 평판을 넘겨주고 싶지 않은 경우도 있습니다. → a테그의 다양한 rel 속성을 사용
// nofollow <a rel="nofollow" href="https://cheese.example.com/Appenzeller_cheese">Appenzeller</a> // 사용자 제작 콘텐츠 링크에 대한 처리 <a rel="ugc" href="https://cheese.example.com/Appenzeller_cheese">Appenzeller</a> // 광고나 유료 링크에 대한 <a rel="sponsored" href="https://cheese.example.com/Appenzeller_cheese">Appenzeller</a>- 모든 링크를 nofollow 사용하고 싶다면
<meta name="robots" content="nofollow">
- 모든 링크를 nofollow 사용하고 싶다면
-
내 글에 스팸 댓글을 단 경우 내 평판이 해당 스팸 댓글에 링크된 사이트에 넘겨주지 않도록 보장할 수 있음 (댓글 열 및 메시지 보드에
nofollow를 추가)
-
-
- 인덱스 생성할 이미지는 img 테그 혹은 picture 테그 사용하기 , alt 기재
- 이미지 사이트맵 이용해 검색엔진을 돕기
- 기존 사이트맵에 추가하거나 따로 전용 사이트맵을 만들 수 있음
- 예시
<?xml version="1.0" encoding="UTF-8"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:image="http://www.google.com/schemas/sitemap-image/1.1"> <url> <loc>http://example.com/sample1.html</loc> <image:image> <image:loc>http://example.com/image.jpg</image:loc> </image:image> <image:image> <image:loc>http://example.com/photo.jpg</image:loc> </image:image> </url> <url> <loc>http://example.com/sample2.html</loc> <image:image> <image:loc>http://example.com/picture.jpg</image:loc> </image:image> </url> </urlset>
- 표준 이미지 형식 사용 : JPEG, GIF, PNG, BMP, WebP
-
- 반응형 웹 디자인(권장) - 우리가 아는 그 반응형
- 동적 게재 - 동일한 url에서 클라이언트 기기에 따라 다른 HTML로 응답 )
Vary HTTP헤더를 통해 캐시에서 페이지를 게재할 지 결정할 때 클라이언트를 고려해야한다는 사실을 알림 / 이 헤더 자체가 모바일에 최적화된 콘텐츠를 게재하는 URL 크롤링에 사용되는 신호 중 하나임- 그렇지만 스니핑되기 쉬움
- 다양한 문제들…
- 별도 URL
- 공통적으로 지켜야 할 것
- 모바일 사이트에 대해 구글에 알리기 !
- 반응형 웹 디자인을 사용하는 경우
meta name="viewport"
태그를 사용하여 브라우저에 콘텐츠 조정 방법을 알리기 - 리소스를 크롤링할 수 있는 상태로 유지. 리소스를 차단해버리면 모바일 친화적인지 자체를 감지할 수 없음
- 모바일 방문자 불편하게 하지 말아라 ! - 모바일에서 재생되지 않는 동영상 포함하는 둥..
- 모바일 전체페이지 전면 광고 등, 불만을 초래하는 모바일 페이지가 있으면 순위 낮아짐
- 모든 기기 모든 기능 제공해라 ! - 웹사이트에서 제공하는 것을 모바일에서도
- 데스크톱의 구조화된 데이터, 이미지, 동영상, 메타데이터가 모바일 사이트에도 포함되는지 확인하기
- 모바일 친화성 테스트 이용하기 ~ https://search.google.com/test/mobile-friendly
-
- 내 사이트로 연결되는 링크 → 점진적으로 추가
- 내 사이트를 사람들이 링크함에 따라 더 많은 유입
-
검색 실적 및 사용자 행동 분석하기
3. 검색 엔진 최적화를 측정하는 방법
Lighthouse
- 가장 기본적인 첫번째 검사
- Google bot이 웹페이지를 보는 방식을 정확하게 나타내지는 않음
- 브라우저 및 Lighthouse는
robots.txt네트워크에서 리소스를 가져올 수 있는지 여부를 결정하는 데 사용하지 않지만 Googlebot은 사용
- 브라우저 및 Lighthouse는
Google 검색 테스트 도구로 페이지 확인
- 구글은 구글봇이 웹 콘텐츠를 어떻게 보는 지에 대해 테스트할 수 있는 툴을 제공
- 모바일 친화성 테스트 를 통해 모바일 친화성을 보장할 수 있는지 테스트해줌
- 리치 결과 테스트 : 구조화된 데이터 가 리치 결과에 적합한지 확인해줌
- AMP 테스트 : AMP HTML을 검증 … 구글이 만든 모바일 전용 빠른 웹페이지를 의미하는 .. 모바일 콘텐츠 최적화 표준임을 검증
- Google Search Console : 사이트 상태 조사
4. 정리
→ 검색 작동 개괄
- 크롤링 → 인덱스 생성 → 검색 결과 게재
→ 검색엔진 최적화 하려면 ?
- 내 페이지 인덱스 생성 됐는지 site:내사이트 로 확인하기
- 사이트맵으로 콘텐츠 찾을 수 있도록 돕기 ~ url 검사도구 이용
- 크롤링 하고 싶지 않은 페이지 알리기 - robots.txt / noindex테그 / 비번 걸어버리기
- 시맨틱한 테그 쓰기
- 구조화된 마크업 써서 다양하게 나오도록 ~ 리치 검색 결과 테스트
- 사이트 계층 구조 신경쓰기
- 콘텐츠 최적화
- 링크 현명하게 사용 - rel 속성 ) nofollow, sponsered 등
- 이미지 최적화해서 잘 찾을 수 있도록
- 모바일 친화적으로
- 웹사이트 홍보해서 링크 많이 되도록 ~
- 검색 실적, 사용자 행동 분석 ~ search console 페이지 이용
→ 검사 도구들 모음
- 구글 url 검사도구 : https://support.google.com/webmasters/answer/9012289
- 리치 검색 결과 테스트 : https://search.google.com/test/rich-results
- 모바일 친화성 테스트 : https://search.google.com/test/mobile-friendly
- 검색 실적 및 사용자 행동 분석하기 : https://search.google.com/search-console/welcome
- robots.txt 테스터 : https://www.google.com/webmasters/tools/robots-testing-tool?utm_source=support.google.com/webmasters/&utm_medium=referral&utm_campaign= 6062598

정리되어 보기 편해요 :)