리스트와 딕셔너리는 파이썬을 사용하면서 가장 빈번하게 접하게 되는 자료형이다. 특히 코딩 테스트에서 이 2가지 자료형은 거의 모든 문제에 빠짐없이 쓰이는 자료형인 만큼 구조를 확실히 이해해 기초를 튼튼히 하고, 활용법을 충분히 숙지해 문제 풀이에 자유자재로 활요할 수 있어야 한다.
리스트
리스트 : 순서대로 저장하는 시퀀스이자 변경 가능한 목록
① 입력 순서가 유지된다.
② 내부적으로 동적 배열로 구현되어 있다.
③ 다양한 기능을 제공한다.
④ O(1)에 실행 가능한 연산들도 몇 가지 있다.(.append()로 추가하거나, 리스트 마지막 요소를 pop()으로 추출하거나, 원하는 인덱스의 요소를 조회하는 연산은 모두 O(1)이다.)
리스트의 주요 연산 시간 복잡도는 아래와 같다.
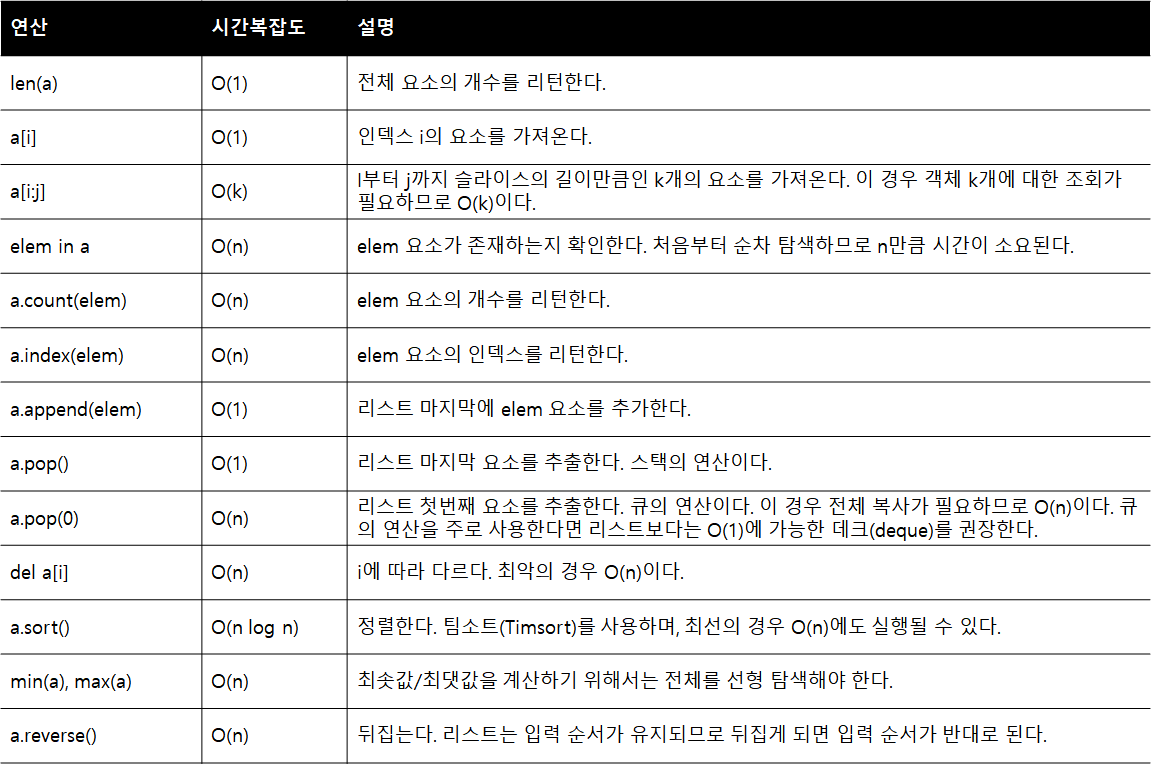
리스트의 경우 탐색 시 값의 존재 유무를 확인하려면 정렬된 경우에는 이진 검색이 효율적이다. 그러나 매번 정렬이 필요하고 대개는 리스트가 정렬된 상태가 아니기 때문에, 리스트의 경우에는 모든 엘리먼트를 순차적으로 조회하는 형태로 구현되어 있다. 이 경우 최악의 경우 항상 O(n)이 소요된다
리스트의 활용 방법
리스트는 다음과 같이 선언한다.
>>> a = list()
또는
>>> a = []다음과 같이 초깃값을 지정해 선언하거나 append()로 추가할 수 있다.
>>> a = [1, 2, 3]
>>> a
[1, 2, 3]
>>> a.append(4)
>>> a
[1, 2, 3, 4]insert() 함수를 사용하면 특정 위치의 인덱스를 지정해 요소를 추가할 수 있다.
>>> a.insert(3, 5)
>>> a
[1, 2, 3, 5, 4]파이썬의 리스트는 숫자 외에도 다양한 자료형을 단일 리스트에 관리할 수 있어 매우 편리하다.
