1. CI/CD
CI/CD가 나온 배경
-
모든 개발이 끝난 이후에 코드 품질을 관리하는 고전적 방식의 단점을 해소하기위해 나타난 개념
-
분업과 협업의 과정에서 코드의 Merge 과정은 까다롭고, 테스트하는데 큰 자원을 소비되게 된다. 이 문제를 해결하기 위해 도입
-
개발 브랜치가 일정 기간 이상 이용되면, 통합의 어려움은 커지고 충돌 해결에 들어가는 시간이 길어지고 오류 발생 위험이 커진다. 이러한 단점을 극복하고자 변동 내용의 반영 빈도를 늘리는 자동화가 등장
CI/CD는?

-
CI/CD는 애플리케이션 개발 단계를 자동화하여 애플리케이션을 보다 짧은 주기로 고객에게 제공하는 방법이다.
-
지속적인 통합, 지속적인 서비스 제공, 지속적인 배포를 가능하게 한다.
-
새로운 코드의 통합으로 인하여 개발 및 운영팀에 발생하는 문제를 해결하는 솔루션이다.
CI(Continuous Integration) 지속적 통합
-
개발을 하면서 ‘코드에 대한 통합’을 ‘지속적’으로 진행함으로써 품질을 유지하자는 것
-
개발자간의 코드 충돌을 방지하기 위한 목적
-
정기적인 빌드 및 테스트(유닛테스트 및 통합테스트)를 거쳐 공유 레포지터리에 병합되는 과정
CD(Continuous Deploy 또는 Delivery) 지속적 배포
-
애플리케이션에 적용한 변경사항이 버그 테스트를 거쳐 레포지터리에 자동으로 업로드 되는 것
-
개발자의 변경 사항을 레포지터리에서 고객이 사용 가능한 프로덕션 환경(실제 서비스를 위한 운영 서버)까지 자동으로 릴리스하는 것
-
이 레포지터리에서 애플리케이션을 실시간 프로덕션 환경으로 배포된다.
-
소프트웨어가 항상 신뢰 가능한 수준(합쳐지고 버그테스트를 통과한 상태)에서 배포될 수 있도록 지속적으로 관리하자는 개념
-
CI의 연장선으로 생각하면 된다.(CD가 되려면 항상 CI가 선행)
즉, CI 프로세스를 통해 개발중에 지속적으로 빌드와 테스트를 진행하고, 이를 통과한 코드에 대하여 테스트서버와 운영서버에 곧바로 그 내용을 배포해 반영하는 것이다.
한 번에 많이 수정하지 말고, 조금 수정하여 여러 번 배포하라!
CI/CD 지원 툴
- Hudson
- Jenkins
- Bamboo(상용)
- 그 외 다양한 툴 존재
** 참고
https://itholic.github.io/qa-cicd/
https://onlywis.tistory.com/9
https://medium.com/@hoi5088/ci-cd-%EA%B0%9C%EB%85%90-4e6a45dbcfe2
2. Scale up, Scale out

1. 스케일 업(Scale up)
- 서버의 자체 성능을 증가시키는 것
- 기존의 서버에서 더욱 고성능의 서버로 변경하는 것을 의미
- 스케일 업을 "수직 스케일"이라고 부르기도한다.
- 문제점
- 스토리지 컨트롤러(스토리지 전용 입출력 장치)의 확장성 한계의 문제
- 성능 그리고 용량 확장 제한에 다다른 경우에 새 시스템을 추가해야되는데 이때 발생하는 마이그레이션(기존의 운영환경에서 대개의 경우 좀 더 낫다고 여겨지는 다른 운영환경으로 옮겨가는 과정) 비용 등
2. 스케일 아웃(Scale out)
- 기존의 서버와 같은 사양 또는 비슷한 사양의 서버 대수를 증가시키는 방법
- 처리 능력을 향샹시키는 것
- 스케일 아웃 방식을 "수평 스케일"이라고 부르기도한다.
