Python의 자료구조에 대해 간략히 포스팅하겠습니다.
1. List
1-1. range
List와 range는 함께 쓰이는 경우가 많으니 같이 알아보겠습니다.
먼저, range의 문법은 다음과 같습니다.
range(start, end, step)
예를 들어보면,
list(range(1, 10, 3))
>>>[1,4,7]
list(range(20,10,-2))
>>>[20, 18,16, 14,12]여기서 step을 정하지 않고 range(start, end)로 사용하면
list(range(1, 5))
>>>[1,2,3,4]
#step은 1이 default 값그리고 range(end)만 사용하게 되면
list(range(5))
>>>[0,1,2,3,4]
#start는 0이 default 값
#step은 1이 default 값1-2. Slice
Python에서 slicing은 메소드를 통해 따로 진행하지 않고 매우 간단하게 구현할 수 있습니다.
문법은 다음과 같습니다.
list[start : end : step]
range에서는 ,를 사용하고 slicing에서는 :를 사용합니다.
a = [0,1,2,3,4,5]
a[0:5:2] == [0,2,4]
a[0:2] == [0,1] #step의 default는 1
a[:3],[0,1,2] #start를 공백으로 남겨두면 첫번째부터
a[1:] == [1,2,3,4,5] #end를 공백으로 남겨두면 끝까지
a[1:7] == [1,2,3,4,5] #end값이 list의 범위를 넘으면 끝까지 slicing
a[:] == [0,1,2,3,4,5] #전체를 slicing
a[::2] == [0,2,4] #전체에서 step을 정해서 slicing1-3. list 요소 삭제
1-3-1. del keyword
list의 index값을 이용해 요소를 삭제합니다.
a = [0,1,2,3,4,5]
del a[1]
print(a)
>>> [0,2,3,4,5]
1-3-2. remove method
del keyword를 사용하는 것은 요소의 index를 알아야지만 지울 수 있습니다. 만약 index값을 모르고 요소만 알고 있을 때는 remove method를 사용합니다.
laptop_brand = ["SAMSUNG", "LG", "ASUS", "Apple"]
laptop_brand.remove("ASUS")
print(laptop_brand)
>>>["SAMSUNG, "LG", "Apple"]1-4. list 요소 추가
1-4-1. List.append
color_list = ["Red", "Blue", "Green", "Black"]
color_list.append("Yellow")
print(color_list)
>>> ['Red', 'Blue', 'Green', 'Black', 'Yellow']1-4-2. List +
list1 = [1, 2, 3]
list2 = [4, 5, 6]
list1 = list1 + list2
print(list1)
>>> [1,2,3,4,5,6]1-4-3. List.insert
insert는 list의 index를 지정해서 요소를 추가할 수 있습니다.
cities = ["서울특별시","부산광역시","인천광역시"]
cities.insert(1, "제주특별자치도")
print(cities)
>>> ["서울특별시", "제주특별자치도","부산광역시","인천광역시"]2. Tuple
List는 []로 감싸줬다면 Tuple은 ()로 감싸줍니다.
tuple의 경우, 보통 2~5개의 요소를 담을 때 사용합니다.
그리고 한번 담은 자료는 수정이 불가합니다.
예를 들어, 좌표값은 변하지 않으므로 이러한 자료는 tuple에 저장합니다.
그리고 list처럼 수정, 추가, 삭제 등이 불가하니 메모리를 적게 차지하는 장점이 있습니다.
정리
- 수정불가
- 2 ~ 5개의 요소 담을 때 사용
- 메모리 적게 차지
2-1. tuple indexing
>>> t1 = (1, 2, 'a', 'b')
>>> t1[0]
1
>>> t1[3]
'b'2-2. tuple slicing
>>> t1 = (1, 2, 'a', 'b')
>>> t1[1:]
(2, 'a', 'b')2-3. tuple +
>>> t1 = (1, 2, 'a', 'b')
>>> t2 = (3, 4)
>>> t1 + t2
(1, 2, 'a', 'b', 3, 4)2-4. tuple *
>>> t2 = (3, 4)
>>> t2 * 3
(3, 4, 3, 4, 3, 4)3. Set
List는 [], tuple은 (), set는 {}
그리고 한가지 첨언하자면 dictionary도 {}로 마크하는데
비어있는 set를 선언할 때는 empty_set1 = set()으로 생성해야합니다.
empty_set1 = {}의 경우, 비어있는 dictionary를 생성하게 됩니다.
3-1. Set 비순서형, 중복 비허용
Set 자료형의 요소들은 list나 tuple처럼 순서가 없고 중복을 허용하지 않습니다.
Set는 다음과 같이 생성하게 됩니다.
>>> s1 = set([1,2,3,3,2]) #기존의 list를 set으로 만들기 가능
>>> s1
{1, 2, 3}>>> s2 = set("Hello") #string도 set으로 만들기 가능
>>> s2
{'e', 'H', 'l', 'o'}3-2.Set 요소 제거
3-2-1.remove method
비순서 자료형이기 때문에 특정 요소를 지정해서 지워주는 remove method를 사용합니다.
