서론
미리 알고 가야하는 사항
- 이번에 이론적인 내용, 실습적인 코드를 경험하면서 작성한 내용입니다.
- 저보다 이론적이고, 실습적인 부분은 다른 블로그 들이나 책에서 더 잘 정리가 되어 있지만, 그래도 제가 처음으로 직접 경험하고 느꼈던 생각과 궁금했던 점들을 적어 두도록 하겠습니다.
공부 방법
- 나는 클린 아키텍처를 도입하기 전에 블로그에 있는 글도 많이 확인했는데 주로 두가지 책을 추천해 주었다.
- 만들면서 배우는 클린 아키텍처
- 클린 아키텍처
- 두가지 책을 많이 추천해 주기에 서점에서 두가지를 보았는데 1번인 만들면서 배우는 클린 아키텍처가 입문용으로 좋아보여 1번 서적으로 공부를 하였습니다.
- 추가적으로 블로그 참고를 많이 하였습니다.
본론
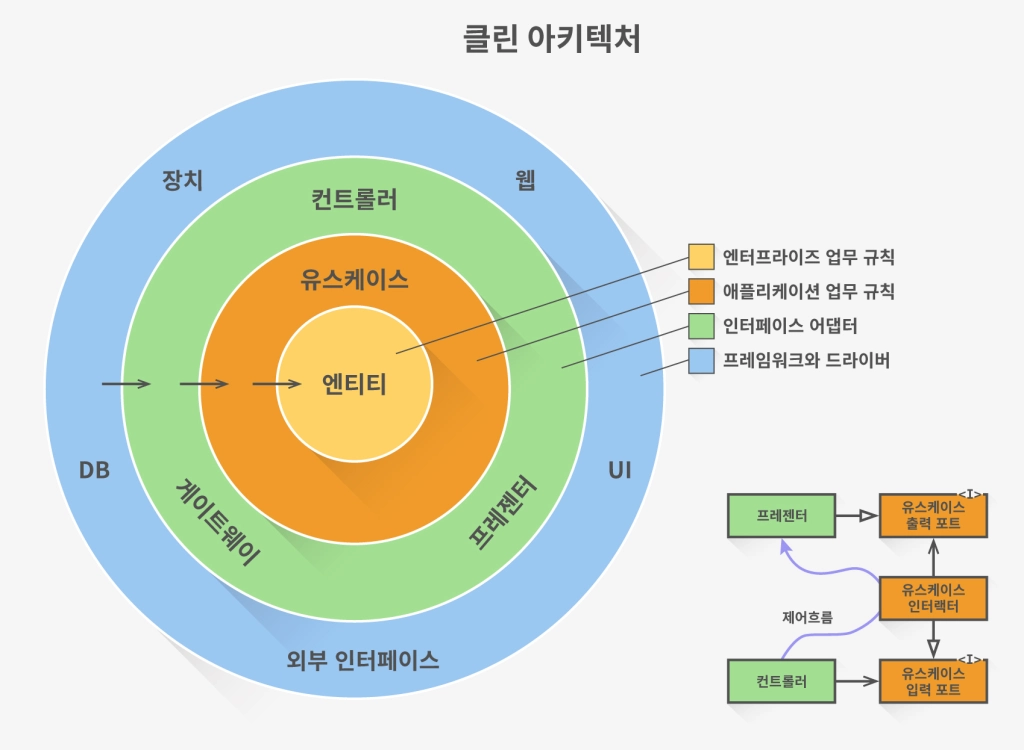
Layered Architecture (계층형 아키텍처) 란?
- 계층형 아키텍처는 시스템을 여러 계층으로 구분하여 설계하는 방식이다.
- 각 계층은 특정한 기능이나 역할을 수행하며, 일반적으로 프레젠테이션 계층(웹), 비즈니스 계층(도메인), 데이터 액세스(영속성) 계층으로 구성된다.
- 계층 간의 의존성은 상위 계층에서 하위 계층으로 향한다.
- 웹 → 도메인 → 영속성
- 계층 간의 분리와 재사용성을 강조합니다. 각 계층은 독립적으로 개발, 관리, 테스트될 수 있습니다.
- 위와 같은 장점이 있지만 계층형 아키텍처에도 단점은 존재한다.
- 데이터 베이스 주도 개발을 유도한다.
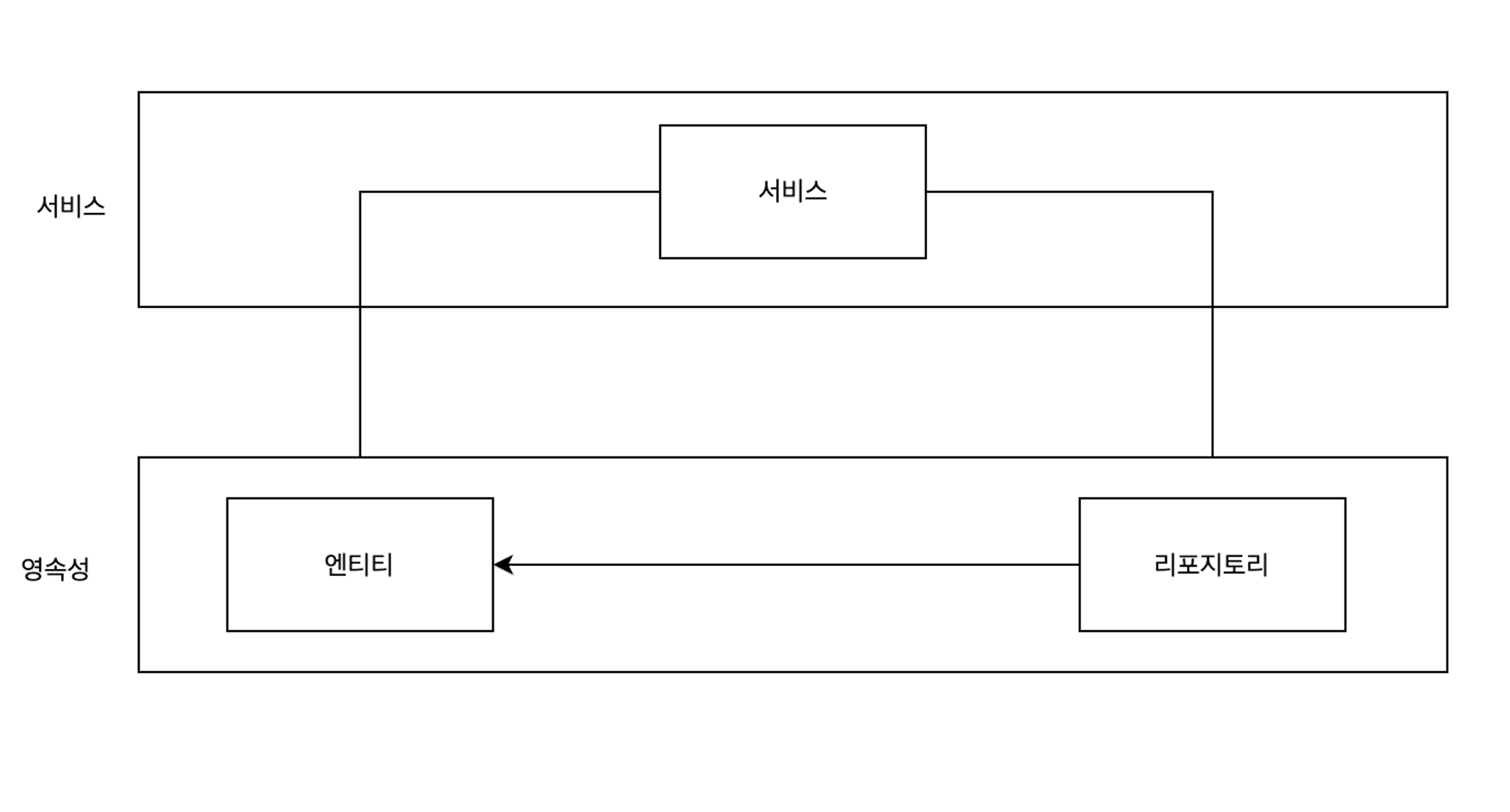
- 우리는 위와같이 계층형 아키텍처를 구현하지 않는가?
