
ZeroMQ란?
ZeroMQ는 분산 혹은 병렬 처리가 필요한 프로그램에서 사용하는 고성능 비동기 메시징 라이브러리이다. ZeroMQ는 메시지 큐를 제공하지만, 메시지 지향 미들웨어와 다르게 메시지 브로커 없이도 동작한다.
🧐 메시지 지향 미들웨어 (Message-Oriented Middleware, MOM) 란?
다양한 시스템과 애플리케이션 간에 메시지를 주고받게 해주는 소프트웨어. 비동기 방식으로 메시지를 전달한다.
ZeroMQ는 pub/sub, request/reply, client/server 등 기본적인 메시징 패턴들을 제공한다. 이때 TCP, in-process, inter-process, multicast, WebSocket 등 다양한 전송 방식을 활용할 수 있다.
Messaging Patterns
Request / Reply
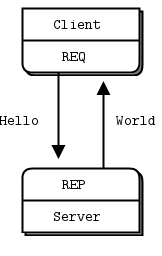
REQ-REP 패턴은 소켓 쌍이 서로 동기화된 상태로 작동한다. REQ 소켓이 요청을 보내면, 해당 요청에 대한 응답을 받기 전까지 다음 요청을 보낼 수 없다. 예측 가능성과 신뢰성은 높은 대신, 유연성이 제한된다.
ZMQ의 경우 고수준 라이브러리이기 때문에 서버가 꺼지더라도 자체적으로 연결 상태를 관리하고, 연결이 복구된 경우 자동으로 재연결을 시도한다.
해당 패턴의 사용 예시로 Remote Procedure Call(RPC), Service-Oriented Architecture(SOA) 등이 있다.
Publish / Subscribe
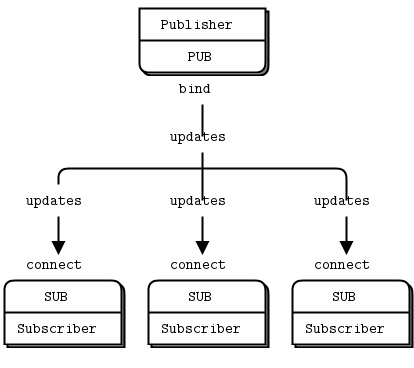
PUB-SUB 패턴은 메시지를 발행하면, 다수의 구독자가 메시지를 수신하는 패턴이다. 비동기 방식으로 사용되며, 듣는 쪽이 없어도 메시지 발행이 가능하기 때문에 구독자가 오프라인 상태일 때도 정상적으로 작동한다. 또한 구독자는 원하는 메시지만 수신 가능하도록 설정할 수 있다.
발행 구독 패턴은 뉴스 피드, 실시간 업데이트, 이벤트 알림 시스템 등에 사용된다.
Push / Pull
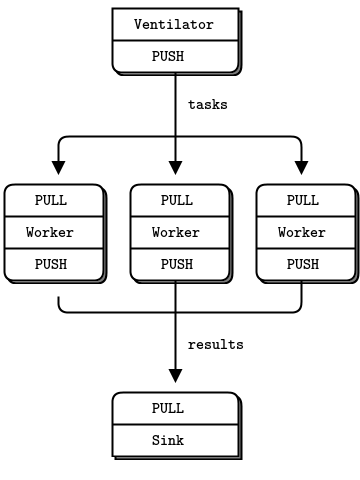
PUSH-PULL 패턴은 작업이나 메시지를 분산시켜 병렬 처리 효과를 얻을 수 있다. 이때 자동으로 작업을 공평하게 분배하기 때문에, 로드 밸런싱 효과를 볼 수 있다. 크게 Producer, Consumers, