
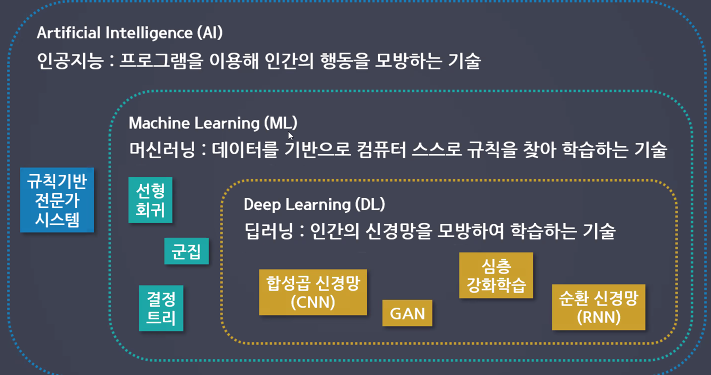
딥러닝이란?
-
딥러닝이란?
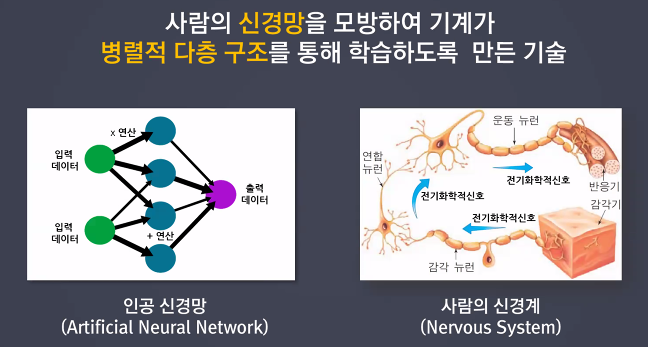
- 사람의 신경망을 모방하여 기계가 병렬적 다층 구조를 통해 학습하도록 만든 기술
- 판단 기준이 명확히 정해져있다.
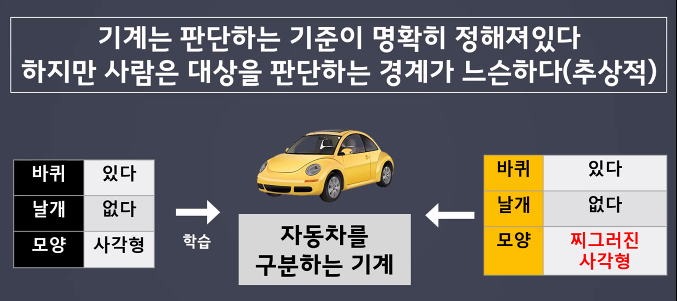
- 사람의 신경망을 모방하여 기계가 병렬적 다층 구조를 통해 학습하도록 만든 기술
-
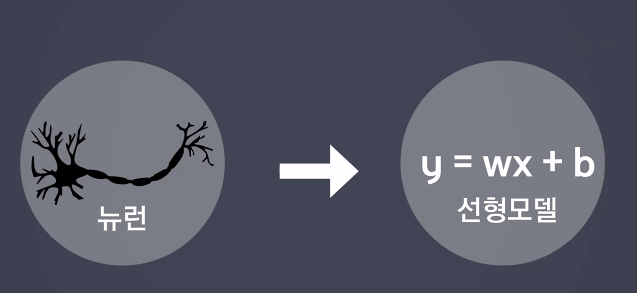
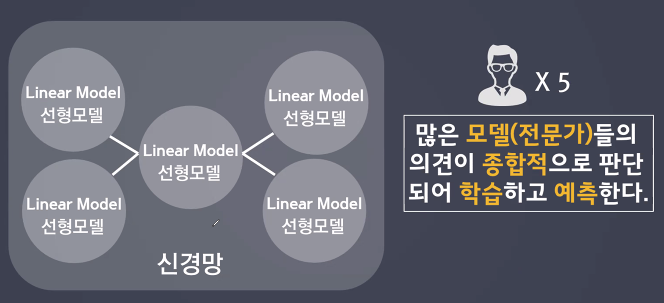
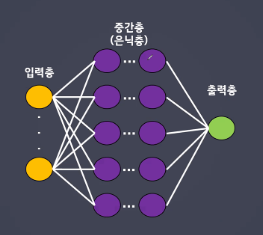
다중 퍼셉트론
: 많은 선형 모델을 활용하여 결과를 도출한다.