- 이렇게 구현을 하였다면 영속성과 서비스에 강한 결합이 생긴다.
- 서비스는 영속성 모델을 비지니스 모델처럼 사용하게 되고 이로 인해 도메인 로직뿐만 아니라 엔티티에 연관관계 매핑, 트랙잭션 관리 등 영속성에 관련된 로직도 처리를 해야한다.
- 테스트 하기가 어렵다.
- 제가 예전에 봤던 강의에서는 일부러 Controller에 Repository를 주입해서 한번에 조회해서 응답을 해버리는 것도 봤었는데요, 이런 예외가 하나, 둘 허용되면 다음 두 가지 문제가 발생합니다.
- 하나의 필드를 조작하는 것에 불과하더라도 도메인 로직을 웹 계층에서 구현하게 됩니다. 앞으로 유스케이스가 확장된다면 더 많은 도메인 로직을 웹 계층에 추가하여 전반적으로 계층간 책임이 섞이게되고, 핵심 도메인 로직들이 여기저기 흩어질 확률이 높아집니다.
- 단위 테스트중 웹 계층 테스트에서 도메인 계층 뿐만 아니라 영속성 계층도 모킹해야한다는 것입니다. 규모가 커지면 다양한 영속성 컴포넌트에 의존성이 쌓이면서 테스트의 복잡도가 올라가고, 어느 순간에는 테스트 코드보다 모킹하는데 시간을 훨씬 더 많이 사용하게 됩니다.
- 실무적으로 동시에 작업하기가 어렵다.
- 계층형 아키텍처는 controller, service, repository으로 크게 분류해서 작업하는데 하나의 기능 개발을 할 때 여러사람이 들어가서 작업하는 것이 많이 힘들다.
- 어떤 사람은 controller을 작업하고 다른 사람은 service, 또 다른 사람은 repository만 작업하게 과연 가능할까? 가능은 하겠지만 사실 이렇게 작업하는 사람들은 거의 없을 것 이다.
- 거의 모든 API는 영속성 계층을 의존하기 때문에 영속성 계층을 작업한 후, 도메인 계층, 웹 계층 순서대로 작업을 합니다. 이런 부분에서 한명의 개발자가 다 하는게 나은가 여러명의 개발자가 다 하는게 나은가는 재고해봐야할 문제가 아닐까 싶습니다.
- 또한 서로 다른 usecase를 추가한다고 할 때 코드를 merge 하는 과정에서 conflict이 발생하기에 어려움을 느꼈습니다.
- 데이터 베이스 주도 개발을 유도한다.
Clean Architecture (클린 아키텍처) 사용하게 된 계기?
- 계층형 아키텍처를 만들다가 어려웠던 점(위에서 작성한 계층형 아키텍처의 단점)을 보안하기 위해서 사용을 하였다.
- 우아콘2022에서 발표한 “기획자님들! 개발자가 아키텍처에 집착하는 이유, 쉽게 알려드립니다. “ 를 보고 난 뒤 영감을 받아 도입하게 되었습니다.
- 링크 : https://www.youtube.com/watch?v=saxHxoUeeSw
Clean Architecture (클린 아키텍처) 란?
- 클린 아키텍처(Clean Architecture)는 소프트웨어 시스템을 구성하는 다양한 계층과 의존성을 관리하는 소프트웨어 설계 원칙입니다. 이 아키텍처는 소프트웨어 시스템의 유지보수성, 테스트 용이성, 확장성, 재사용성 등을 개선하기 위해 개발되었습니다.
-
외부 계층(Outer Layers): 가장 바깥쪽에 위치하며, 사용자 인터페이스, 웹 API, 데이터베이스 등 외부 요소와 상호 작용합니다. 이 계층은 시스템의 외부 요구사항을 처리하고 사용자의 입력을 받아들이며, 비즈니스 로직을 직접적으로 포함하지 않습니다.
-
응용 계층(Application Layer): 외부 계층과 도메인 계층 사이에 위치하며, 비즈니스 규칙과 흐름을 담당합니다. 사용자의 요청을 받아들이고 비즈니스 로직을 실행하며, 도메인 객체와 상호 작용합니다. 응용 계층은 도메인의 상태를 변경하거나 도메인 객체의 상태를 조회하기 위해 도메인 계층에 의존합니다.
-
도메인 계층(Domain Layer): 가장 안쪽에 위치하며, 시스템의 핵심 비즈니스 규칙과 개념을 포함합니다. 도메인 객체와 도메인 서비스를 정의하고, 비즈니스 로직을 실행합니다. 도메인 계층은 외부 계층과 응용 계층에 대한 의존성이 없어야 하며, 도메인의 핵심 개념을 가장 순수한 형태로 표현합니다.
-
인터페이스 어댑터 계층(Interface Adapters): 외부 계층과 도메인 계층 사이에 위치하며, 각 계층 간의 데이터 변환, 형식 변환, 외부 인터페이스 구현 등을 처리합니다. 이 계층은 외부 요소와 시스템 내부의 계층을 분리하고, 각 계층이 독립적으로 변경될 수 있도록 유연성을 제공합니다.
※ 참고 : 클린 아키텍처 책
-
Clean Architecture (클린 아키텍처) 돌아가는 로직은?
