Pandas 심화
Pandas 조건으로 검색하기
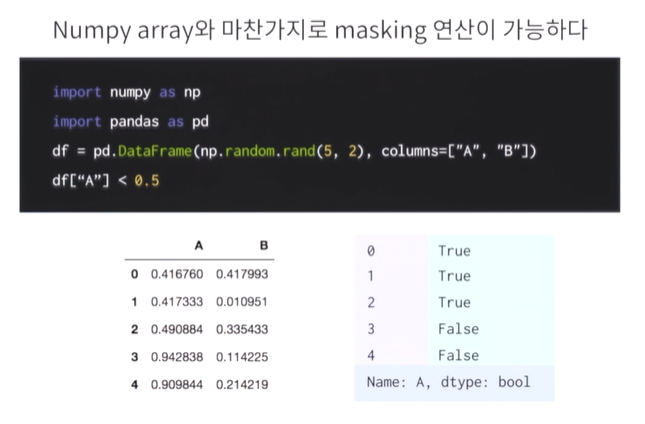
위 사진을 보면 True, False 결과가 나오는 데 이를 이용하여 마스킹 연산이 가능하다.
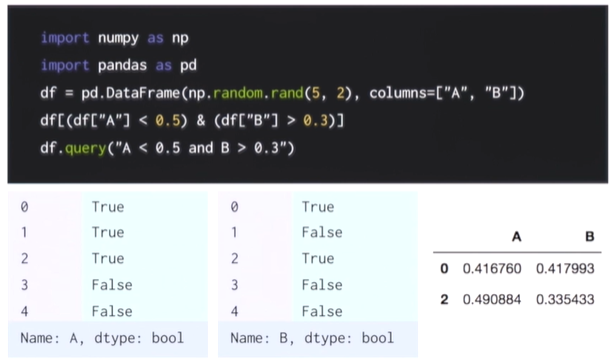
df[(df["A"]<0.5)&(df["b"]>0.3)]위 소스에서
(df["A"]<0.5)&(df["b"]>0.3)를 실행 했을 때 그 전 사진 처럼 Ture,False가 출력이 된다 이를 이용하여 다시 한번 df[ ] 안에 넣는다면 True에 해당되는 값이 출력이 된다.
df.query("A<0.5 and B>0.3")이 코드는 query라는 함수를 이용하여 ( ) 안에 있는 조건을 실행 후 출력을 해준다.
문자열이면 다른 방식으로도 검색이 가능하다.
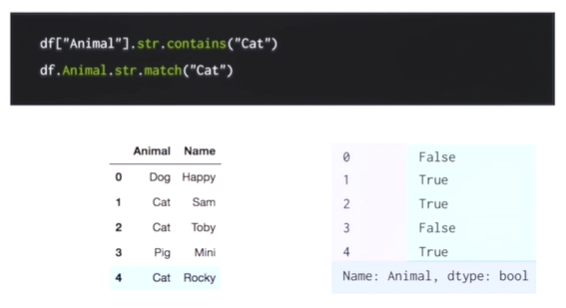
df["animal"].str.contains("Cat")
df.animal.str.match("Cat")- contains같은 경우 ( )안에 있는 문자열이 포함이 되면 True와 False를 반환한다.
- match 같은 경우 완전히 똑같은 경우에만 True가 반환이 되고 아닐 경우 False가 반환이 된다.
df["animal"] == "Cat"위 소스 역시 똑같은 결과가 나온다.
함수로 데이터 처리하기
- apply
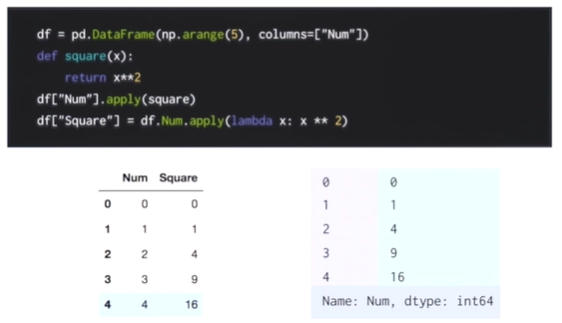
df["Num"].apply(squere)같은 경우는 Num이라는 곳에 함수를 인자로 넣는 걸 의미한다.