- 문제점
- 병렬 컴퓨팅의 어려움(설계 및 구현), 기본적으로 직렬화(단일 처리)되어야 할 부분이 존재하며, 기술적으로 문제점(대역폭, 동기화 문제)
- 코어(CPU 내부에 있는 물리적인 회로의 핵심부분)가 늘어남에 따라 마냥 성능이 증가하지는 않고, 코어 증가에 따라 대역폭은 증가해 지연이 발행할 가능성이 있다.
3. 스케일 업(Scale up)과 스케일 아웃(Scale out) 비교
| 스케일 업(Scale up) | 스케일 아웃(Scale out) | |
|---|---|---|
| 확장성 | 더 빠른 속도의 CPU로 변경하거나, 더 많은 RAM을 추가하는 등의 하드웨어 장비의 성능을 높이는 것. 수직 확장. 성능 확장에 한계가 있다. | 하나의 장비에서 처리하던 일을 여러 장비에 나눠서 처리 할 수 있도록 설계를 변경하는 것. 수평 확장. 지속적 확장이 가능 |
| 서버 비용 | 성능 증가에 따른 비용 증가폭이 크며, 일반적으로 비용 부담이 큼 | 비교적 저렴한 서버를 사용하므로 일반적으로 비용 부담이 적음 |
| 운영 비용 | 관리 편의성이나 운영 비용은 스케일업에 따라 큰 변화 없음 | 대수가 늘어날수록 관리 편의성이 떨어지며, 서버의 상면 비용을 포함한 운영 비용이 증가 |
| 장애 | 한대의 서버에 부하가 집중되므로 장애시 장애 영향도가 큼 | 읽기/쓰기가 여러대의 서버에 분산 처리됨으로 장애 시 전면 장애의 가능성이 적음 |
| 장/단점 | 고성능 Legacy 어플리케이션, 구축이 쉽고 관리 용이 / 단계적 증가가 어렵고, 근본적인 해결이 안될 수 있음 | 분산처리 시스템, Global 웹 어플리케이션, 점진적 증가 가능, 보통 스케일업보다 저렴 / 설계,구축,관리 비용 증가 |
| 주요 기술 | 고성능 CPU, Memory 확장, SSD | Sharding, Query-off Loading, Queue, In Memory Cache, NoSQL, Object Storage, Distributed Storage |
어떠한 방식이 더욱 좋다라고 하기보단, 주어진 환경에서 어떤 방식을 채택해서 더욱 실용적으로 구축하느냐가 중요
** 참고
https://m.blog.naver.com/islove8587/220548900044
https://toma0912.tistory.com/87
https://blog.naver.com/kmkim1222/220360346507
3. Array 할당메모리가 다 차서 재할당 할때 얼마만큼의 분량을 재할당 하는게 메모리 효율적인가?
-
array 배열 크기 선언시 공간을 할당한다.(C, JAVA 등)
정적 배열은 크기 선언 후 배열의 크기를 바꿀 수 없는 배열
동적 배열은 크기 선언 후 배열의 크기를 조절할 수 있는 배열 -
배열 크기를 정한 후 메모리가 꽉 차면 필요에 따라 재할당(기존에 동적으로 할당했던 메모리를 새로운 크기로 축소/확장) 해야함
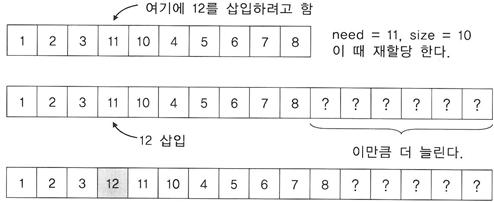
-
필요한 만큼 메모리를 재할당 하지않고 여유롭게 메모리를 재할당한다.
-
배열을 재할당할 때는 어느 정도의 여유분을 주는 것이 효율상 유리하다. 삽입은 보통 연속적으로 일어나므로 메모리가 부족해서 크기를 늘려야 한다면 조만간 메모리가 다시 부족해질 확률이 아주 높다.