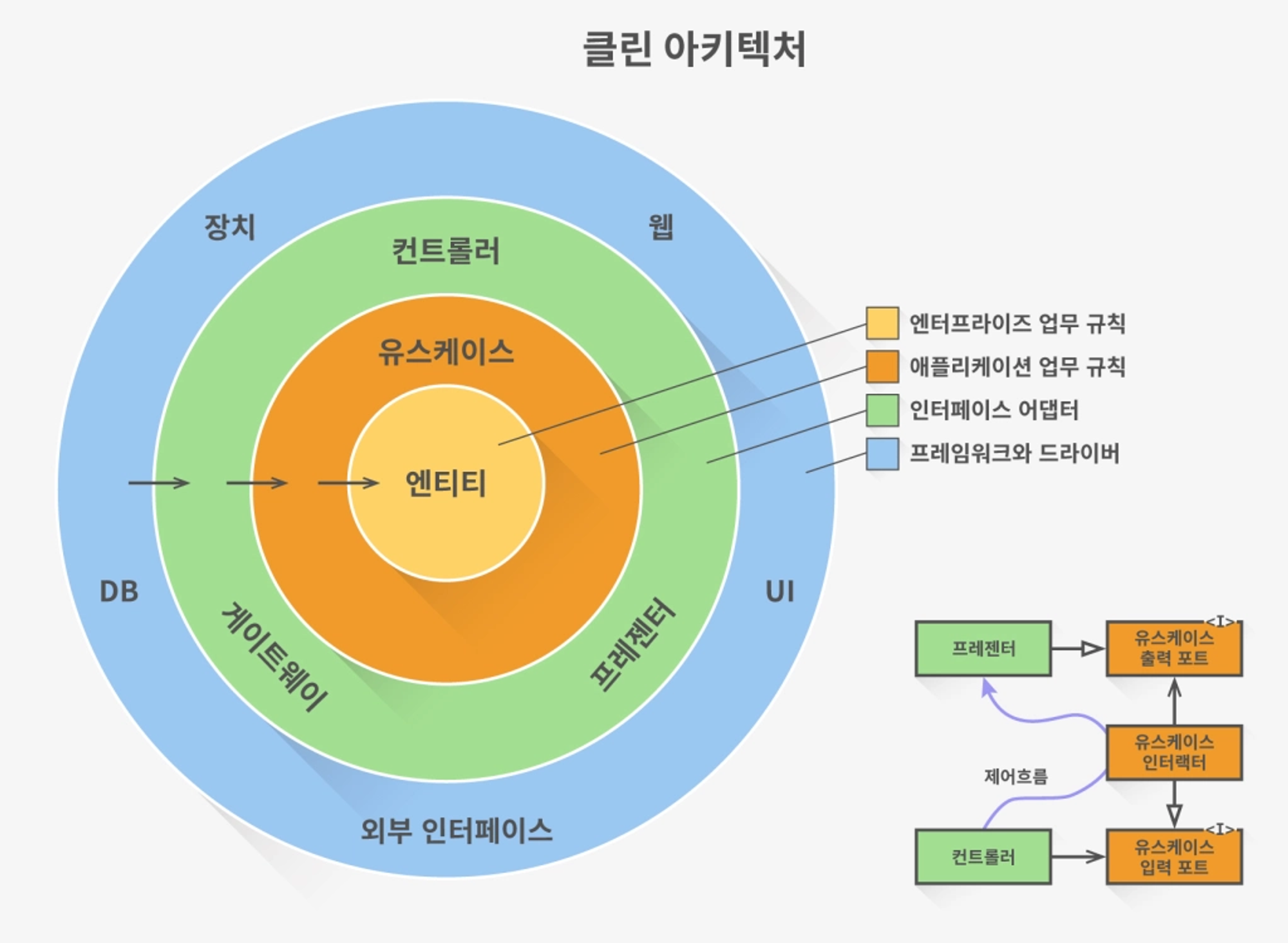
- adapter(in → web)
- application(port → in)
- application(port → service)
- application(port → out)
- adapter(out → persistence)
- adapter(out → persistence → mapper) Domain → JPAEntity
- adapter(out → persistence)
- application(port → out)
- application(port → service)
- application(port → in)
- adapter(out → persistence → mapper) Domain → ResponseDTO
- adapter(in → web)
구동 방식
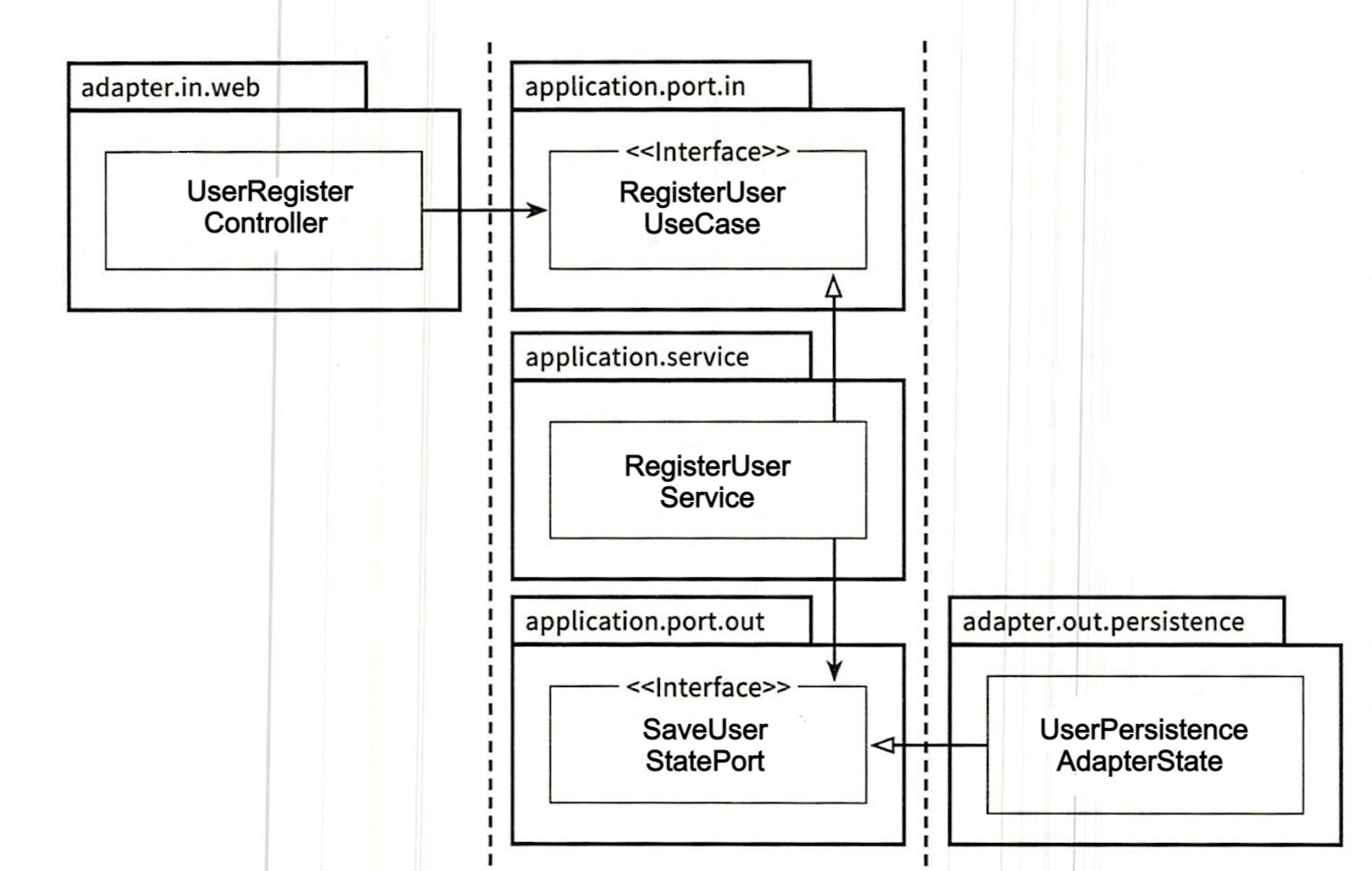
예시 코드 (User Register)
- RegisterUserRequest.java
@Value @EqualsAndHashCode(callSuper = false) public class RegisterUserRequest extends SelfValidating<RegisterUserRequest> { @Pattern( regexp = "^[a-z0-9]{4,20}$", message = "아이디는 영어 소문자와 숫자만 사용하여 4~20자리여야 합니다." ) @NotBlank(message = "아이디은 필수 입력 값입니다.") private String username; @Pattern( regexp = "(?=.*[0-9])(?=.*[a-zA-Z])(?=.*\\W)(?=\\S+$).{8,16}", message = "비밀번호는 숫자,문자,특수문자를 포함한 6~18로 입력해주세요." ) @NotBlank(message = "비밀번호는 필수 입력 값입니다.") private String password; public RegisterUserRequest( String username, String password, ) { this.username = username; this.password = password; this.validateSelf(); } }- 여기서 중점적으로 봐야할 것은 SelfValidating이다.
