컴퓨터 비전 이미지 해석 방법론

컴퓨터 비전에서 이미지 해석(Image Understanding) 방법론은 매우 다양합니다. 대표적인 방법론별 단계와 Python 예제 코드를 정리했습니다.
1. 전통적 이미지 해석 방법론 (Classical Computer Vision)
주요 단계
- 이미지 전처리 (흑백 변환, 노이즈 제거 등)
- 특징 추출 (에지, 코너, 히스토그램 등)
- 특징 기반 매칭 또는 분류 (SVM, KNN 등)
Python 예제 (OpenCV 사용)
# !pip install numpy
# !pip install cv2
import cv2
import numpy as np
# 1. 이미지 읽기 및 전처리
img = cv2.imread('cat.jpg', cv2.IMREAD_GRAYSCALE)
img_blur = cv2.GaussianBlur(img, (5, 5), 0)
# 2. edges 검출 (Canny)
edges = cv2.Canny(img_blur, 100, 200)
# 3. 결과 시각화
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()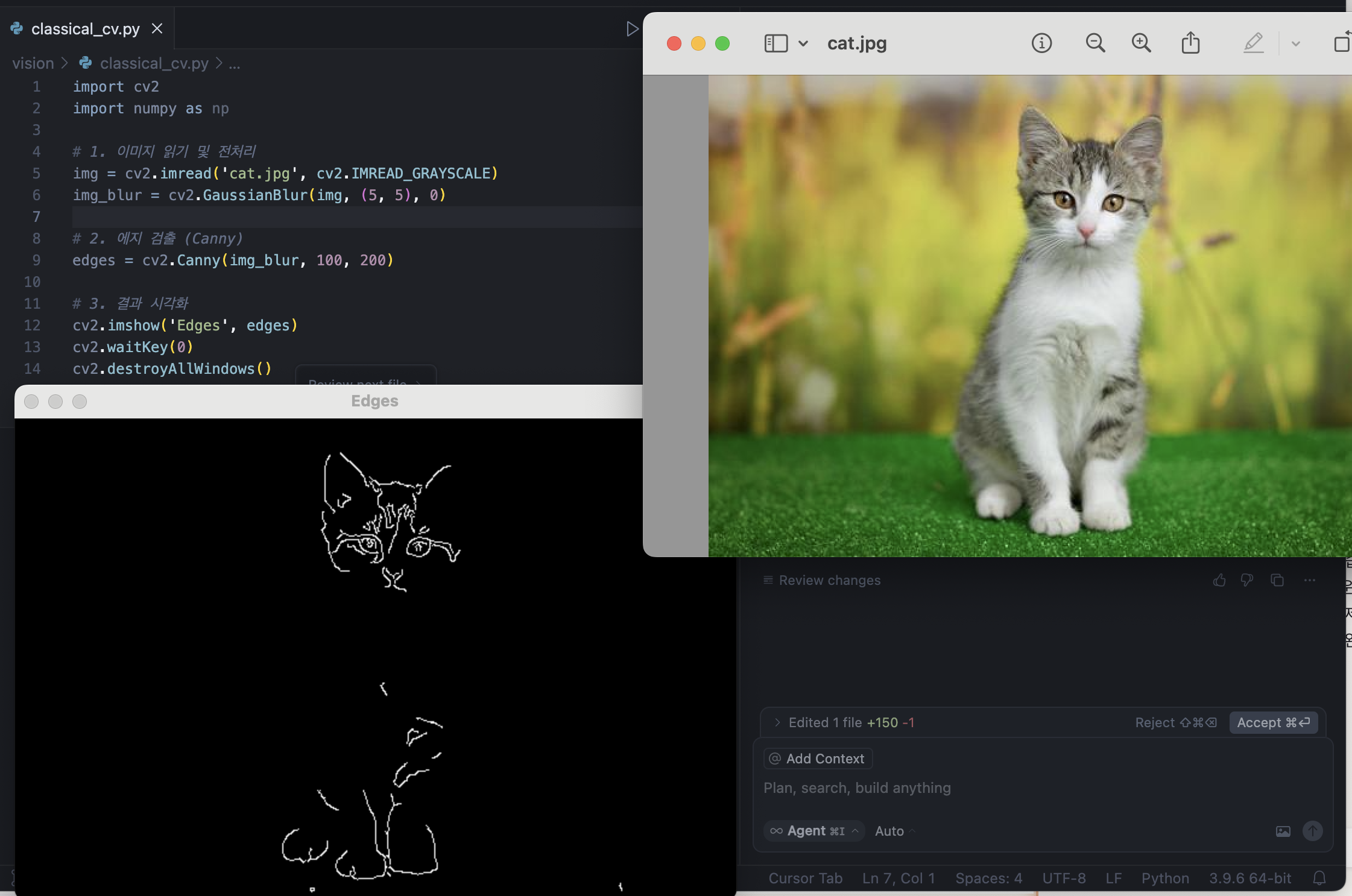
