다음과 같은 상황은 어떻게 해결할까?
DB에서 직원의 salary를 보고 5년동안 3번 이상의 인상이 일어나지 않으면 인상을 하고 담당자에게 이메일을 보내야한다. 하지만 SQL은 어떤 데이터를 사용할 건지만 명시할 뿐 어떻게 비즈니스 로직을 처리할지는 정할 수 없다.
이러한 문제를 처리하는 방법은 클라이언트 사이드, 서버 사이드 2가지가 존재한다.
클라이언트
- 전처리기에 SQL문을 submit
- JDBC나 OCI(Oracle Call Interface)를 통해 DB와 상호작용
서버
- 서브 프로그램을 호출하여 처리 ( PL/SQL, Java, Trigger )
Trigger: 특정 이벤트가 발생하였을 때, 호출되는 named program unit
서버 사이드에서 처리하면 다음과 같은 이점이 있다.
- DB에 내장된 기능이라 어디든지 배포가 가능하다.
- DB가 주어진 OS에서 최고의 작업 방식을 찾아서 수행한다.
- 로직이 서버로 모두 집중되기 때문에 확장성이 높아지고, 클라이언트 코드를 재사용할 수 있음.
- 서브 프로그램은 호출이 상당히 빠르고 효율적임. 이를 통해 네트워크 트래픽을 낮출 수 있다.
왜 우린 JDBC를 사용하나?
서버 사이드에서 처리하면 확장성도 높아지고, 속도도 빠르고, 트래픽도 낮다니.. 매우 좋아보인다. 그런데 왜 요즘 트렌드는 JDBC를 사용하여 클라이언트에서 로직을 처리하는걸까?
서버 사이드에서 처리할 경우 다음과 같은 단점이 존재한다.
-
객체지향 패러다임과 맞지 않는다.
요즘은 객체지향적 패러다임이 대세이다. 따라서 비즈니스 로직의 모델링 역시 객체지향의 모델링을 통해 구현하는 것이 일반적이다. 허나 이를 이름부터가 절차지향적인 PL/SQL로 구현하기란 어렵다. -
vendor에 종속적이다.
관리 측면에서 vendor에 종속되는 PL/SQL은 상당히 비효율적이다. JDBC는 connection만 수정하면 vendor를 언제든지 상황에 맞게 바꿀 수 있다. -
오류 검출이 매우 어렵다.
아무리 로그가 잘 되어있더라도 IDE 수준 차이가 엄청나서 오류를 검출하기 상당히 어렵다. -
형상 관리가 어렵다
관련 IDE가 존재하긴 하지만, 기본적으로는 git 같은 형상 관리 툴을 사용할 수 없다.
허나 DB를 변경할 필요가 없는 환경에서 복잡한 스키마를 처리해야 하는 상황이라면, 서버 사이드 방식도 고려할만한 옵션이다.
PL/SQL(Procedural Language/SQL)
PL/SQL은 함수와 프로시저로 나누어진다. 함수는 값을 반환하는 반면, 프로시저는 그렇지 않다는 차이점이 있다.
PL/SQL의 장점
-
낮은 네트워크 트래픽
계속 SQL문을 보내줘야하는 클라이언트 사이드에 비해 한 번만 호출되면 메모리에 상주되는 PL/SQL은 네트워크 트래픽을 덜 잡아먹는다. (근데 실제로 네트워크 bottleneck은 잘 일어나지 않아서 장점이라고 보기엔 좀 애매하다.) -
메모리 할당
프로시저는 한 번 호출되면 SGA(System Global Area)의 shared pool에 올라가서 별도의 disk 조회 없이 바로 사용이 가능하다. 이로인해 다양한 사용자가 존재하더라도 한 개의 copy만 메모리에 상주하면 되기 때문에 메모리 사용량이 줄어든다. -
보안
저장 프로시저는 권한에 따라 접근할 수 있는 유저가 다르기 때문에, 다른 사용자가 데이터에 접근하는 것을 막거나 특정 프로시저로만 접근 하도록 접근 방식을 제한할 수 있다.
SGA(System Global Area)의 자세한 내용은 이전에 작성해 둔 글에 나와있다.
SGA와 PGA
Tibero7에서는 V$SGA를 통해 조회할 수 있다.