- 생성자를 통해
this.validateSelf();사용하여 유효성 검사를 실행한다.
- SelfValidating.java
public abstract class SelfValidating<T> { private Validator validator; public SelfValidating() { ValidatorFactory factory = Validation.buildDefaultValidatorFactory(); validator = factory.getValidator(); } protected void validateSelf() { Set<ConstraintViolation<T>> violations = validator.validate((T) this); if (!violations.isEmpty()) { throw new ConstraintViolationException(violations); } } }- 객체의 유효성을 생성 시점에서 확실하게 보장하고 싶은 경우를 위해 사용한다.
- 해당 클래스에서 모든 Bean Validation 어노테이션을 평가하는 메서드입니다.
validator를 사용하여 객체(this)의 속성에 대한 유효성을 평가하고, 어긴 항목이 있다면ConstraintViolationException예외를 throw합니다.
- UserRegisterController.java
@RestController @RequiredArgsConstructor @RequestMapping("/users") public class UserRegisterController { private final RegisterUserUseCase registerUserUseCase; private final UserResponseMapper userResponseMapper; @PostMapping("/register") public ResponseEntity<ReturnObject> registerUser( @RequestBody RegisterUserRequest registerUserRequest ) { RegisterUserCommand command = RegisterUserCommand.builder() .username(registerUserRequest.getUsername()) .password(registerUserRequest.getPassword()) .build(); User user = registerUserUseCase.registerUser(command); RegisterUserResponse response = userResponseMapper.mapToRegisterUserResponse(user); ReturnObject returnObject = ReturnObject.builder() .success(true) .data(response) .build(); return ResponseEntity.status(HttpStatus.OK).body(returnObject); } }- Controller에서는 UseCase를 받아서 사용한다.
- 도메인 로직이 잘 돌아갔다면 Mapper를 이용하여 ResponseDTO로 변환해서 반환해준다.
- ReturnObject는 API Repsonse을 더 깔끔하게 보여주기 위해 작성한 객체입니다.
- RegisterUserCommand.java
@Builder @Data public class RegisterUserCommand { private String username; private String password; public User toEntity() { return User.builder() .username(username) .password(password) .build(); } } - RegisterUserUseCase.java
public interface RegisterUserUseCase { User registerUser(RegisterUserCommand command); }- 인터페이스로 작성하여 Service에서 UseCase를 implements하여 사용한다.
- RegisterUserService.java
@Slf4j @UseCase @Transactional @RequiredArgsConstructor public class RegisterUserService implements RegisterUserUseCase { private final SaveUserStatePort saveUserStatePort; private final PasswordEncoder passwordEncoder; @Override @Transactional public User registerUser(RegisterUserCommand command) { if (!Objects.equals(command.getPassword(), command.getConfirmPassword())) { throw new RuntimeException("두개의 비밀번호가 맞지 않습니다."); } User saveUser = command.toEntity(passwordEncoder); saveUserStatePort.saveUser(saveUser); return saveUser; } }- Usecase의 구현체인 Service에서 비즈니스 로직을 처리한다.
- 아웃고잉 포트인 SaveUserStatePort를 호출한다.
- User.java
@Getter @Builder @AllArgsConstructor(access = AccessLevel.PRIVATE) public class User extends BaseTimeEntity implements Serializable { private Long userId; private String username; private String password; public UserJpaEntity toJpaEntity() { return UserJpaEntity.builder() .id(userId) .username(username) .password(password) .build(); } }- 기본 User는 Domain 로직을 처리해주는 Domain Entity이다.
@AllArgsConstructor(access = AccessLevel.PRIVATE)를 사용하는 이유는- 불변성 유지: 엔티티의 필드는 변경되지 않아야 하므로, 생성자를 통해 필드 값을 초기화하고 이후에는 변경할 수 없도록 만들기 위해 사용됩니다.
- 일관성 유지: 생성자를 통해 필드 값을 설정하면, 객체를 생성하는 시점에서 필수적인 값을 모두 전달해야 합니다. 이를 통해 객체의 일관성을 유지할 수 있습니다.
- toJpaEntity 메소드는 밑에 Mapper 부분에서 설명하겠다.
- SaveUserStatePort.java
public interface SaveUserStatePort { void saveUser(User user); }- 인터페이스로 작성하여 Adapter에서 Port를 implements하여 사용한다.
- UserPersistenceAdapterState .java
@RequiredArgsConstructor @PersistenceAdapter public class UserPersistenceAdapterState implements SaveUserStatePort { private final UserJpaRepo userJpaRepo; private final UserPersistenceMapper userPersistenceMapper; @Override @Transactional public void saveUser(User user) { userJpaRepo.save(userPersistenceMapper.mapToJpaEntity(user)); } }- Port의 구현체인 Adapter에서 비즈니스 로직을 처리한다.
- UserJpaRepo는 간단하게 JpaRepository를 Extends 받고 있다.
- UserPersistenceMapper는 밑에서 설명하겠다.