-
만약 여유분을 주지않고 필요할 때마다 크기를 변경해야 한다면 매번 크기를 변경하는 함수를 호출해야 하므로 호출 할 때마다 메모리를 잡아먹는다. 호출 회수를 줄여야 한다. 그래서 이왕 재할당을 할 때 여유분을 주어 다음 번 부족한 상황을 최대한 늦추는 것이 좋다.
-
그렇다고 해서 여유분을 지나치게 크게 주면 남는 메모리가 많아져 공간 효율이 떨어진다. 필요에 따라 적당한 양을 주는 것이 좋다.
** 참고
http://tcpschool.com/c/c_array_oneDimensional
https://dbehdrhs.tistory.com/37
http://soen.kr/lecture/ccpp/cpp2/19-1-2.htm
4. 동기와 비동기의 차이를 아는가?
- 데이터를 받는 방식
1. 동기방식 (Synchronous : 동시에 일어나는)
- 동시에 일어난다는 뜻. 요청과 그 결과가 동시에 일어난다는 약속. 요청을 하면 시간이 얼마가 걸리던지 요청한 자리에서 결과가 주어져야 한다는 것
- A코드가 모두 완료되기 전까지 B코드는 실행되지 않는다.
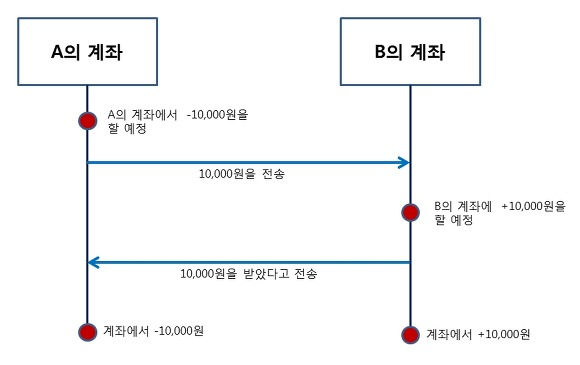
- A의 계좌는 10,000원을 뺄 생각을 하고 있다.
- A의 계좌가 B의 계좌에 10,000원을 송금한다.
- B의 계좌는 10,000원을 받았다는 걸 인지하고, A의 계좌에 10,000원을 받았다고 전송한다.
- A, B 계좌 각 각 차감과 증가가 동시에 발생하였다.
- A계좌와 B계좌는 서로 요청과 응답(1~3과정)을 확인한 후 같은 일을 동시에 진행했다(4번과정)
계좌이체같은 작업은 동기방식으로 처리해야함
-
동기식 처리 모델((Synchronous processing model)은 직렬적으로 태스크(task) 수행한다.
즉, 태스크는 순차적으로 실행되며 어떤 작업이 수행 중이면 다음 작업은 대기하게 된다. -
예를 들어 서버에서 데이터를 가져와서 화면에 표시하는 작업을 수행할 때, 서버에 데이터를 요청하고 데이터가 응답될 때까지 이후 태스크들은 블로킹(bloking, 작업중단)된다.
2 비동기 방식 (Asynchronous : 동시에 일어나지 않는)
- 동시에 일어나지 않는다는 뜻. 요청과 결과가 동시에 일어나지 않을거라는 약속. 요청한 그 자리에서 결과가 주어지지 않는다는 것
- A코드의 완료 시점과 상관없이 B코드가 실행된다.
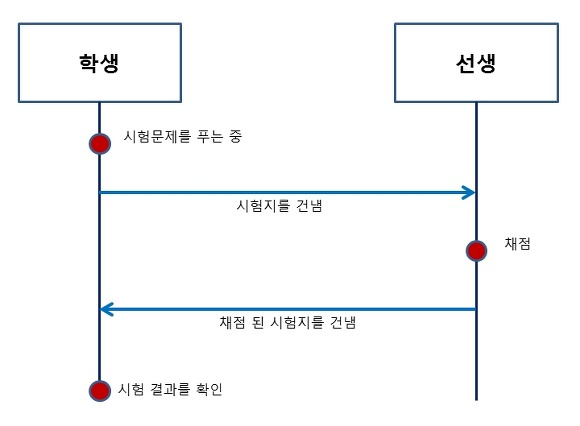
- 학생이 시험문제를 푼다.