그 결과 제곱된 결과가 오른쪽 출력사진 처럼 출력이 된다.
df["Square"] = df["Num"].apply(square)위 코드 처럼 사용한다면 동일하게 출력이 된다.

위 사진처럼 데이터가 있을 경우 이를 처리하기 위해 아래 사진처럼 함수를 작성한다.

- replace
: apply 기능에서 데이터 값만 대체 하고 싶을 때
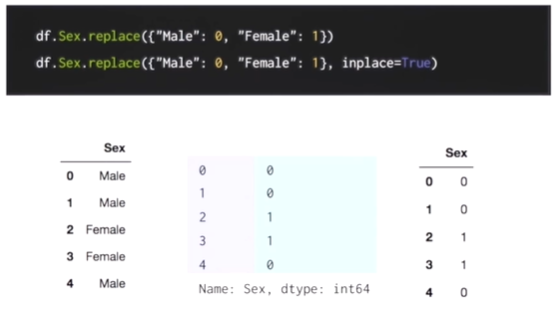
첫번째 코드를 돌릴 경우 두번째 사진처럼 시리즈 형식으로 출력이 되고
inplace = true를 넣을 경우 오른쪽 사진처럼 출력이 된다.
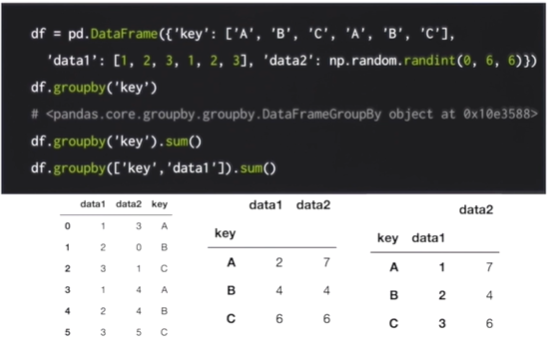
groupby('key')해당 코드는 key 값을 기준으로 그룹을 이루게된다.
groupby('key').sum()코드 같은 경우 key값 기준으로 더한 값으로 그룹을 이룬다.
groupby(['key','data1']).sum()해당 소스는 key와 data1을 그룹으로 정렬하고 sum연산을 진행하여 추가로 데이터 출력이 된다.
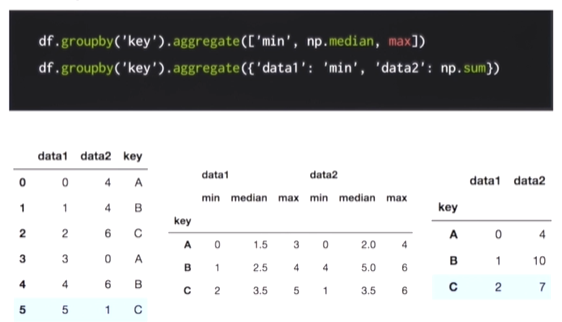
aggregate를 통해 집계를 한번에 계산할 수 있다.
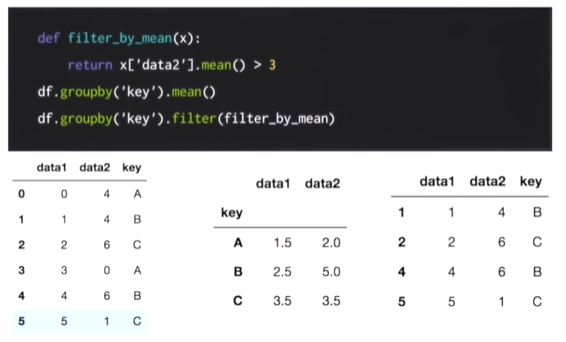
filter를 통해 그룹 속성을 기준으로 데이터를 필터링하여 출력할 수 있다.