- UserPersistenceMapper.java
@Component public class UserPersistenceMapper { public User mapToDomainEntity(UserJpaEntity userJpaEntity) { return User.builder() .userId(userJpaEntity.getId()) .username(userJpaEntity.getUsername()) .password(userJpaEntity.getPassword()) .nickname(userJpaEntity.getNickname()) .phone(userJpaEntity.getPhone()) .email(userJpaEntity.getEmail()) .role(userJpaEntity.getRole()) .build(); } public UserJpaEntity mapToJpaEntity(User user) { return user.toJpaEntity(); } }mapToDomainEntity→ 클래스 명 그대로 UserJpaEntity를 User로 변환해주는 역할을 한다.mapToJpaEntity→ 클래스 명 그대로 User를 UserJpaEntity로 변환해주는 역할을 한다.- 이렇게 두개의 변환 메소드를 두는 이유는 제가 생각했을 땐 계층에 분리를 위함인 것 같습니다.
- 또한, 실제 DB에 저장되는 JPA Entity와 비지니스 로직을 처리하기 위한 Domain Entity가 분리되어 있기 때문이다.
결론
도입 후기 (경험 기반)
- 장점
- 유연성과 확장성에 용이합니다.
- 각 계층과 컴포넌트를 분리하므로써 독립적으로 개발이 가능합니다.
- 새로운 요구사항이나 비즈니스적 규칙이 변경됨에 따라 유연하게 대처가 가능하고 기존 코드를 수정하지 않고 새로운 기능을 추가할 수 있습니다.
- 여러명이 동시에 작업하기 좋습니다.
- 계층형 아키텍처라고 한다면 하나의 controller, service에 모든 비즈니스 로직이 포함 되므로 다른 사람과 작업 영역이 겹칠수 있습니다.
- 직관적인 클래스 및 코드
- 클래스 명을 보고 바로 이 클래스가 어떤 로직을 처리하는지 알 수 있습니다.
- 예를들어
UpdateUserStatePort,LoadUserPort두개를 비교하자면 StatePort, Port로 구분이 가능한데 State가 붙은 클래스명은 상태 변화가 존재하여 클래스 명에 기입을 해주었습니다.
- 유연성과 확장성에 용이합니다.
- 단점
- 도입하기까지 러닝커브가 조금 높게 작용할 수도 있습니다.
- 예를들어 api 하나 단위로 모든걸 분리해서 작업을 해야하는데 이런 부분에서 어려움을 겪을 수도 있을 것 같습니다.
- 오버헤드 될 가능성이 존재합니다.
- 레이어 간의 인터페이스 호출이 빈번하게 일어나는 경우 성능에 영향을 줄 수 있으므로 주의가 필요합니다.
- 도입하기까지 러닝커브가 조금 높게 작용할 수도 있습니다.
궁금했던 점
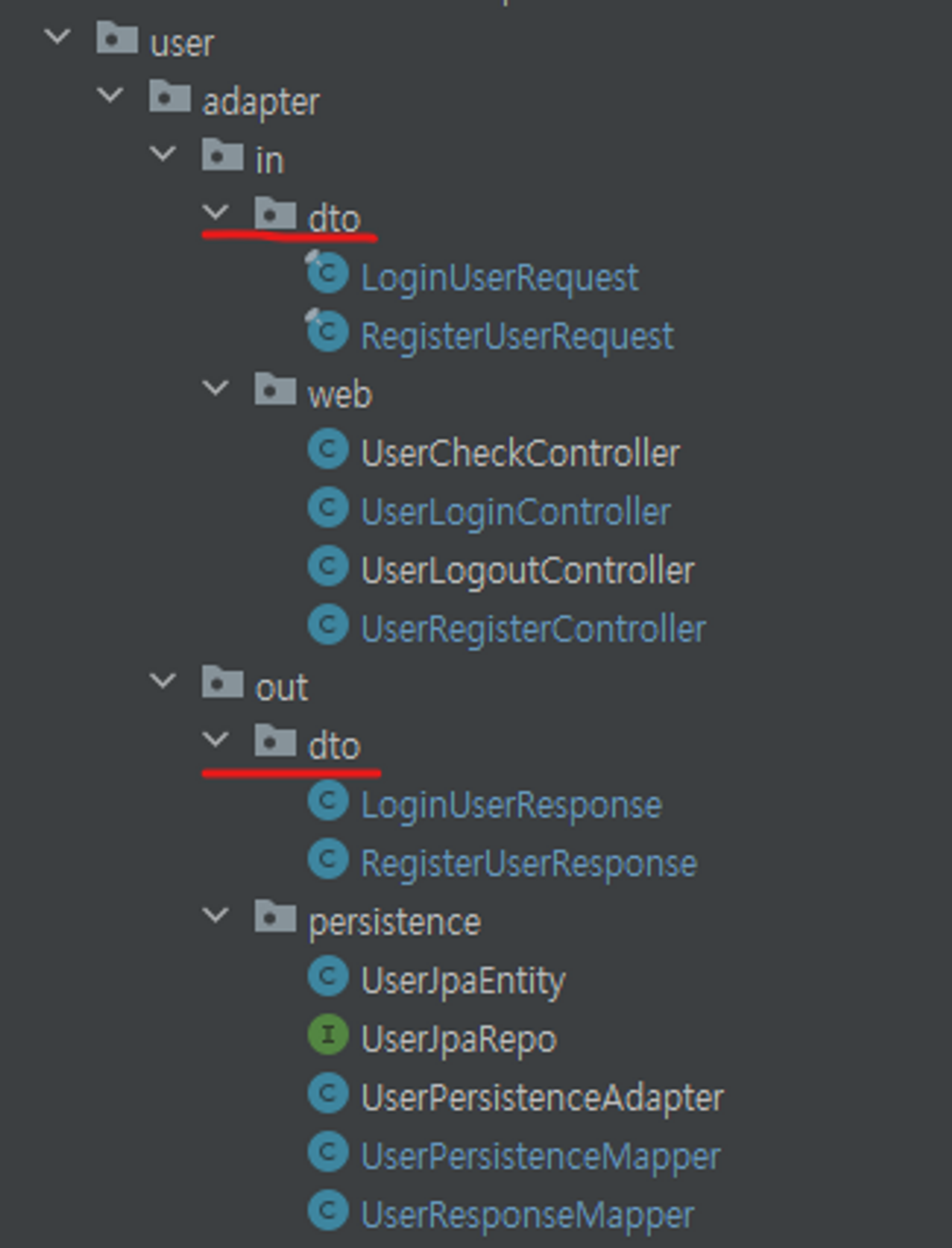
- DTO는 어느 위치에 두어야하는지?
- 클린 아키텍처에서 Adapter 계층은 클린 아키텍처의 가장 바깥쪽을 구성한다.
- DTO는 외부 시스템이나 서비스와의 통신을 위한 것이므로, Adapter 계층에 위치 시키는게 좋다고 생각했습니다.
- 패키지 구조는 다음과 같습니다.
- Controller도 API 별로 나눠서 클래스를 만들어야하는지?
- 객체지향적 설계 中 단일 책임 원칙(Single Responsibility Principle)에 부합하기 위해 Controller는 API 별로 나눠서 작성했습니다.
