
Kafka란?
카프카는 2011년 미국 LinkedIn에서 개발된 오픈소스이며, 여러 대의 분산 서버를 통해 데이터를 수집하고, 수집된 데이터를 다른 시스템에 보내는 메세징 시스템이다. 높은 처리량을 통한 실시간 데이터 처리, 다양한 제품과의 시스템 연계, 메세지의 신뢰성을 보장하여 여러 기업들에서 사용되고 있다. 데이터가 거쳐가는 미들웨어의 역할을 수행하고 있는 셈이다.
Kafka의 3대 핵심요소

1. 생산자(Producer)
- 메세지 생산자이며 브로커의 토픽에게 메세지를 전달하는 역할
- 토픽(topic)이라고 불리우는 브로커의 카테고리를 통해 메세지를 구분할 수 있다.
2. 브로커(Broker)
- 생산자를 통해 전달받은 메세지를 큐(Queue)에 담아둔다.
- 생산자와 소비자 사이에 존재하여 강력한 시스템 아키텍처를 만들 수 있다. 즉, N(생산자) x M(소비자)의 연결 구조를 브로커의 존재를 통해 N(생산자) + M(소비자)로 간단하게 만들었다.
- 브로커는 생산자가 보낸 메세지를 디스크에 영속화하는 기능을 지니고 있어 소비자는 원하는 시간에 데이터를 가져갈 수 있다. (batch성을 띄는 프로세스에도 특화됨)
- 브로커의 토픽(Topic)으로 인하여 단일 카프카 클러스터 환경에서도 여러 종유의 메세지를 중계 할 수 있다.
3. 소비자(Consumer)
- 브로커가 메세지를 전달하는 'push' 개념이 아닌 소비자가 직접 메세지를 브로커의 토픽으로부터 'pull' 하며 메세지를 추출한다.
- 소비자 그룹(Consumer Group)이 존재하여 여러 소비자가 동일 토픽을 분산하여 메세지를 'pull' 하며 읽음으로써 처리의 확장성을 가질 수 있다.
Kafka의 Offset Commit
"카프카는 메세지를 분실하지 않는다."
바로 Ack과 Offset을 통해 신뢰성을 보증한다. Ack은 브로커가 메세지를 수신하면 생산자에게 수신을 완료를 했다는 의미로 응답하는 값이다. 생산자가 메세지를 전달했지만 브로커에게 Ack 응답이 오지 않는다면 생산자는 재전송을 해야한다고 판단을 할 수 있는 척도가 되는 셈이다. 소비자의 경우에는 브로커로부터 메세지를 'pull' 하는데, 소비자가 현재 어느부분까지 메세지를 받았는지 관리하기 위한 offset이 존재하여 이를 이용해 전달 범위를 보증하고 있다. 소비자가 마지막에 읽은 메세지의 대한 offset을 브로커에게 응답하면, 브로커는 다음번 메세지 전송 시, 응답받은 메세지의 offset 이후로 데이터를 허용하는 것이며, 이러한 카프카의 보증구조를 오프셋 커밋이라고 한다.
오프셋 커밋은 소비자 그룹 단위로 이루어지며, 처리를 완료한 메세지의 최대 Offset을 기록하는 방식이다. 이 매커니즘에 의해 카프카 클러스터의 브로커가 정지해도 데이터 손실없이 처리할 수 있다.
Kafka의 구성
1. 주키퍼(Apache Zookeeper)
- 분산 메세징 처리를 위한 메타데이터(토픽, 파티션)를 관리하는 도구
2. 파티션(Partition)
- 토픽의 대량의 메세지 입출력을 지원하기 위해, 브로커에서 메세지를 읽고 쓰는 것은 파티션의 단위로 분할되어 있다. 생산자로부터의 메세지를 수신하고 소비자로부터의 pull요청 모두 분산해서 실시함으로써 하나의 토픽에 대한 대규모 수신과 전달을 지원해주는 역할을 담당하고 있다.
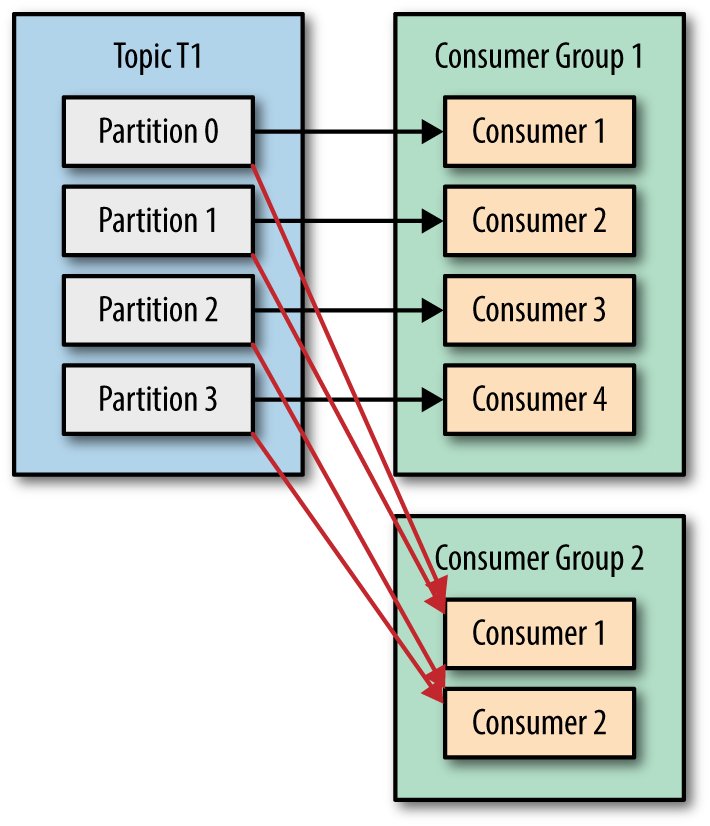
3. 소비자 그룹(Consumer Group)
- 카프카는 소비자에서도 분산 스트림 처리를 고려하도록 설계되어 있어 소비자는 자신이 속한 그룹을 식별하고 읽어들일 토픽과 파티션을 소비자 그룹에 따라 제어한다.
- 소비자 그룹은
Group ID가 동일한 소비자끼리 형성되며, 그룹 내에서 메세지를 분산 수신한다. - 특정 메세지를 소비자 그룹의 어느 소비자가 수신하는지에 대한 할당은 수신할 토픽에 존재하는 파티션과 소비자 그룹 내의 소비자를 매핑함으로 통해 결정된다.(각 파티션에 반드시 하나 이상의 소비자가 매핑된다.)
- 토픽의 파티션 수 보다 소비자의 수가 많을 경우, 파티션이 할당되지 않은 소비자가 발생할 수 있다.(파티션 수 >= 소비자의 수로 설계하는 것이 좋다.)
4. 오프셋(Offset)
- 파티션에서 수신한 메세지는 파티션 단위로 일련번호가 부여되어 현재까지 읽은 메세지 위치를 나타내는 값을 의미한다.
Kafka Replication
카프카는 메세지를 주고 받음과 동시에 서버 장애가 발생했을때 브로커에 수신된 메세지를 유지하기 위해 Replication(복제) 기능이 존재한다. 단 하나의 원본을 Leader로 나머지를 Follower로 지정한다. Follower는 Leader로부터 메세지를 취득하여 복제상태만 유지하고 생산자와 소비자와의 데이터 교환은 Leader가 직접 담당한다.