2. 딥러닝 기반 이미지 해석 (Deep Learning)
주요 단계
- 데이터 준비 및 전처리
- 모델 설계 (CNN 등)
- 학습 및 평가
- 예측 및 해석
Python 예제 (TensorFlow/Keras 사용)
# !pip install pillow
import tensorflow as tf
from tensorflow.keras.applications import mobilenet_v2
from tensorflow.keras.preprocessing import image
import numpy as np
import argparse
# 인자 파서 설정
parser = argparse.ArgumentParser()
parser.add_argument('--img', type=str, required=True, help='이미지 파일명')
args = parser.parse_args()
# 1. 이미지 불러오기 및 전처리
img = image.load_img(args.img, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = mobilenet_v2.preprocess_input(x)
# 2. 사전학습된 모델 불러오기
model = mobilenet_v2.MobileNetV2(weights='imagenet')
# 3. 예측
preds = model.predict(x)
decoded = tf.keras.applications.mobilenet_v2.decode_predictions(preds, top=5)[0]
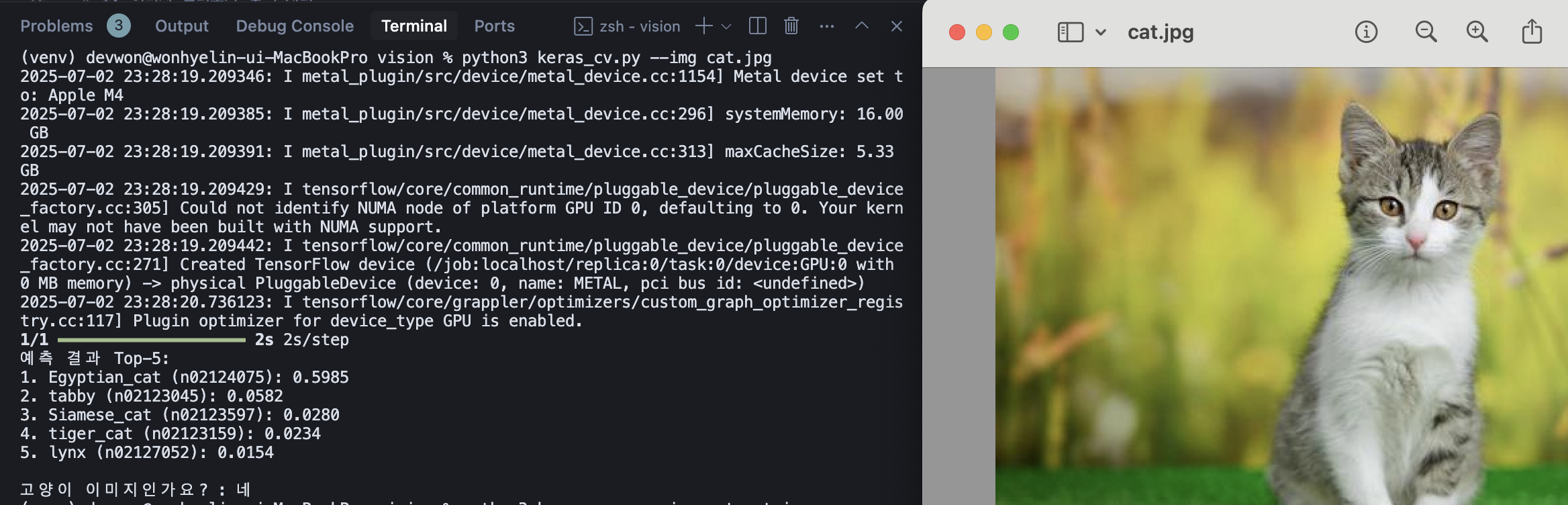
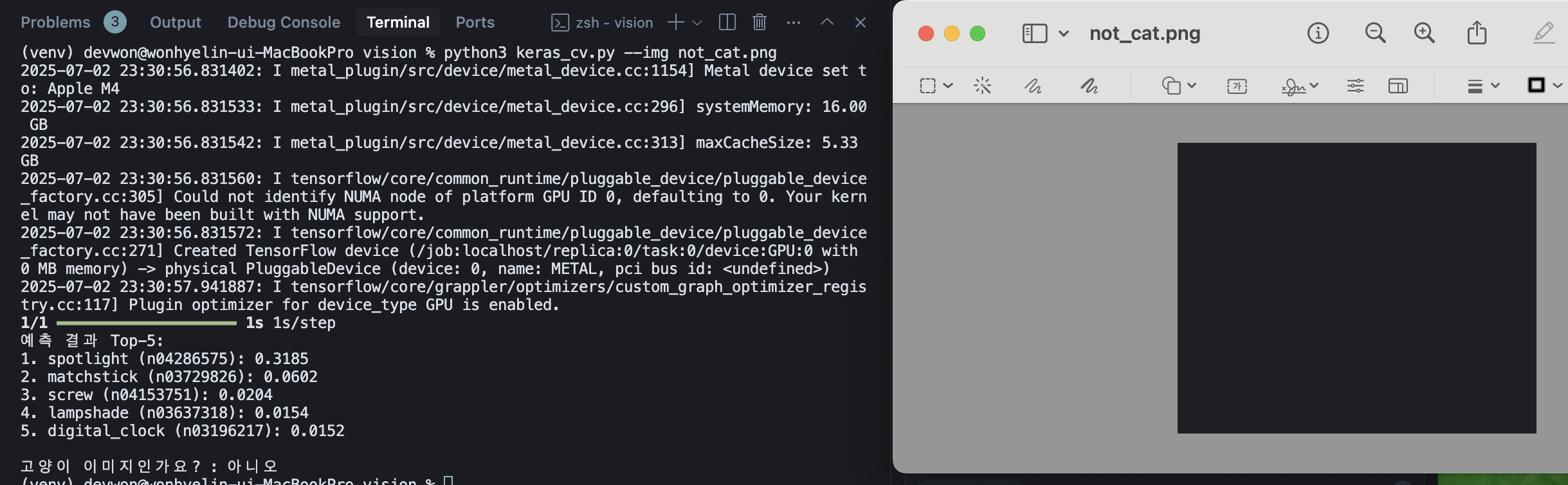
# 4. 결과 출력 및 고양이 여부 판별
print("예측 결과 Top-5:")
for i, (code, name, score) in enumerate(decoded):
print(f"{i+1}. {name} ({code}): {score:.4f}")
# 고양이 클래스 포함 여부 확인
detected_cat = any('cat' in name.lower() for (_, name, _) in decoded)
print("\n고양이 이미지인가요? :", "네" if detected_cat else "아니오")
3. 객체 탐지(Object Detection)
주요 단계
- 데이터 라벨링 (바운딩 박스 등)
- 모델 선택 (YOLO, SSD, Faster R-CNN 등)
- 학습 및 평가
- 이미지 내 객체 탐지
Python 예제 (YOLOv5, PyTorch 사용)