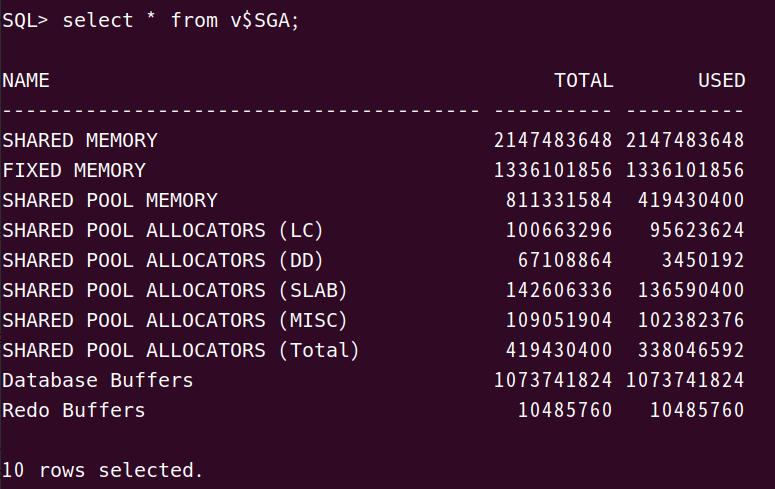
DB Buffer Cache
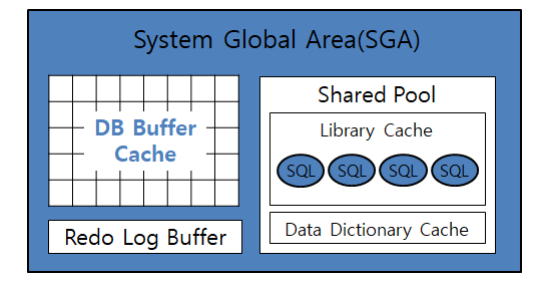
현재 DB Buffer Cache에 관한 업무를 하고 있는데, 버퍼캐시가 SGA에 들어있다는 걸 상기하게 되었다. 그래서 이 부분에 대해 조금 더 자세하게 알아보려고 한다.
앞서 PL/SQL의 장점에서 설명한 바와 같이, 서버 프로세스는 데이터 블록을 읽을 때 항상 버퍼캐시부터 탐색을 하는데 이때, 캐시가 히트할 경우 Disk I/O를 하지 않고 캐시에서 불러온다. 실패할 경우 Disk I/O를 한다. 전기적 신호로 메모리에서 읽어오는 캐시가 액세스 암(Access Arm)이 움직여서 찾는 Disk I/O보다 훨씬 빠르다. 즉 버퍼캐시가 많이 히트될수록 성능이 향상되는 것이다.
버퍼캐시 히트율(Buffer Cache Hit Ratio, 'BCHR')
BHCR = ( 캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록 수 ) × 100
= ( ( 논리적 I/O - 물리적 I/O ) / 논리적 I/O ) × 100
= ( 1 - ( 물리적 I/O ) / (논리적 I/O ) ) × 100논리적 I/O : 캐시 히트가 되어 캐시에서 불러오는 경우
물리적 I/O: 캐시 실패가 되어 Disk I/O를 하는 경우
online transaction을 수행하는 어플리케이션이라면 평균 99%를 달성해야 한다고 한다.
BCHR을 높일 수 있는 방법?
BCHR을 높일 수 있는 방법으로는 캐시 전략 최적화, 쿼리 최적화, 다중 버퍼 풀(Multi-Buffer Pool) 등이 다양한 방법이 존재한다.
이 중에서 가장 쉬운 방법은 버퍼 캐시 사이즈를 늘리는 것이다. 그런데 무작정 사이즈를 키우면 다음과 같은 문제가 발생할 수 있다.
-
메모리 자원 낭비
사용되지 않는 메모리가 많아서 자원이 낭비될 수 있다. -
캐시 관리 오버헤드 및 검색 시간 증가
캐시 메모리가 너무 크면 관리를 하기 위한 오버헤드가 증가할 수 있는데, 대표적으로 캐시 일관성 문제가 있다. 또한 커진 캐시가 너무 크면 검색을 하는데 시간이 증가가 된다.
캐시 일관성 관리: 실제 데이터와 캐시를 일관성 있게 유지하기 위한 동기화 작업
-
비용 증가
더 많은 메모리 자원이 필요하다는 건 하드웨어 비용이 증가한다는 것이다. -
최적화의 어려움
너무 큰 캐시를 운영하면, 캐시를 최적화하기가 더 복잡해진다.
따라서 무작정 늘리는 것보단 모니터링을 통해 다양한 지표를 보고 현재 시스템에서 어떤 사이즈가 가장 적절한지 찾아내는 것이 중요하다. 이를 통해 BCHR을 높인다면, DB 성능을 향상 시킬 수 있다.
