[unispace] Friend의 API 하나를 개발하던 중 발견한 조회 성능 문제를 해결하는 과정.
처음 작성한 코드
| ID | Endpoint | Description |
|---|---|---|
| SFR_FRD08 | GET /friend/requests/sent | 내가 전송한 친구 요청 목록 조회 |
이 API는 내가 전송한 친구 요청을 조회하는 기능을 가진다. 두 가지 상태의 데이터를 쿼리 해야한다.
- 내가 전송한 친구 요청을 상대방이 아직 수락하지 않은 경우 (PENDING 상태)
| REQUEST_USER_ID | RECEIVE_USER_ID | STATUS | REJECTED_USER_ID | ACCEPTED_USER_ID |
|---|---|---|---|---|
| 나의 ID | 상대방의 ID | PENDING | NULL | NULL |
| 상대방의 ID | 나의 ID | REJECTED | NULL | NULL |
REQUEST_USER_ID는 API를 요청하는 사용자의 ID와 같고, 동시에 STATUS가 PENDING인 경우를 모두 조회하는 간단한 형태의 쿼리를 작성 할 수 있었다.
- 내가 전송한 친구 요청을 상대방이 거절한 경우 (REJECTED 상태)
| REQUEST_USER_ID | RECEIVE_USER_ID | STATUS | REJECTED_USER_ID | ACCEPTED_USER_ID |
|---|---|---|---|---|
| 나의 ID | 상대방의 ID | REJECTED | 상대방의 ID | NULL |
| 상대방의 ID | 나의 ID | REJECTED | 상대방의 ID | NULL |
만약 상대방이 친구 요청을 거절한 경우, 양방향 레코드의 STATUS가 모두 REJECTED로 초기화 되며, REJECTED_USER_ID에 거절한 상대방의 ID를 초기화 함으로써 누가 요청을 보냈고, 누구에 의해서 거절당한 것인지 확인 할 수 있다.
즉 내가 보낸 요청을 상대방이 거절한 경우를 조회하기 위해서는 REQUEST_USER_ID를 내 ID로 지정하고, STATUS 가 PENDING이며 REJECTED_USER_ID가 RECEIVE_USER_ID와 동일한 데이터를 조회하면 된다.
리포지토리와 서비스 계층 작성
처음에는 다른 서비스 메서드에서 사용하던 조회 쿼리를 재사용하려 했다.
@Query("SELECT f FROM Friend f " +
"WHERE f.requestUser.id = :requestUserId AND f.status = :status")
List<Friend> findByRequestUserAndStatus(
@Param("requestUserId") Long requestUserID,
@Param("status") FriendStatus status);이를 바탕으로 서비스 계층을 다음과 같이 구현했다.
public List<Response> getSentFriendRequestV1(Long userId) {
List<Response> pendingRequests = friendRepository.findByRequestUserAndStatus(userId, FriendStatus.PENDING)
.stream()
.map(friend ->
new SentFriendRequestResponse(friend.getReceiveUser().getId(),
friend.getReceiveUser().getNickname(),
friend.getStatus()))
.toList();
List<Response> rejectedRequests = friendRepository.findByRequestUserAndStatus(userId, FriendStatus.REJECTED)
.stream()
.filter(friend -> Objects.equals(friend.getRejectUserId(), friend.getReceiveUser().getId()))
.map(friend ->
new SentFriendRequestResponse(friend.getReceiveUser().getId(),
friend.getReceiveUser().getNickname,
FriendStatus.REJECTED))
.collect(Collectors.toList());
pendingRequests.addAll(rejectedRequests);
return pendingRequests;
}데이터베이스에 더미 데이터를 삽입하고 코드를 실행해 봤더니 내 생각보다 많은 쿼리가 발생했다.
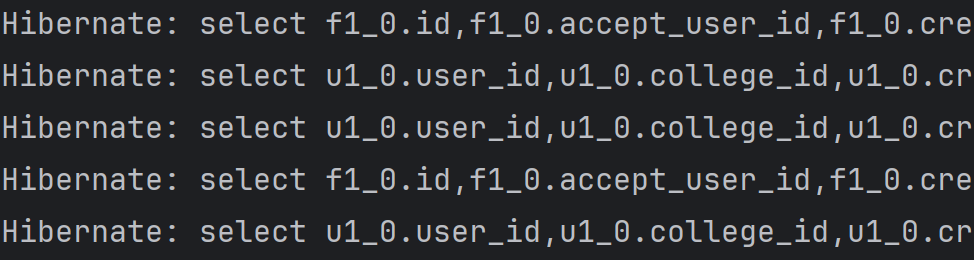
findByRequestUserAndStatus() 메서드를 사용하는 다른 메소드에서는 발생하지 않았던 문제가 생겼다. 결과를 출력하기 위해 User 엔티티의 id와 nickname을 초기화해야 했는데, 이로 인해 Friend와 User의 연관관계에 의한 N+1 문제가 발생했다.