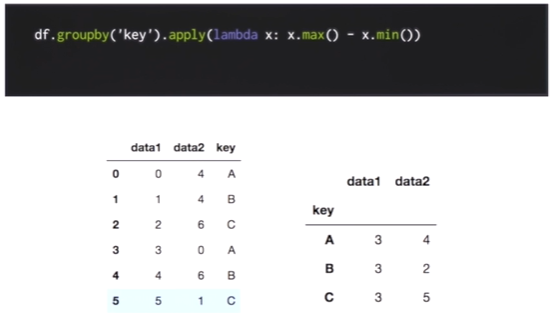
groupby로 묶인 데이터도 apply가 가능하다.
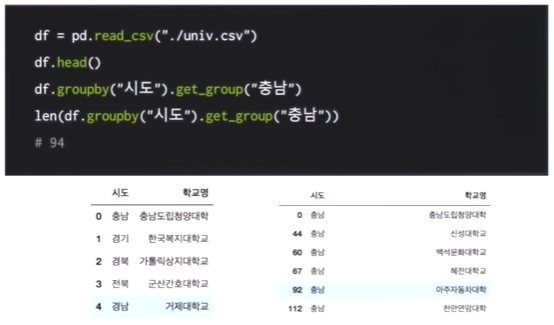
get_group 을 통해 묶인 데이터에서 key 값으로 데이터를 갖고올 수 있다.
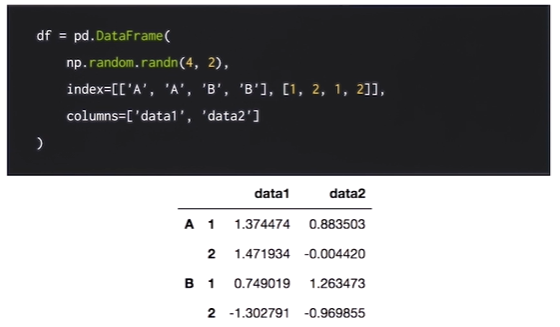
MultiIndex
인덱스를 계층적으로 만들 수 있다.

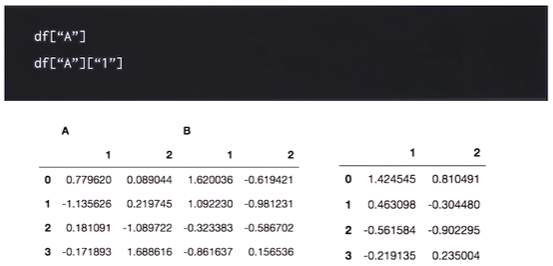
다중 인덱스 컬럼의 경우 인덱싱은 계층적으로 가능하다.
인덱스 탐색의 경우 loc,iloc를 사용할 수 있다.
povot_table
- 데이터에서 필요한 자료만 뽑아서 새롭게 요약
- 분석할 수 있는 기능 엑셀에서의 피봇 테이블과 같다.
- 필요한 데이터
- index : 행 인덱스로 들어갈 key
- column : 열 인덱스로 라벨링될 값
- value : 분석할 데이터
아래와 같이 데이터가 있을 경우
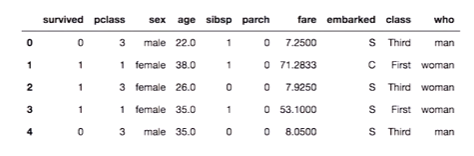
성별과 좌석별 생존률을 구하려면 아래와 같이 구할 수 있다.
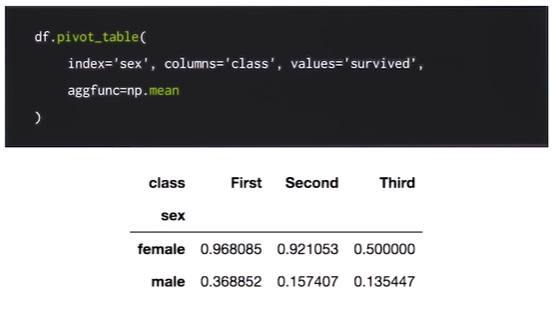
아래와 같이 왼쪽 사진처럼 데이터가 있을 경우