- 시험문제를 모두 푼 학생은 선생님에게 문제를 전송한다.
- 선생님은 학생의 시험지를 채점한다.
- 채점이 다 된 시험지를 학생에게 전송한다.
- 학생은 선생님이 전송한 시험지를 받아 결과를 확인한다.
-
학생과 선생은 시험지라는 연결고리가 있지만 시험지에 행하는 행위(목적)은 서로 다릅니다. 학생은 시험지를 푸는 역할을 하고 선생은 시험지를 채점하는 역할을 하였습니다. 서로의 행위(목적)가 다르기때문에 둘의 작업 처리 시간은 일치하지 않고, 일치하지 않아도 된다.
-
비동기식 처리 모델(Asynchronous processing model 또는 Non-Blocking processing model)은한다.
즉, 태스크가 종료되지 않은 상태라 하더라도 대기하지 않고 다음 태스크를 실행한다.
- 예를 들어 서버에서 데이터를 가져와서 화면에 표시하는 태스크를 수행할 때, 서버에 데이터를 요청한 이후 서버로부터 데이터가 응답될 때까지 대기하지 않고(Non-Blocking) 즉시 다음 태스크를 수행한다.
동기, 비동기
-
동기와 비동기는 어떤 작업 혹은 그와 연관된 작업을 처리하고자 하는 시각의 차이. 동기는 추구하는 같은 행위(목적)가 동시에 이루어지며, 비동기는 추구하는 행위(목적)가 다를 수도 있고, 동시에 이루어지지도 않습니다.
-
동기 = 주문한 후에 커피가 나올 때 까지 이 자리에서 기다려라 뒷사람들은 앞사람의 커피가 나올때까지 기다려야 한다.
비동기 = 주문한 후에 다른곳에 가있다가 진동벨이 울리면 커피를 가지러와라
** 참고
https://private.tistory.com/24
https://jieun0113.tistory.com/73
https://webclub.tistory.com/605
https://www.youtube.com/watch?v=c4R_7XGlrBU
5. 비동기를 왜쓰는지 알고있나?
-
동기방식은 설계가 매우 간단하고 직관적이지만 결과가 주어질 때까지 아무것도 못하고 대기해야 하는 단점이 있고,
비동기방식은 동기보다 복잡하지만 결과가 주어지는데 시간이 걸리더라도 그 시간 동안 다른 작업을 할 수 있으므로 자원을 효율적으로 사용할 수 있는 장점이 있다. -
선행작업의 완료되지 않아도 후행 작업이 수행 될 수 있다.
-
만약에 데이터를 서버로 부터 받아오는 앱을 만든다 하면 서버로 부터 데이터를 받아와서 해당 데이터를 뿌려줘야 하므로 맨 처음에 서버로 부터 데이터를 받아오는 코드가 실행되어야 할 것.
이를 비동기로 처리하지 않고 동기로 구성한다면 데이터를 받아올때까지 기다린 다음에 앱이 실행 될 것이고 서버에서 받아오는 데이터의 양이 늘어날 수록 앱의 실행속도는 느려지게 될 것이다.
데이터를 가져오기까지 앱을 실행하지 못하는 것 -
크롬 브라우저를 실행시키는 시간이 약 10분이 소모된다고 생각해보면. 크롬 브라우저가 오픈되는 약 10분이라는 시간 동안 저희는 컴퓨터의 다른 프로그램들을 동작시키지 못하며 크롬 브라우저가 켜지는 그 순간만을 계속 기다려야한다는 것. 이 시간이 10분이든 100분이든 관계없이 한 개의 데이터 요청에 대한 서버의 응답이 이루어질 때까지 계속 대기해야한다.
6. Tree(트리)에 대해 설명해주세요.
-
데이터를 저장하는데 나무 구조와 비슷하게 데이터를 저장한다.