# YOLOv5 설치 및 사용 예시
# !pip install torch torchvision
# !git clone https://github.com/ultralytics/yolov5
# %cd yolov5
# !pip install -r requirements.txt
import torch
# 1. 사전학습된 모델 불러오기
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 2. 이미지 예측
results = model('cat.jpg')
# 3. 결과 시각화
results.show()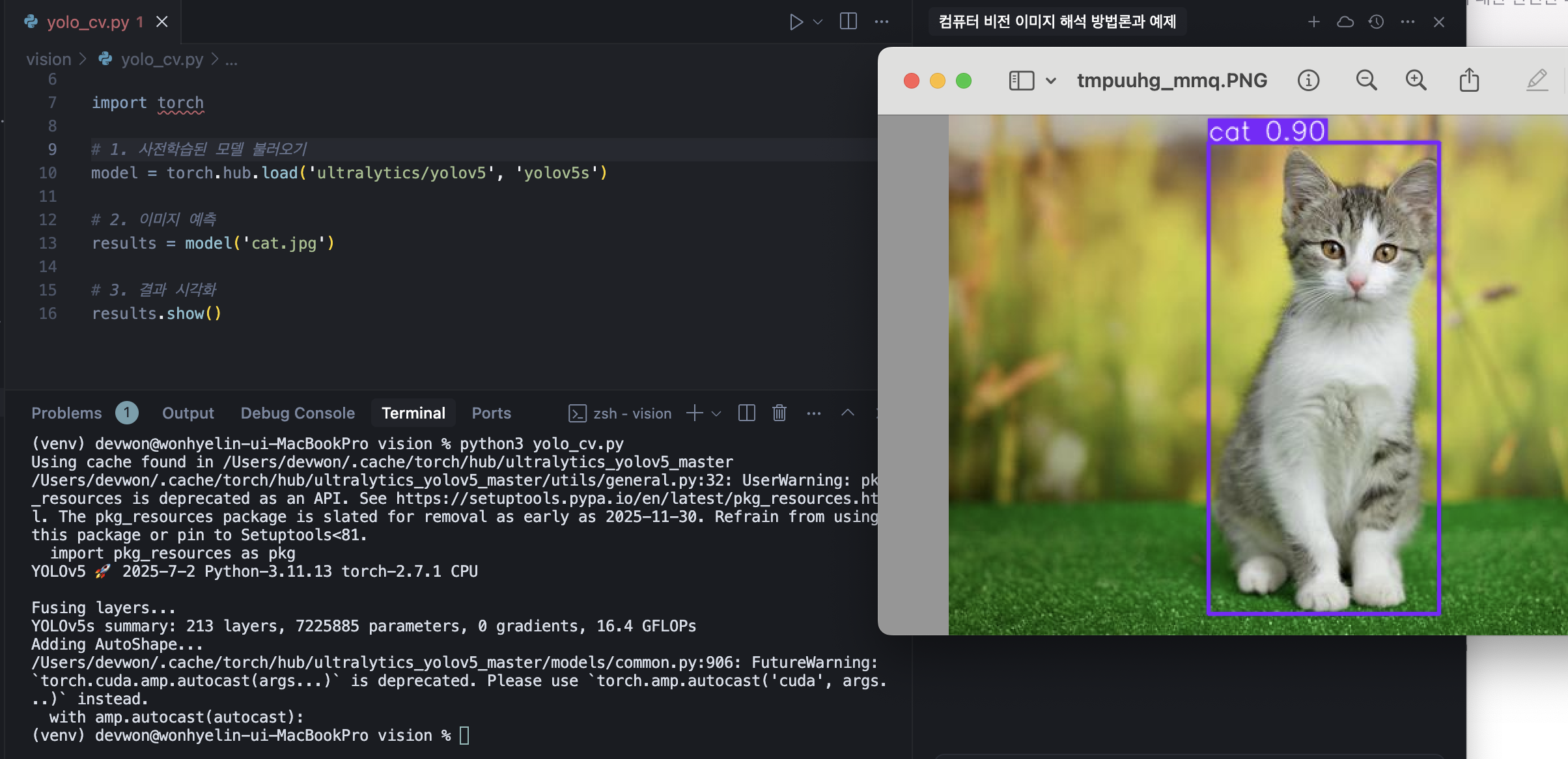
4. 이미지 분할(Image Segmentation)
주요 단계
- 데이터 준비 (픽셀 단위 라벨링)
- 모델 선택 (U-Net, DeepLab 등)
- 학습 및 평가
- 이미지 내 객체 분할
Python 예제 (U-Net, Keras 사용)
from tensorflow.keras import layers, models
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 1. 입력 레이어: 128x128 크기의 흑백 이미지를 입력받습니다.