- 근데 이렇게 되면 너무 많은 Controller가 만들어져서 구조 자체가 복잡해질 수 있는데 적절하게 균형을 유지하는 편이 좋다고 생각합니다.
- 예를들어 저는 유저에 대한 중복 검사를 해야하는 경우
username,nickname은 하나의 Controller에 담아서 사용을 하였습니다.
- 예를들어 저는 유저에 대한 중복 검사를 해야하는 경우
- 각 계층마다 데이터 전달을 위해 객체 변환을 수행하는 이유는?
- 계층 간의 직접적인 의존성을 최소화하고, 각 계층이 독립적으로 변경될 수 있도록 합니다.
- 객체 변환을 통해 데이터를 변환하고 정제하여 각 계층이 필요한 형태로 제공됩니다. 예를 들어, 데이터 액세스 계층에서는 JPA 엔티티로 데이터를 저장하고 조회하며, 도메인 영역에서는 도메인 엔티티로 비즈니스 규칙을 수행합니다.
- Persistence Mapper를 사용하는 이유?
- JPA Entity와 Domain Entity를 분리하여 사용하기 때문이다. 도메인 객체는 비즈니스 로직에, 데이터베이스 테이블은 데이터 저장에 중점을 둔다. Persistence Mapper를 사용하면 이 두 영역을 분리할 수 있다.
- 데이터베이스의 스키마가 변경되더라도, 이 변경이 도메인 모델에 영향을 미치지 않도록 보장할 수 있습니다. 반대로 도메인 모델이 변경되더라도 데이터베이스에는 영향을 주지 않습니다.
- 유스케이스가 다른 유스케이스를 호출해도 되는지?
- 네 가능합니다. 이러한 구성은 다른 유스케이스의 기능을 재사용하거나 협업이 필요한 경우에 유용합니다.
- 그러나 유스케이스 간의 결합도를 유지하고 단방향 의존성을 유지하는 것이 중요합니다. 의존성 역전 원칙(Dependency Inversion Principle)을 준수하여 의존성을 외부로부터 주입받도록 설계하고, 필요한 경우 인터페이스를 통해 유연한 의존성 관리를 할 수 있도록 해야 합니다.
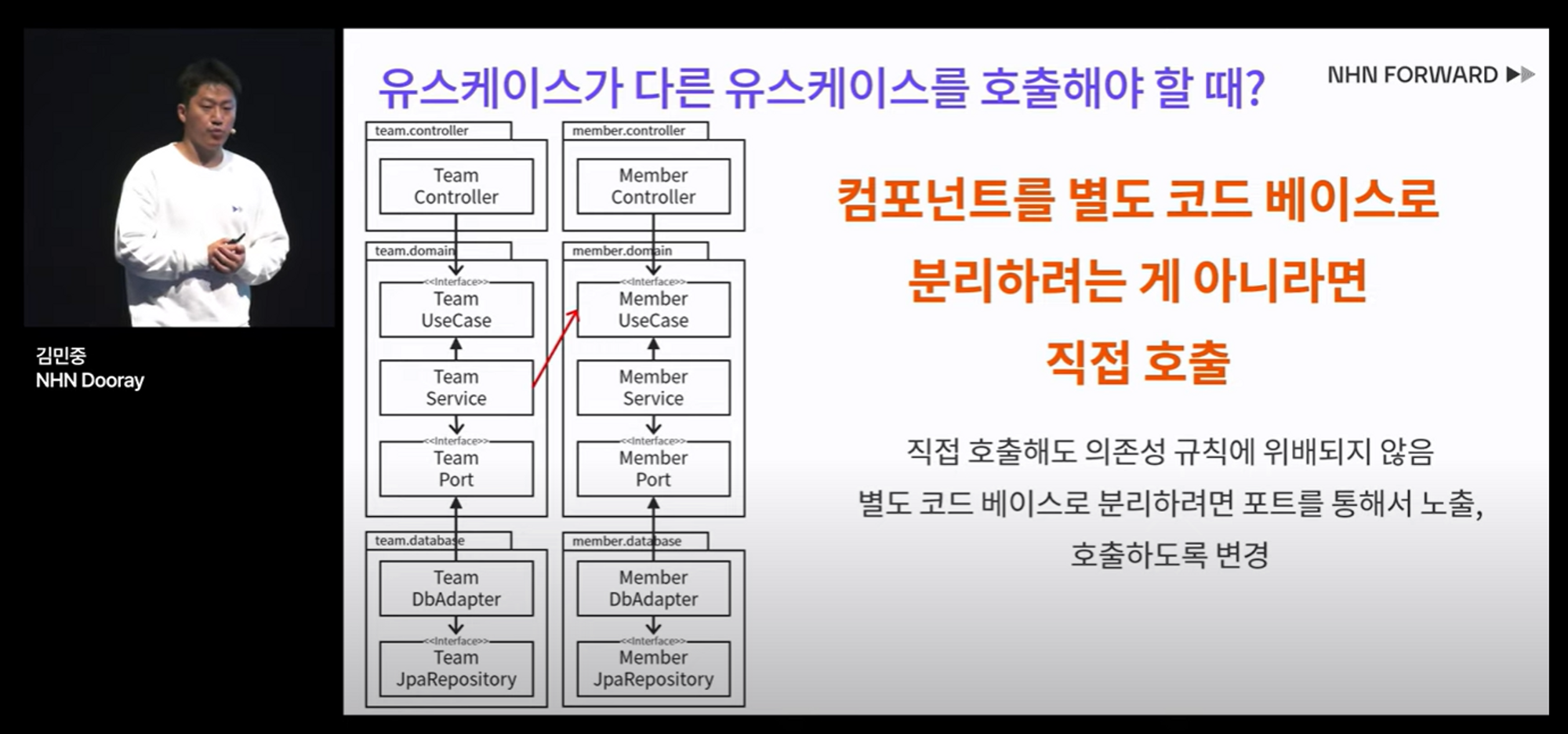
- 밑에는 제가 구현한 예시 코드입니다.