>>> a.append('안녕')
>>> a.append(True)
>>> a
[1, 2, 3, 5, 4, '안녕', True]값을 꺼내올 때는 다음과 같이 간단히 인덱스를 지정하면 된다.
>>> a[3]
5파이썬 리스트에서는 슬라이싱 기능이 있어 특정 범위 내의 값을 매두 편리하게 가져올 수 있다. 원래 슬라이싱은 문자열에 유용하게 활용되는 기능으로서, 리스트에도 동일한 형태로 매우 유용하게 활용할 수 있다.
다음과 같이 인덱스 1에서 인덱스 3 이전까지의 값을 가져와 보자.(인덱스 3은 포함되지 않는다.)
>>> a[1:3]
[2, 3]시작 인덱스는 다음과 같이 생략할 수 있다.
>>> a[:3]
[1, 2, 3]또는 종료 인덱스를 생략할 수 있다.
>>> a[4:]
[4, '안녕', True]다음과 같이 홀수 번째 인덱스의 값만 가져올 수도 있다.
# 인덱스 1, 2, 3의 값
>>> a[1:4]
[2, 3, 5]
# 인덱스 1, 3의 값
>>> a[1:4:2]
[2, 5]원래 [1:4]는 인덱스 1, 2, 3의 값을 가져오지만 이처럼 세 번째 파라미터를 부여하면 단계의 의미로, [1:4:2]와 같이 단계를 2로 지정할 경우 두 칸씩 건너뛰게 된다.
존재하지 않는 인덱스를 조회할 경우 IndexError가 발생한다. 이는 다음과 같이 try 굼눈으로 에러에 대한 예외 처리를 할 수 있다.
try:
print(a[9])
except IndexError:
print('존재하지 않는 인덱스')리스트에서 요소를 삭제하는 방법은 다음과 같이 크게 2가지가 있다.
- 인덱스로 삭제하기
- 값으로 삭제하기
del 키워드를 사용하면 인덱스의 위치에 있는 요소를 삭제할 수 있다.
>>> a
[1, 2, 3, 5, 4, '언녕', True]
>>> del a[1]
>>> a
[1, 3, 5, 4, '안녕', True]다음과 같이 remove() 함수를 사용하면 값에 해당하는 요소를 삭제할 수 있다.
>>> a
[1, 3, 5, 4, '안녕', True]
>>> a.remove(3)
>>> a
[1, 5, 4, '안녕', True]pop()함수를 사용하면 스택의 팝 연산처럼 추출로 처리된다. 즉 삭제될 값을 리턴하고 삭제가 진행한다.
>>> a
[1, 5, 4, '안녕', True]
>>> a.pop(3)
'안녕'
>>> a
[1, 5, 4, True]리스트의 특징
파이썬의 리스트는 연속된 공간에 요소를 배치하는 배열의 장점과 다양한 타입을 연결해 배치하는 연결 리스트의 장점을 모두 취했다. 때문에 파이썬은 아예 원시 타입인 배열은 제공하지도 않을 정도이다.
일반적으로 정수형 배열이라고 하면, 정수로만 이뤄진 값을 연속된 메모리 공간에 저장하는 경우를 말하며, 정수가 아닌 값은 저장할 수 없다. 그러나 파이썬의 리스트는 연결 리스트에 대한 포인터 목록을 관리하고 있기 때문에 정수, 문자, 불리언 등 제각기 다양한 타입을 동시에 단일 리스트에서 관리하는게 가능하다.
그러나 각 자료형의 크기는 저마다 서로 다르기 때문에 이들을 연속된 메모리 공간에 할당하는 것은 불가능하다. 결국 각각의 객체에 대한 참조로 구현할 수밖에 없다. 인덱스를 조회하는 데에도 모든 포인터의 위치를 찾아가서 타입 코드를 확인하고 값을 일일이 살펴봐야 하는 등 추가적인 작업이 필요하기 때문에, 속도 면에서도 훨씬 더 불리하다.
딕셔너리
파이썬의 딕셔너리는 키/값 구조로 이뤄진 딕셔너리를 말한다. 파이썬에서는 입력 순서가 유지되며, 내부적으로는 해시 테이블로 구현되어 있다.
인덱스를 숫자로만 지정할 수 있는 리스트와 달리 딕셔너리는 문자를 포함해 다양한 타입을 키로 사용할 수 있다. 특히 파이썬의 딕셔너리는 해시할 수만 있다면 숫자뿐만 아니라, 문자, 집합까지 불변 객체를 모두 키로 사용할 수 있다. 이 과정을 해싱이라고 하며, 해시 테이블을 이용해 자료를 저장한다.
해시 테이블은 다양한 타입을 키로 지원하면서도 입력과 조회 모두 O(1)에 가능하다. 해시 테이블의 주요 연산과 시간 복잡도는 아래와 같다.