// Friend를 조회하는 1개의 쿼리
friendRepository.findByRequestUserAndStatus(userId, FriendStatus.PENDING)
// Friend와 연관관계에 있는 User를 초기화하기 위한 N개의 추가 조회 쿼리
friend.getReceiveUser().getId(), friend.getReceiveUser().getNickname(){
"receiveUserId": 2,
"receiveUserNickname": "김철수",
"status": "PENDING"
},
{
"receiveUserId": 3,
"receiveUserNickname": "김영희",
"status": "PENDING"
},
{
"receiveUserId": 1,
"receiveUserNickname": "홍길동",
"status": "REJECTED"
}PENDING 상태의 Friend 레코드를 불러오기 위한 쿼리 1개 + 쿼리의 결과 N1개의 레코드가 불러와졌고, 해당하는 레코드와 연관된 receiveUser의 Id와 nickname을 불러오기 위해 User 테이블을 조회하는 쿼리 N1개
REJECTED 상태의 Friend 레코드를 불러오기 위한 쿼리 1개 + 쿼리의 결과 N2개의 레코드가 불러와졌고, 해당하는 레코드와 연관된 receiveUser의 Id와 nickname을 불러오기 위해 User 테이블을 조회하는 쿼리 N2개
결과적으로, 2 + N1 + N2 개의 조회 쿼리가 발생한다.
FETCH JOIN을 통한 조회 성능 최적화
N+1 문제를 해결하기 위해 패치 조인을 이용한 새로운 쿼리 메소드를 작성했다
@Query("SELECT f FROM Friend f " +
"JOIN FETCH f.receiveUser " +
"WHERE f.requestUser.id = :requestUserId AND f.status IN :statuses")
List<Friend> findByRequestUserAndStatusWithReceiveUser(
@Param("requestUserId") Long requestUserId,
@Param("statuses") List<FriendStatus> statuses);이 쿼리 메소드는 Friend 테이블을 조회하면서 동시에 receiveUser가 가리키는 User 엔티티를 함께 조회한다. 또한 JPQL의 IN 절을 활용하여 PENDING과 REJECTED 상태를 한 번에 조회할 수 있게 했다.
서비스 계층도 이에 맞춰 수정했다.
public List<Response> getSentFriendRequestV3(Long userId) {
List<Friend> friends = friendRepository.findByRequestUserAndStatusWithReceiveUser(userId, Arrays.asList(FriendStatus.PENDING, FriendStatus.REJECTED));
return friends.stream()
.map(friend -> {
FriendStatus status = friend.getStatus();
if (status == FriendStatus.REJECTED && !Objects.equals(friend.getRejectUserId(), friend.getReceiveUser().getId())) {
return null;
}
return new Response(friend.getReceiveUser().getId(), friend.getReceiveUser().getNickname(), status);
})
.filter(Objects::nonNull)
.collect(Collectors.toList());
}쿼리 결과

조인 패치를 통해 receiveUser가 가리키는 User 엔티티를 동시에 조회하고 영속성 컨텍스트에 등록하기 때문에 추가적인 N개의 쿼리가 발생하지 않는다.
결과적으로 2 + N1 + N2개의 쿼리가 하나로 줄었다.
느낀점
이번 경험을 통해 성능 최적화의 중요성을 실감했다. 처음 코드를 작성할 때는 단순히 기능 구현에만 집중해서 성능 문제를 간과했다. 코드가 정상적으로 동작하는 것을 확인하고 기뻤었는데, 콘솔창의 쿼리 로그를 보고 충격을 받았다.
한편으로는 유명한 N+1 문제를 내가 작성한 코드에서 직접 마주하게 되서 흥미로웠다. 책과 강의에서 배운 대로 조인 패치를 이용한 JPQL을 작성했고, 쿼리 수가 하나로 줄어든 결과를 보며 성취감을 느꼈다.
이번 일을 통해 몇 가지 중요한 교훈을 얻었다:
- 구현에만 집중하지 말고, 성능도 함께 고려해야 한다.
- 특히 연관관계가 있는 엔티티를 다루는 API의 경우, 설계 단계에서부터 성능을 고려해야 한다.
- N+1 문제와 같은 성능 이슈는 실제 데이터로 테스트해봐야 발견할 수 있다.
- 성능 최적화 기법을 적절히 활용하면 큰 성능 향상을 얻을 수 있다.
앞으로는 API를 개발할 때 구현과 성능을 동시에 고려하며, 테스트 단계에서 성능 검증도 꼭 수행해야겠다. 또 기존에 개발한 API들도 성능을 검토하고 필요하다면 최적화를 진행할 계획이다. 이번 경험이 더 나은 개발자로 성장하는 데 큰 도움이 될 것 같다.