-
비선형구조(선형구조라는것은 리스트와 튜플 같이 a다음에 b가 있고, b 다음에 c가 나오는 자료를 구성하는 원소들을 순차적으로 나열시킨 형태 비선형구조는 일렬로 나열하기 힘들고 자료의 순서가 불규칙해서 연결 관계가 복잡한 구조)
-
데이터 요소들의 단순한 나열이 아닌 부모-자식 관계의 계층적 구조로 표현
-
노드들의 집합. 노드(node)들과 노드들을 연결하는 간선(edge)로 구성됨
- 노드(node)는 쉽게 말해서 데이터를 가지고 있는 것을 말하고, 노드는 값이나 조건을 포함할 수 있고, 다른 독립된 자료 구조의 역할을 하기도 한다.
- 간선(edge)은 트리를 구성하기 위해 노드와 노드를 연결하는 선
- 트리구조의 특징
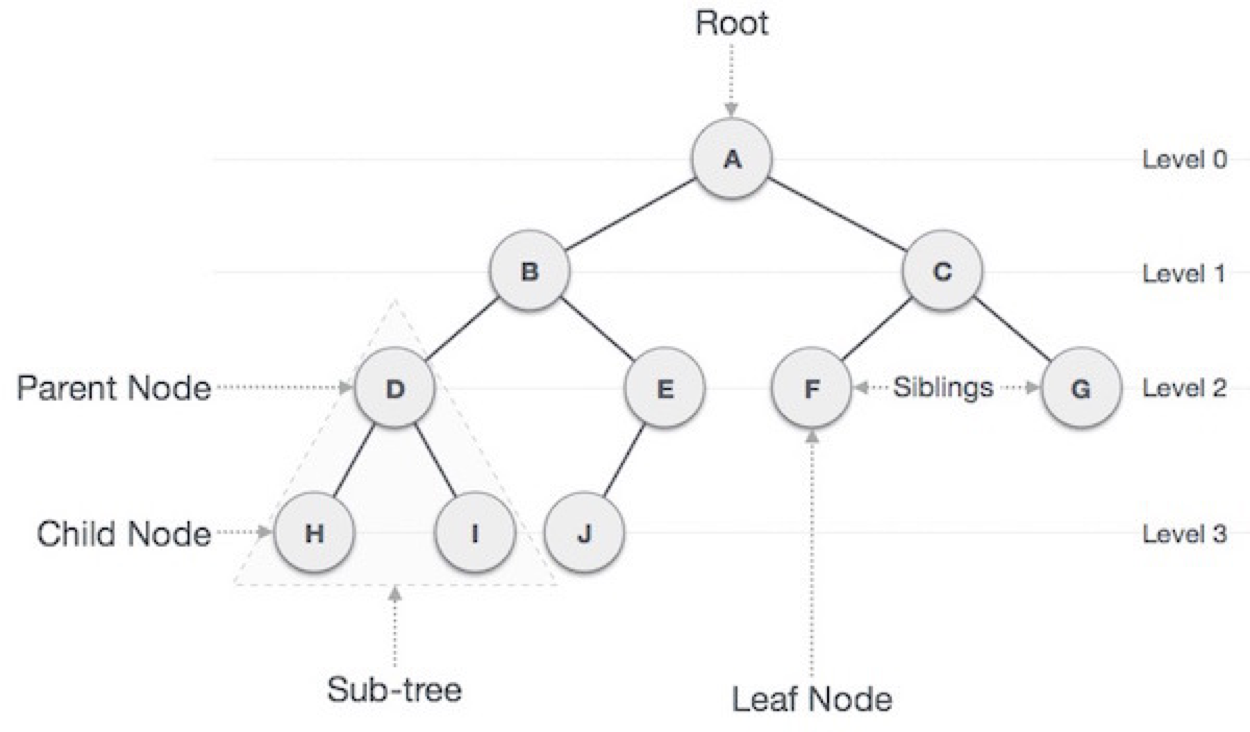
- root(가장 상위의 노드)로 부모를 가지지 않고, 하나만 존재
- root를 제외한 모든 노드는 하나의 부모를 가져야 한다.