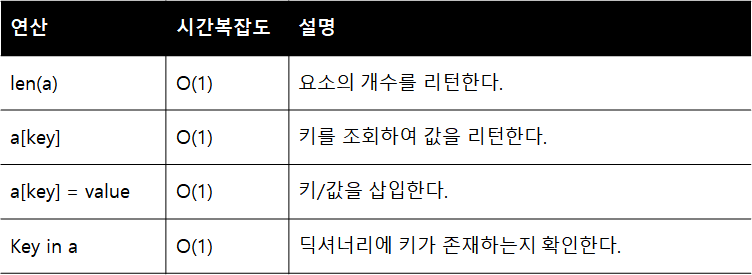
딕셔너리는 대부분의 연산이 O(1)에 처리 가능한 매두 우수한 자료형이다. 키/값 구조의 데이터를 저장하는 유용한 자료형으로서, 코딩 테스트에서도 리스트만큼이나 매우 빈번하게 활용된다.
딕셔너리의 활용 방법
딕셔너리는 다음과 같이 선언할 수 있다.
>>> a = dict()
또는
>>> a = {}다음과 같이 key1, key2는 초기값으로 지정해 선언학저나 key3처럼 나중에 별도로 선언하여 value3라는 값을 할당할 수 있다.
>>> a = {'key1':'value1', 'key2':'value2'}
>>> a
{'key1': 'value1', 'key2': 'value2'}
>>> a['key3'] = 'value3'
>>> a
{'key1': 'value1', 'key2': 'value2', 'key3': 'value3'}리스트에서는 존재하지 않은 인덱스를 조회할 경우 IndexError가 발생하며, 딕셔너리에서는 존재하지 않는 키 key4를 조회하면 KeyError 에러가 발생한다. 다음과 같이 try 구문으로 예외 처리를 할 수 있다.
>>> if 'key4' in a:
print('존재하는 키')
else:
print('존재하지 않는 키')딕셔너리에 있는 키/값은 for 반복문으로도 조회가 가능하다. 다음과 같이 딕셔너러의 itmes() 메소드를 사용하면 키와 값을 각각 꺼내올 수 있다.
>>> for k, v in a.items():
print(k, v)
key1 value1
key2 value2
key3 value3딕셔너리의 키는 다음과 같이 del로 삭제한다.
>>> del a['key1']
>>> a
{'key2': 'value2', 'key3': 'value3'}딕셔너리 모듈
딕셔너리와 관련된 특수나 형태의 컨테이너 자료형인 defaultdict, Counter, OrderedDict에 대해 각각 살펴보자.
defaultdict 객체
defaultdict 객체란?
존재하지 않는 키를 조회할 경우. 에러 메시지를 출력하는 대신 디폴트 값을 기준으로 해당 키에 대한 딕셔너리 아이템을 생성해준다.
실제로는 collections.defaultdict클래스를 갖는다.
>>> a = collections.defaultdict(int)
>>> a['A'] = 5
>>> a['B'] = 4
>>> a
defaultdict(<class 'int'>, {'A': 5, 'B': 4})>>> a['C'] += 1
>>> a
defaultdict(<class 'int'>, {'A': 5, 'B': 4, 'C': 1})원래의 딕셔너리라면 KeyError가 발생하겠지만, defaultdict 객체는 에러 없이 바로 +1 연산이 가능하고 이 경우 디폴트인 0을 기준으로 자동으로 생성한 후 여기에 1을 더해 최종적으로 1이 만들어진다.
Counter 객체
Counter 객체란?
아이템에 대한 개수를 계산해 딕셔너리로 리턴한다.
>>> a = {1, 2, ,3, 4, 5, 5, 5, 6, 6}
>>> b = collections.Counter(a)
>>> b
Counter({5: 3, 6: 2, 1: 1, 2: 1, 3: 1, 4: 1})Counter 객체는 키에는 아이템의 값이, 값에는 해당 아이템의 개수가 들어간 딕셔너리를 생성한다.
Counter 객체에서 가장 빈도 수가 높은 요소는 most_common()을 사용하면 된다.
>>> b.most_common(2)
[(5, 3), (6, 2)]OrderedDict 객체
대부분의 언어에서 해시 테이블을 이용한 자료형은 입력 순서가 유지되지 않는다.
파이썬도 3.6 이하에서는 마찬가지였고 입력 순서가 유지되는 OrderedDict라는 별도의 객체를 제공했다.
>>> collections.OrderedDict({'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2})
OrderedDict([('banana', 3), ('apple', 4), ('pear', 1), ('orange', 2)])그러나 파이썬 3.7부터 딕셔너리는 내부적으로 인덱스를 이용하며 입력 순서가 유지되도록 개선했다. 따라서 더 이상 OrderedDict를 사용할 필요는 없으며 기본 딕셔너리만 사용해도 입력 순서가 충분히 유지된다.
그러나 코딩테스트 시 하위 버전의 파이썬 인터프리터를 사용하는 경우가 있고, 원래 해시 테이블은 입력 순서에 관여하지 않는 자료형인 만큼, 무턱대고 딕셔너리로 입력 순서를 기대하는 것은 매우 위험하며 권장하지도 않는 방법이다.