# (이미지 분할에서는 보통 픽셀 단위로 마스크를 예측하기 때문에 입력 크기를 지정합니다)
inputs = layers.Input((128, 128, 1))
# 2. 인코더(Contracting Path):
# - 이미지를 점점 더 작은 크기로 줄이면서(특징맵 다운샘플링)
# - 중요한 특징(패턴, 경계 등)을 추출합니다.
# - Conv2D: 합성곱 연산으로 이미지의 특징을 뽑아냅니다.
# - activation='relu': 비선형성을 추가하여 복잡한 패턴을 학습할 수 있게 합니다.
c1 = layers.Conv2D(16, (3, 3), activation='relu', padding='same')(inputs) # 첫 번째 합성곱
c1 = layers.Conv2D(16, (3, 3), activation='relu', padding='same')(c1) # 두 번째 합성곱
# - MaxPooling2D: 이미지를 2배로 줄여서(다운샘플링) 더 넓은 영역의 특징을 볼 수 있게 합니다.
p1 = layers.MaxPooling2D((2, 2))(c1)
# 3. (생략) U-Net의 전체 구조에서는 인코더-디코더 반복, 스킵 커넥션 등이 추가됩니다.
# - 여기서는 구조를 단순화하여 일부만 구현했습니다.
# 4. 출력 레이어:
# - Conv2D(1, (1, 1)): 마지막에 1채널(흑백)로 픽셀별로 값을 예측합니다.
# - activation='sigmoid': 각 픽셀이 0~1(배경/객체) 사이의 확률값을 갖도록 만듭니다.
outputs = layers.Conv2D(1, (1, 1), activation='sigmoid')(p1)
