지도학습
머신러닝은 데이터 학습 과정에서 정답(레이블) 유무에 따라 지도학습과 비지도학습으로 나눌 수 있다.
지도학습은 레이블링된 값(출력값)이 어떤 형태인지에 따라 분류 또는 회귀의 방법으로 답을 예측
1. 분류(Classification)
-
레이블링된 값(출력값)이 범주형 데이터인 경우 학습한 모델은 각각의 값을 구별해내는 분류(Classification)의 역할을 수행
-
범주형 데이터 : 개, 고양이 분류 처럼 서로 완전히 구분되는 데이터
-
스펨 메일 분류, 필기체 숫자 인식 등이 이에 속함
2. 회귀(Regression)
-
레이블링된 값(출력값)이 연속형 데이터인 경우 학습한 모델은 입력값과 출력값 간의 일반적인 관계 특성을 도출하는 회귀(Regression)의 역할을 수행
-
연속형 데이터 : 값들이 어떠한 범위 내에서 자유롭게 수치형태로 존재할 수 있는 데이터
-
온도가 올라가면 아이스크림 판매량이 올라간다 처럼 온도(입력값)와 아이스크림 판매량(출력값) 간의 관계를 학습시키고 온도를 입력시키면 아이스크림 판매량을 예측
-
주가 예측, 시장규모 예측 등이 이에 속함
- 선형회귀(Linear Regression) : 임의로 분포한 데이터들을 하나의 직선으로 일반화 시킨 것
로지스틱 회귀(Logistic Regression) : S자의 굴곡진 모양의 함수. 출력값이 범주형 데이터일 경우 사용하고, 완전히 분리된 값을 구분하기 좋다는 특징
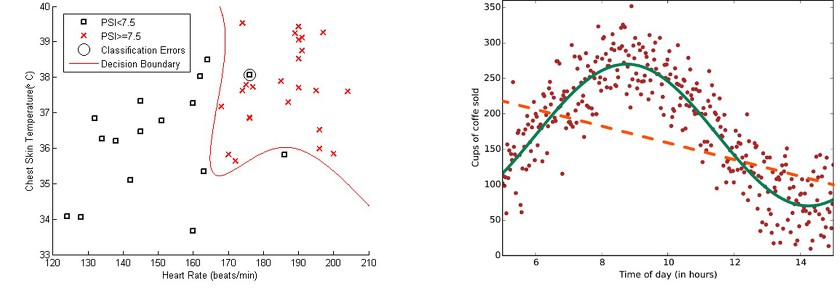
왼쪽이 분류, 오른쪽이 회귀
3. 의사결정나무(Decision Tree)
-
주어진 입력값에 대해 여러 번의 질문을 통해 답을 찾는 방법
-
여러개의 입력값을 주고 그 입력값에 해당되는 출력값을 준 뒤 여러번 학습시킨 후 다음 입력값을 줄 때 적절한 답을 주는 방법
-
많은 데이터가 존재할수록 정확하게 구별가능
-
회귀분석은 하나의 선으로 데이터를 분류하거나 일반화한다면, 의사결정나무는 여러 개의 직선을 활용
4. 서포트 벡터 머신(Support Vector Machine, SVM)
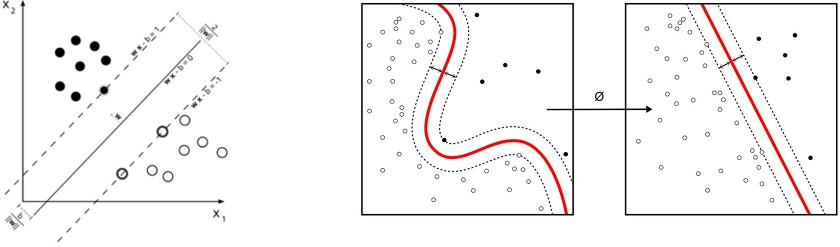
[그림출처 : https://en.wikipedia.org/wiki/Support_vector_machine]
-
2번째 그림을 보면 데이터가 직선으로 구분할 수 없는 형태로 되어있는데, 커널 함수라는 변환 함수를 통해 직선형태로 변형하여 구분할 수 있게 만듦
-
데이터의 분포가 어떻든 직선이나 곡선을 그어서 분류할 수 있기 때문에 회귀모델이나 의사결정나무모델이 학습하기 어려운 복잡한 데이터도 학습 가능
** 참고