BCHR이 높다고해서 무조건 성능이 빠르다고 장담할 순 없는데, BCHR은 똑같은 캐시만 비효율적으로 참조하는 것도 캐시 히트율에 포함하기 때문이다.
Oracle JVM
오라클 데이터베이스에는 JVM이 내장되어, DB내에서 자바 라이브러리를 활용한 다양한 작업을 네이티브하게 할 수 있다.
-
Java Stored Procedure
자바 저장 프로시저를 통해 Java코드를 DB내에서 직접 실행할 수 있다.이를 통해 DB내에서 복잡한 비즈니스 로직을 수행할 수 있다. -
SQL,PL/SQL에서 자바 호출
Java 메소드를 통해 SQL,PL/SQL을 호출할 수 있고, 역으로도 가능하다.
JDBC vs SQLJ
자바를 통해 SQL 데이터에 접근할 수 있는 방법은 JDBC, SQLJ 2가지가 존재하며, 섞어서 사용할 수도 있다.
JDBC
자바 API를 사용해서 SQL을 보내는 방식.
- vendor와 상관없이 JDBC API를 지원하는(java.sql을 구현한) DB에 사용 가능.
- DB와 interact할 때 자동으로 optimized됨. 해당 과정은 비싸며, 불필요한 반복이 발생할 수 있음.
- dynamic하기에 동적 쿼리를 만들기 적합함.
- optimized를 신경 써야하기 때문에 사용하기가 SQLJ에 비해 어려움
- SQL문이 String으로 작성되기 때문에, 컴파일 과정에서 오류 검출이 불가능함.
SQLJ
자바 코드에 SQL문을 직접 임베딩하는 방식.
- 자바로 만들어지긴 했지만, Oracle, IBM을 제외하면 지원하는 vendor가 없음.
- DB와 interact할 때 쓰여진 코드가 그대로 보내짐. 즉, optimized 되지 않음. 대신에 값싸고 빠름.
- static하기 때문에 동적 쿼리를 만들기에 적합하지 않음.
- 간결하고 디버깅이 편한 코드라서 사용하기 쉬움.
- precompiled하기 때문에, 컴파일 과정에서 타입, 문법 등 다양한 오류 검출이 가능함.
Trigger
트리거는 DB에 컴파일 되어 저장된 program unit이다. PL/SQL 또는 자바로 작성되어 있을 수 있으며, 앞에서 나온 것들과 다르게 명시적으로 실행할 수 없고, 특정 이벤트가 발생해야 동작한다.
- 특정 테이블이나 뷰에서 DML문이 발생하였을 때.
- 모든 유저 또는 특정 유저에게서 DDL문이 발생하였을 때.
- DB event(로그인, 셧다운 등)가 발생하였을 때.
보통 트리거는 로깅, 기본값 처리 같은 저수준의 비즈니스 로직을 정의할 때 사용한다.
비즈니스 로직을 굳이 DB에서?
현재까지 했던 프로젝트는 모두 DB관련 로직이나 로깅을 Hibernate나 Spring AOP를 통해 처리했었다.
정말 가끔 필요했던 적은 SQL 스케줄러 정도..? 트리거는 일단 존재 자체를 몰랐기도 하고, 굳이 트리거를 쓸 필요성을 못 느꼈기 때문이다. 그렇다면 이 둘의 차이점은 무엇일까?
Trigger
- DB엔진 내에서 직접 작동하기에 매우 빠름.
- 세션에 대한 정보는 가지고 있지 않음.
- 데이터 자체만 로깅함. 즉 비즈니스적 정보에 대한 로깅은 불가능하다.
- 어플리케이션과 독립적인 로직이라서 잘못하면 DB와 어플리케이션이 서로 다른 로직을 가지고 있을 수 있다.
Hibernate
- DBMS에 종속적이지 않음.
- 세션 정보, 트랙잭션 정보, 클라이언트 정보 등 비즈니스 정보에 쉽게 접근 가능.
- 엔티티 뷰가 가능하다. 또한 특정 엔티티에 대한 로깅만 선언하여 다양한 방법으로 로그를 확인할 수 있다.
참조
https://chgpky.tistory.com/41
https://weiqing.tistory.com/507
https://www.quora.com/What-is-the-difference-between-jdbc-and-sqlj
https://stackoverflow.com/questions/769084/implementing-audit-trail-spring-aop-vs-hibernate-interceptor-vs-db-trigger