- 예시
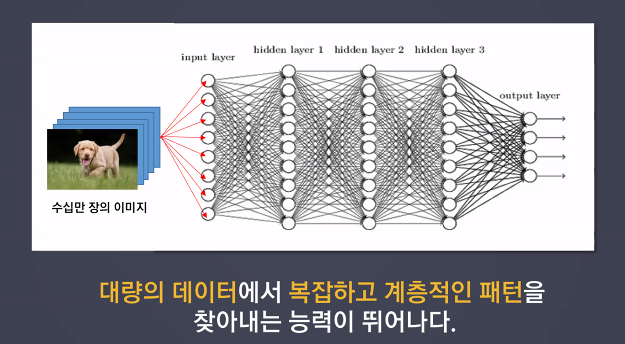
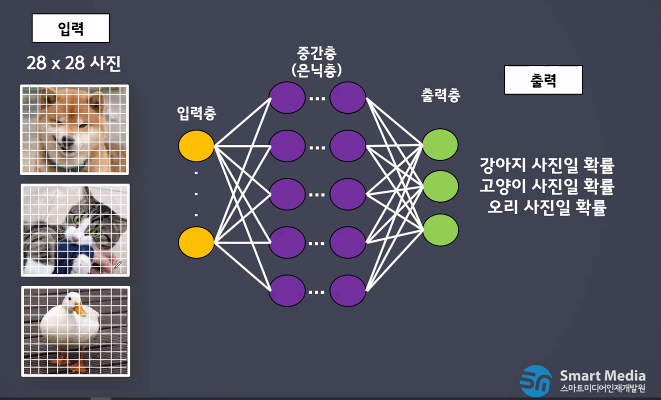
실습
- import 하기
from tensorflow.keras.datasets import mnist- tensorflow 안에 keras가 포함되어 있다.
- mnist : 손글씨 데이터를 쓸수있는 함수
- 훈련용과 테스트용 데이터 생성 후 넣기
훈련용 데이터와 평가용 데이터가 자동으로 나눠져있다.(X_train,y_train),(X_test,y_test)=mnist.load_data()- 훈련용 데이터
X_train.shape, y_train.shape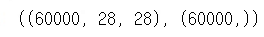
- 테스트용 데이터
X_test.shape, y_test.shape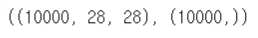
- 훈련용 데이터
- 데이터 시각화하여 보기
- import 하기
import matplotlib.pyplot as plt - 확인
plt.imshow(X_train[0]) plt.show()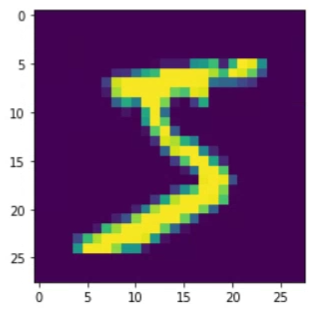
- 흑백으로 확인하고 싶을 경우
cmap 속성 추가하기plt.imshow(X_train[0], cmap = 'gray') plt.show() - 확인
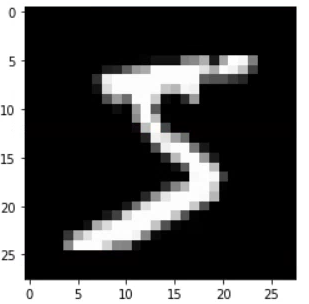
- import 하기
모델링
- import 하기
Dense : 선형모델의 집합, 병렬로 연결from tensorflow.keras.models import Sequential # 딥러닝 모델의 뼈대 from tensorflow.keras.layers import InputLayer, Dense # 입력층, 중간/출력층 - 뼈대 생성 후, 입력층에 데이터 넣기
model = Sequential() # 딥러닝 모델의 뼈대 생성 model.add(InputLayer(input_shape=(784,))) # 입력층 추가,() 안에는 데이터의 크기가 들어가야한다. model.add(Dense(units=20, activation = 'sigmoid')) #20개를 모음, 중간층 추가 model.add(Dense(units=40, activation = 'sigmoid')) #20개를 모음, 중간층 추가 model.add(Dense(units=30, activation = 'sigmoid')) #20개를 모음, 중간층 추가 model.add(Dense(units=10, activation= 'softmax')) # 출력층 10개의 확률 - 모델 학습하기
loss와 optmizer는 어떻게 학습을 할것인지 정하는 역할#1. 모델의 학습 방법 및 평가방법 설정 model.compile(loss="sparse_categorical_crossentropy", optimizer='Adam', metrics = ['accuracy']) #2. 모델학습 model.fit(X_train.reshape(60000,784),y_train,epochs = 100) #epochs : 데이터 학습 횟수
모델 예측
- 예측하기
pre = model.predict(X_test.reshape(10000,784))pre.shape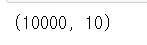
10장이 나오는 이유는 출력값으로 10을 지정해서 그렇다.pre[0]
각각 0~9번까지의 확률을 나타냄
모델 평가
-
평가하기
pre_classes = pre.argmax(axis=1) pre_classes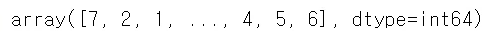
각 데이터의 결과에서 제일 높은 확률의 값을 출력함
-
정확도 평가
- sklearn 이용하기
!pip install sklearn from sklearn.metrics import accuracy_score accuracy_score(y_test,pre_classes)- model 내부 평가함수 이용하기
model.evaluate(X_test.reshape(10000,784),y_test)
모델 저장
model.save("./hand_write_digit_model.h5")
참고 사이트
-
홈페이지 들어가기
www.tensorflow.org -
API 선택하기
-
버전 선택하기
-
필요한 거 선택하기


초보 코딩