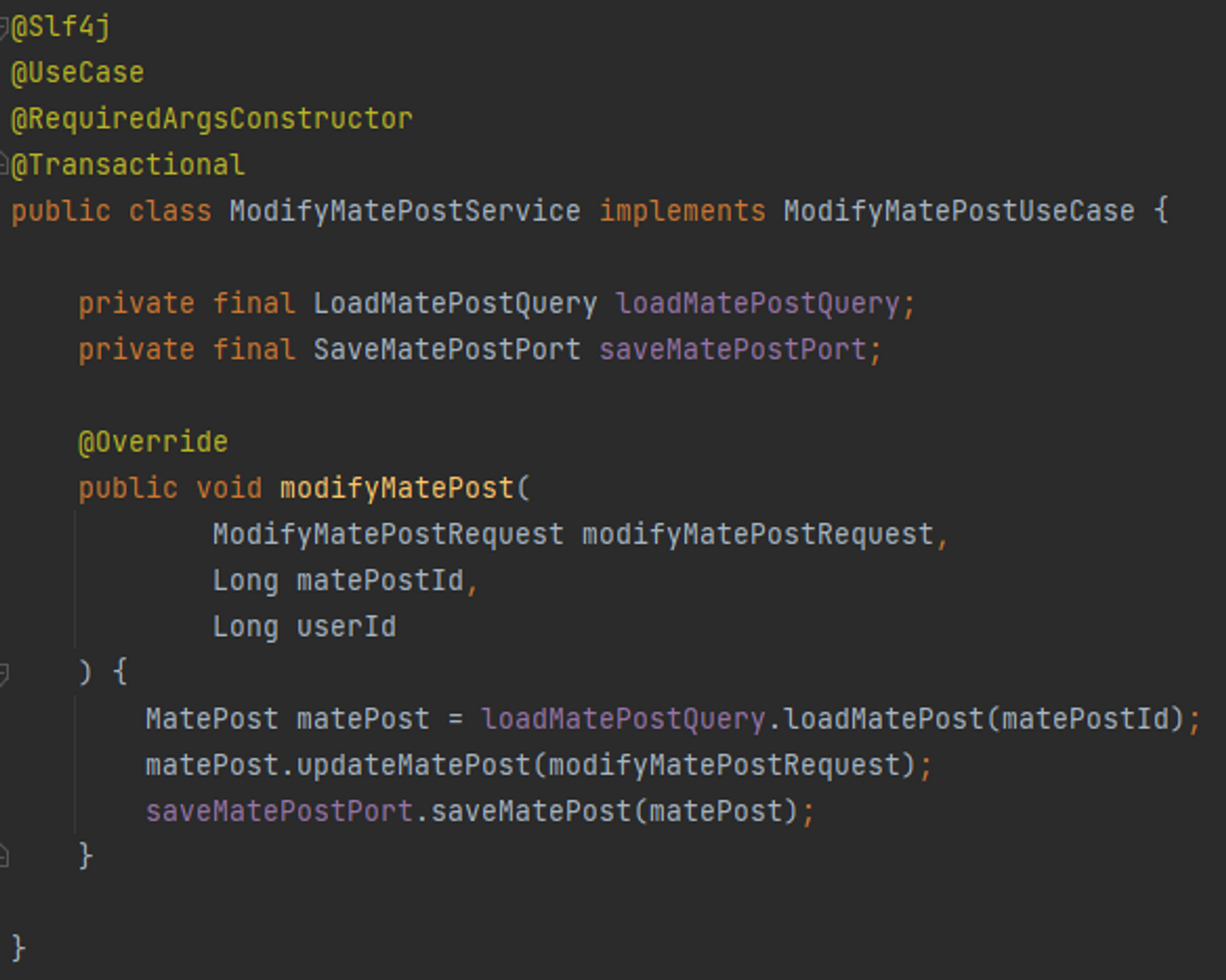
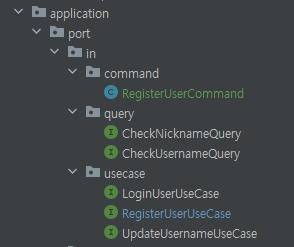
- 패키지 구조중 Application → port → in 에서 파일 명이 UseCase와 Query의 차이점은?
- UseCase와 Query는 비즈니스 로직을 나타내는 것인데, 둘은 다음과 같은 차이가 있다.
- UseCase → 사용자의 특정 작업을 수행하는 로직하며, 주로 CRUD(Create, Read, Update, Delete) 같은 작업을 포함하고 도메인 복잡성에 따른 다양한 비즈니스를 수행한다.
- Query → Query는 일반적으로 읽기 전용 작업(read operations)을 나타내며, 상태를 변경하지 않는다. Query는 주로 데이터베이스에서 데이터를 읽어오는 작업을 포함하지만, 더 넓은 의미에서는 모든 종류의 데이터 조회 작업을 포함할 수 있습니다.
- 패키지 구조는 다음과 같습니다.
- Entity를 나눠서 작성하는 이유는? (Domain Entity, JPA Entity)
- Entity를 하나로 쓰게 되면 단점들이 존재한다.
- 영속성 계층과 도메인 계층의 강한 결합이 생긴다.
- Entity를 하나로 쓰기에 비즈니스 로직뿐만 아니라 연관 관계 매핑, 즉시/지연 로딩 등을 고려야함.
- Entity를 하나로 쓰게 되면 단점들이 존재한다.
- Domain Entity와 JPA Entity의 연관관계 매핑의 차이점은?
- 직접적으로 DB에 접근하는 Entity는 JPA Entity로써 연관관계 매핑은 JPA Entity에서 해준다.
- Domain Entity는 굳이 연관관계 매핑을 안 해줘도 되는 것으로 알고 있다.
- Domain Entity에서 연관관계를 Id 값으로 받는 이유는? → DDD 패턴에서 잘 설명이 되어있을 것 같습니다.
- Domain Entity는 느슨한 결합을 해야하므로 객체 간의 직접적인 참조보다는 식별자(Id)를 통해 연관된 Entity에 접근하는 것이 더 유연하고 확장성이 있는 설계가 가능하게 한다. 또한, 객체 간의 참조를 식별자로 대체하면 독립적인 단위 테스트가 가능하다.
- 연관된 엔티티가 많아질수록 메모리 사용량이 증가하고, 직접적인 객체 참조를 통한 연관 관계 탐색은 성능에 영향을 미칠 수 있다. 반면에 식별자를 사용하여 연관된 엔티티를 가져올 때는 필요한 시점에 쿼리를 실행하여 필요한 데이터만 가져올 수 있다.
- 도메인 엔티티에서 연관관계를 Id(Long 타입) 값으로 받으면, 해당 엔티티를 생성할 때 연관된 엔티티의 식별자만 알고 있으면 됩니다. 이는 도메인 모델의 일관성을 유지하고 데이터 무결성을 보장하는 데 도움을 줍니다. 엔티티 사이의 관계가 변경되어도 해당 Id 값만 업데이트하면 됩니다.
- DTO와 Command의 차이점?
- DTO는 순수한 데이터를 전달하는 데 사용되는 반면, Command는 애플리케이션에 수행할 작업을 나타내는 것이다.
- 이 두 개념은 서로 다른 목적을 위해 사용되며, 일반적으로 DTO는 Command의 매개변수로 사용되어 작업을 수행하는 데 필요한 데이터를 제공한다.
사실 이 두개를 구분지어 사용하는 이유를 아직까지 명확하게 이해하지는 못하였다.- 이 부분은 밑에 사진을 같이 보면 편할 것 같다.