- 노드는 여러개의 자식을 가질 수 있다.
- 노드들은 특정 순서로 나열될 수도 있고, 아닐 수도 있다.
- 그래프의 한 종류이며 사이클(순환과정)이 없다.
6 . 트리의 속성 중 가장 중요한 것이 루트 노드를 제외한 모든 노드는 단 하나의 부모노드만을 가진다는 것
-
루트 용어
-
루트 노드(root node): 부모가 없는 노드, 트리는 하나의 루트 노드만을 가진다.
-
단말 노드(leaf node): 자식이 없는 노드, ‘말단 노드’ 또는 ‘잎 노드’라고도 부른다.
-
내부(internal) 노드: 자식이 있는 노드, 단말 노드와 반대되는 개념
-
간선(edge): 노드를 연결하는 선 (link, branch 라고도 부름)
-
형제(sibling): 같은 부모를 가지는 노드
-
노드의 크기(size): 자신을 포함한 모든 자손 노드의 개수
-
노드의 깊이(depth): 루트에서 어떤 노드에 도달하기 위해 거쳐야 하는 간선의 수
-
노드의 레벨(level): 트리의 특정 깊이를 가지는 노드의 집합
-
노드의 차수(degree): 하위 트리 개수 / 간선 수 (degree) = 각 노드가 지닌 가지의 수
-
트리의 차수(degree of tree): 트리의 최대 차수
-
트리의 높이(height): 루트 노드에서 가장 깊숙히 있는 노드의 깊이
-
-
루트 예시
windows의 디렉토리 구조
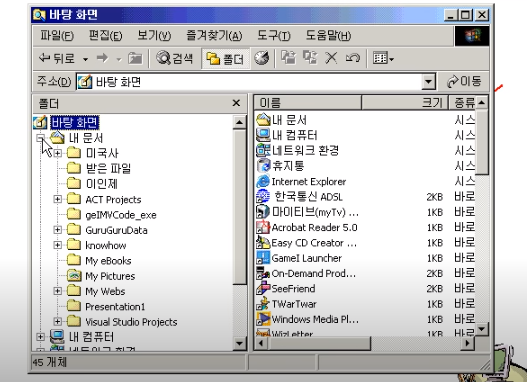
-
참고
https://gmlwjd9405.github.io/2018/08/12/data-structure-tree.html
7. Binary Tree(이진 트리)에 대해 설명해주세요.
-
트리의 한 종류 가장 간단한 형태
-
모든 내부(internal) 노드(자식이 있는 노드)가 두개 이하의 자식을 갖는 트리. 자식노드를 두개 초과로 가질수없다.
-