# 5. 모델 객체 생성: 입력과 출력을 연결하여 전체 네트워크를 만듭니다.
model = models.Model(inputs=[inputs], outputs=[outputs])
# 6. 모델 컴파일:
# - optimizer='adam': 가중치 최적화 방법(Adam)
# - loss='binary_crossentropy': 픽셀 단위 이진 분할 문제에 적합한 손실 함수
# - metrics=['accuracy']: 정확도를 평가 지표로 사용
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 2. cat.jpg 이미지 불러오기 및 전처리
img = cv2.imread('cat.jpg', cv2.IMREAD_GRAYSCALE)
img_resized = cv2.resize(img, (128, 128))
img_norm = img_resized / 255.0
x_input = img_norm.reshape(1, 128, 128, 1)
# 3. segmentation 예측 (랜덤 가중치이므로 의미 없는 결과임)
pred_mask = model.predict(x_input)[0, :, :, 0]
# 4. 결과 시각화
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
plt.title('Input Image')
plt.imshow(img_resized, cmap='gray')
plt.axis('off')
plt.subplot(1,2,2)
plt.title('Predicted Mask')
plt.imshow(pred_mask, cmap='gray')
plt.axis('off')
plt.tight_layout()
plt.show()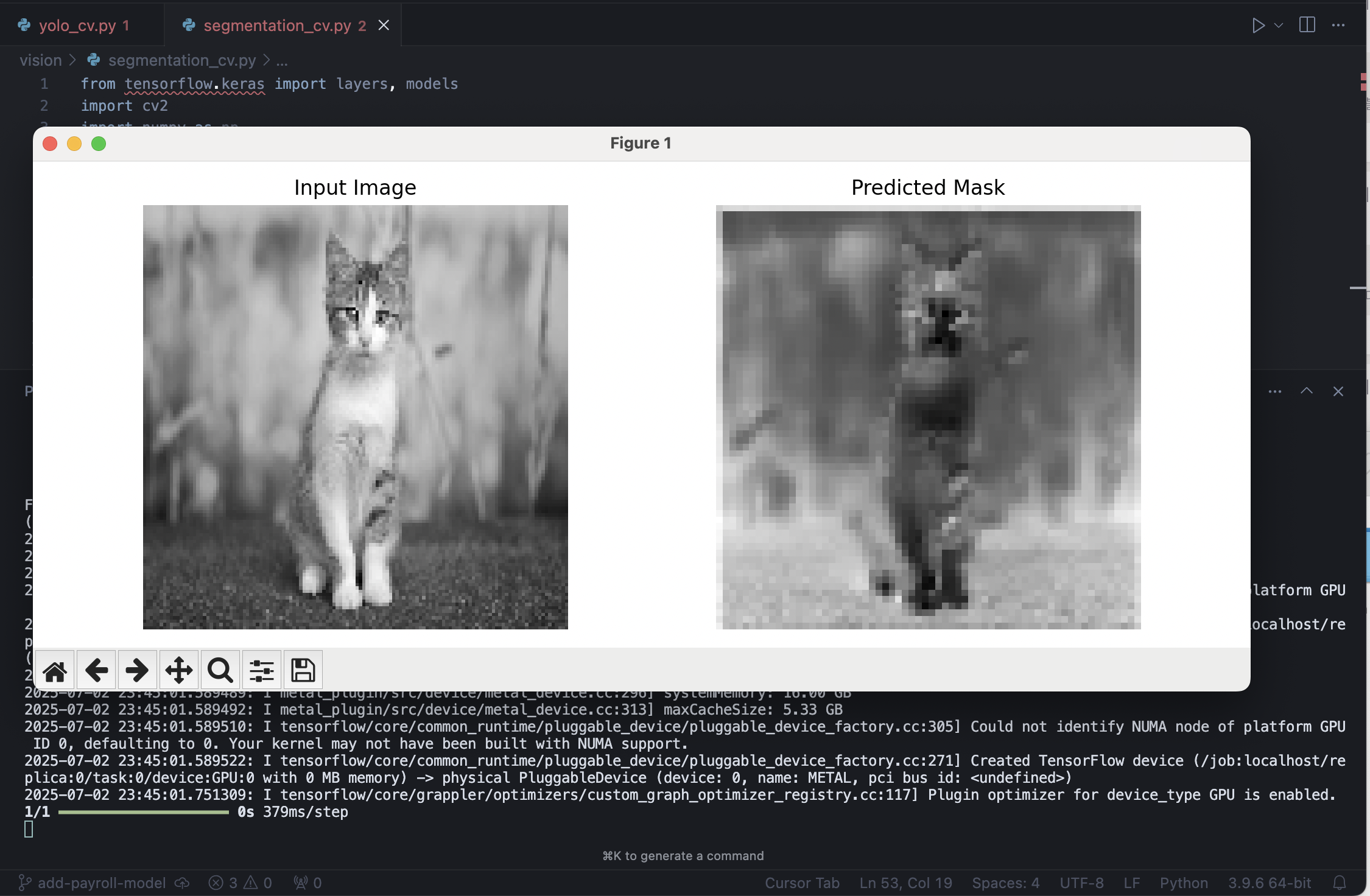
5. 이미지 캡셔닝(Image Captioning)
주요 단계
- 이미지 특징 추출 (CNN)
- 시퀀스 모델링 (RNN, Transformer)
- 캡션 생성
Python 예제 (사전학습 모델 사용)
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
img = Image.open('cat.jpg')
inputs = processor(img, return_tensors="pt")
out = model.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
print(caption)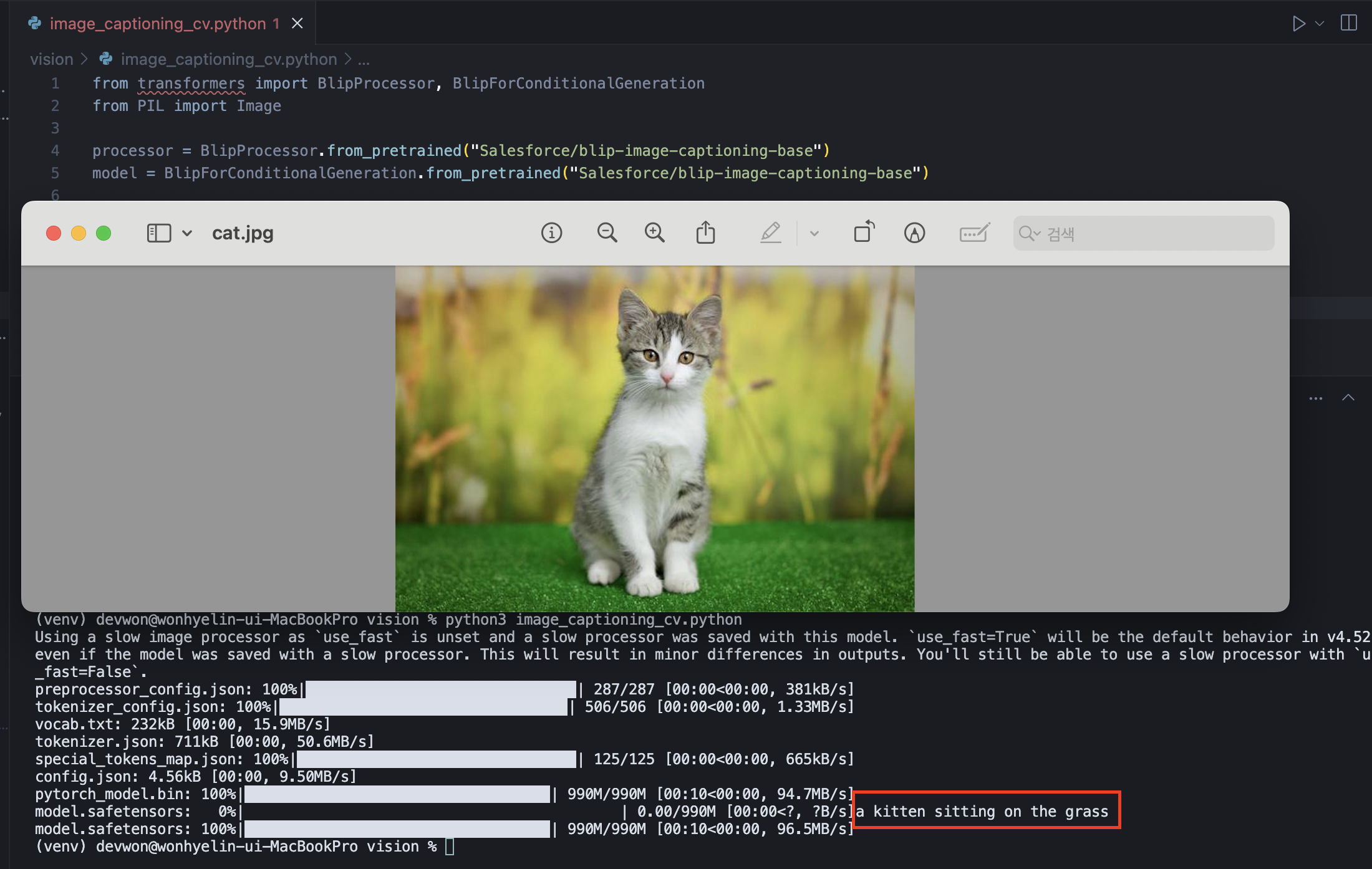
각 방법론은 목적과 데이터에 따라 선택하며, 실제 프로젝트에서는 여러 방법을 조합해서 사용하기도 합니다.

백엔드 개발자