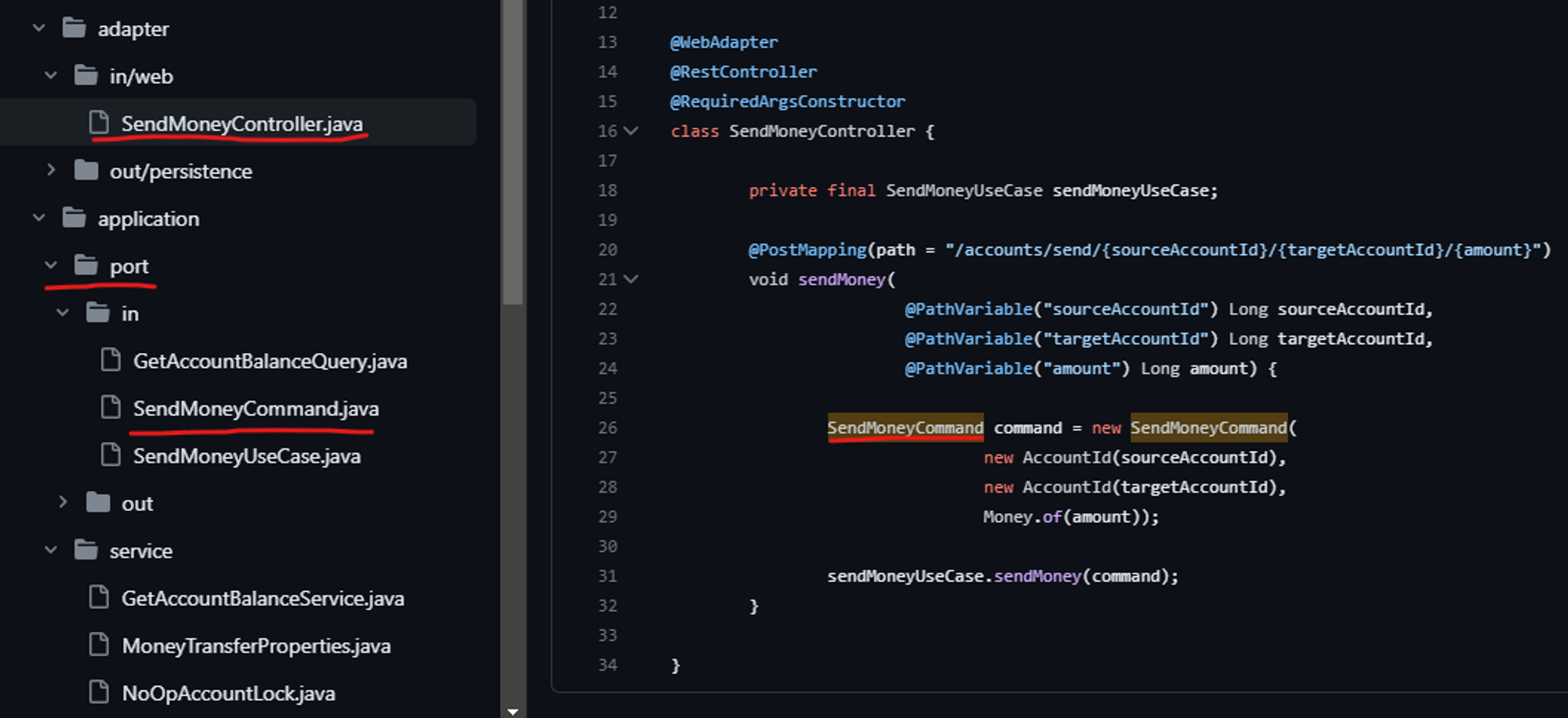
- Command, Query, UseCase가 있는데, 이 중 Command, Query를 먼저 보겠다.
- Command, Query는 CQRS 패턴에 의해 사용이 된 것이고, Port에 들어올 시 객체에 대한 변화를 주기 위함이다.
- 이건 제 생각이지만, 이렇게 Port에 들어오고 나갈 때 마다 객체가 변화되는 것은 결합을 낮추기 위함이다라고 생각했습니다.
- 이 부분은 밑에 사진을 같이 보면 편할 것 같다.
- StatePort, Port의 차이점?
- 처음 생각했을 때는 Update에 주로 State가 붙은 Port 사용하기에 상태에 대한 변경이 이루어 질 때만 State를 사용하는 걸로 알고 있었다.
- 대충 반은맞고 반은 틀린말인데, 찾아보니 네이밍 컨벤션을 따르기에 StatePort, Port가 나누는 것으로 확인이 되었다.
- 예를들어 유저 기반에 상태변경은 주로 :
UpdateUserStatePort,DeleteUserStatePort,ActivateUserStatePort등으로 사용한다. - 그 외 나머지는 상태변경이 아닌 단순 조회로 :
LoadUserPort,SaveUserPort등으로 사용한다.
- PersistenceMapper는 어디까지 해줘야하는가?
- 클린 아키텍처에서 PersistenceMapper는 데이터 베이스와의 상호작용을 담당하는 구성 요소이다.
- 즉, 영속성 계층과 도메인 계층 간의 데이터 변환을 수행한다.
- 데이터 변환으로는 밑과 같다.
- 영속성 계층 → 도메인 계층
- 도메인 계층 → 영속성 계층
- QueryDSL은 어디에 두어야하는지?
- QueryDSL은 데이터베이스 쿼리 작성을 위한 도구로 일반적으로 영속성 계층에 위치시키는게 적합하다.
꼭 다 지켜야 하나요?
- 꼭은 지켜야하는 것은 아니다. 다만, 어느정도 내부 구성 팀원들과 상호 협의하고 난 뒤 적당하게 지킬건 지키고 넘어가야할 부분은 넘어가도 될 것 같다.
- 그리고 추가적으로 만약 너무 지름길로만 가게 된다면(adapter → port → Persistence로 가야하는데 adapter → Persistence로 한번에 가는 경우들), 깨진 유리창 이론에 부합하게 된다. 💡 깨진 유리창 이론이란? 깨진 유리창 하나를 방치해 두면, 그 지점을 중심으로 범죄가 확산되기 시작한다는 이론으로, 사소한 무질서를 방치하면 큰 문제로 이어질 가능성이 높다는 의미를 담고 있다. - 품질이 떨어진 코드에서 작업할 때 더 낮은 품질의 코드를 추가하기가 쉽다. - 코딩 규칙을 많이 어긴 코드에서 작업할 때 또 다른 규칙을 어기기도 쉽다. - 지름길을 많이 사용한 코드에서 작업할 때 또 다른 지름길을 추가하기도 쉽다. - 즉, 레거시 코드가 될 가능성이 높습니다. 
참고
- 만들면서 배우는 클린 아키텍처 책, Github https://github.com/wikibook/clean-architecture
- NHN 컨퍼런 [NHN FORWARD 22] 클린 아키텍처 애매한 부분 정해 드립니다.
- 배달의 민족 컨퍼런스 기획자님들! 개발자가 아키텍처에 집착하는 이유, 쉽게 알려드립니다 #우아콘2022 #Day1_일상의행복을배달하기위해

지나가는 개발자
클린 아키텍쳐에 대한 개념과 쉽게 풀어낸 설명 덕분에 이해하기 쉬웠습니다!