left child와 right child 두 개의 자식을 가질 수 있다.
-
가장 쓰임새가 많은 트리
-
이진트리 종류
-
편향 이진 트리(skewed binary tree)
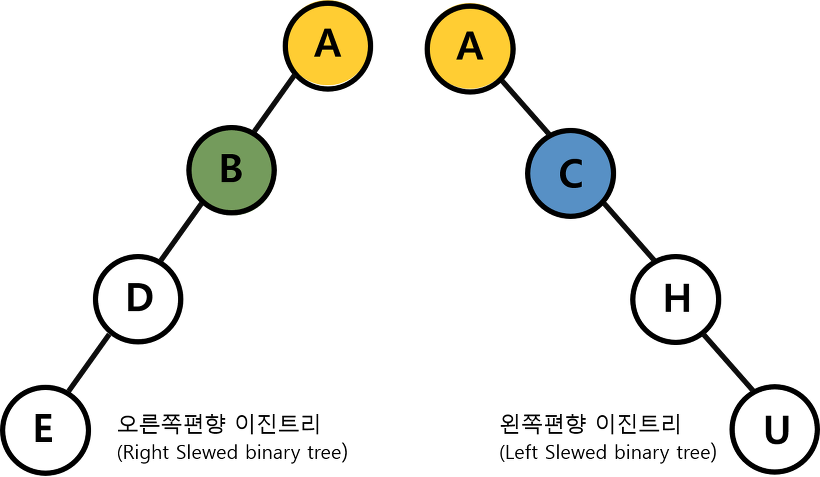
-
포화 이진 트리(full binary tree)
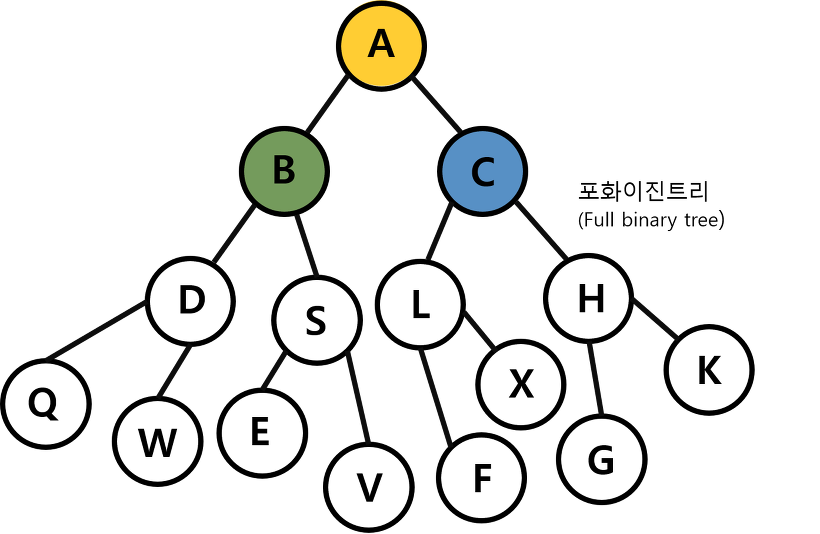
마지막 레벨을 제외한 모든 레벨에 노드가 꽉 차있는 것.
Leaf 노드를 제외한 모든 노드의 차수가 두개로 이뤄진 경우 -
완전 이진 트리(complete binary tree)
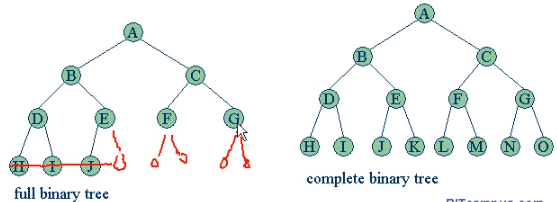
트리의 모든 높이에서 노드가 꽉 차 있는 이진 트리. 마지막 레벨을 제외하고 모든 레벨이 꽉 채워져있다.
- 이진트리의 용도
- parse tree : 수식 계산에 사용
- heap : 정렬에 사용
- binary search tree : 검색에 사용
이진트리의 장점중 하나는 룩업연산(lookup, 트리에 있는 특정 노드의 위치를 알아내는 연산)을 빠르고 간단하게 처리할 수 있다는 장점

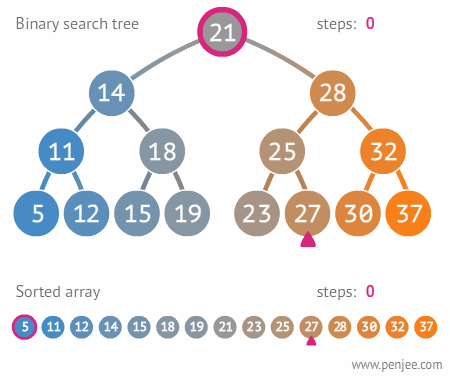
** 참고
https://gmlwjd9405.github.io/2018/08/12/data-structure-tree.html
http://www.secmem.org/blog/2019/05/09/%ED%8A%B8%EB%A6%AC%EC%9D%98-%EC%A2%85%EB%A5%98%EC%99%80-%EC%9D%B4%ED%95%B4/
https://www.notion.so/Data-Structure-4-tree-350238e684c54add82a793f5e4f24c29
https://www.youtube.com/watch?v=PkuYzOe7LhM