>>> s1 = set([1, 2, 3])
>>> s1.remove(2)
>>> s1
{1, 3}3-3.Set 요소 추가
3-3-1. add (한 개의 요소 추가하기)
>>> s1 = set([1, 2, 3])
>>> s1.add(4)
>>> s1
{1, 2, 3, 4}3-3-2. update (여러 요소 추가하기)
>>> s1 = set([1, 2, 3])
>>> s1.update([4, 5, 6])
>>> s1
{1, 2, 3, 4, 5, 6}3-4. Set Look-Up
set에 어떤 요소가 포함되어 있는지 확인하는 과정을 Look-Up이라고 표현합니다.
Look-Up은 다음과 같이 진행합니다.
my_set = {1, 2, 3}
if 1 in my_set:
print("1 is in the set")
>>> 1 is in the set
if 4 not in my_set:
print("4 is not in the set")
>>> 4 is not in the set3-5. Set 합집합, 차집합, 교집합
다음과 같은 set이 있다고 가정해보겠습니다.
그리고 각 예제를 살펴보면서 어떻게 합집합, 차집합, 교집합을 구하는지 알아보겠습니다.
>>> s1 = set([1, 2, 3, 4, 5, 6])
>>> s2 = set([4, 5, 6, 7, 8, 9])3-5-1. Set 합집합 Union
# |(or) 기호 사용
>>> s1 | s2
{1, 2, 3, 4, 5, 6, 7, 8, 9}# union method 사용
>>> s1.union(s2)
{1, 2, 3, 4, 5, 6, 7, 8, 9}
3-5-2. Set 차집합 difference
# - 기호 사용
>>> s1 - s2
{1, 2, 3}
>>> s2 - s1
{8, 9, 7}# difference method 사용
>>> s1.difference(s2)
{1, 2, 3}
>>> s2.difference(s1)
{8, 9, 7}
3-5-3. Set 교집합 intersection
# &(and) 기호 사용
>>> s1 & s2
{4, 5, 6}# intersection method 사용
>>> s1.intersection(s2)
{4, 5, 6}
4. dictionary
Javascript의 Object와 같은 역할을 합니다.
dictionary의 기본 모습은 다음과 같습니다.
dict = {Key1:Value1, Key2:Value2, Key3:Value3, ...}
dictionary의 가장 큰 특징은 list나 tuple처럼 순차적으로(sequential) 해당 요솟값을 구하지 않고 Key를 통해 Value를 얻습니다.
Key의 경우 String이나 number로 지정해줄 수 있습니다.
그리고 Key는 중복될수 없습니다.
만약 중복되면 나중값으로 치환됩니다.
dict1 = { 1 : "one", 1 : "two" }
print(dict1)
>>> { 1: "two" }4-1. dictionary Key-Value 삭제
del keyword를 사용해서 삭제합니다.
a = {"name" : "junkyuu",
"gender" : "male"}
del a["gender"]
print(a)
>>> {"name" : "junkyuu"}4-2. dictionary Key-Value 추가
a = {"name" : "junkyuu"}
a["gender"] = "male"
print(a)
>>>{"name" : "junkyuu", "gender" : "male"}
4-3 dictionary for-loop
dictionary에서 for문을 돌리면 key에 접근합니다.
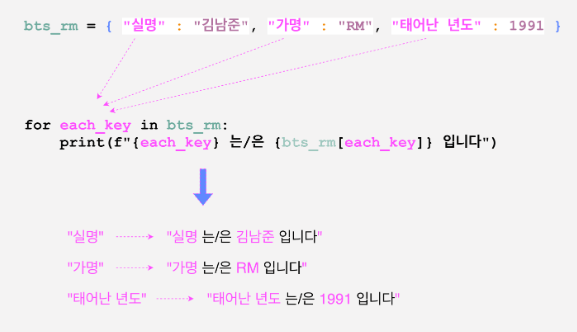
만약, value에 접근하고 싶다면 다음과 같이 dictionary.value()에서 접근하면 됩니다.
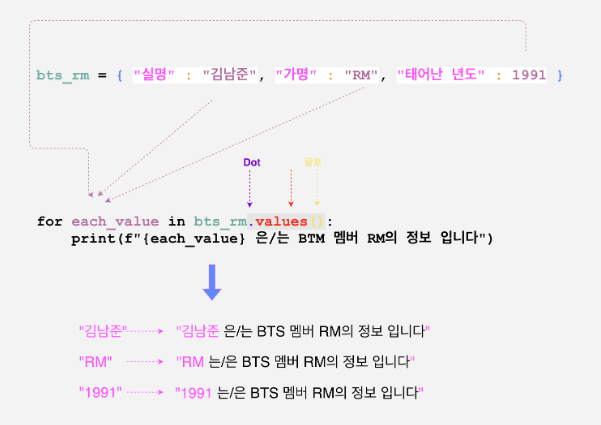
5. 비어있는 자료형은 false값을 가진다.
비어있는 string, list, tuple, set, dictionary는 false값을 가집니다.
# a = ""
# a = []
# a = ()
# a = set()
# a = {}
if not a:
print(f"a 는 false")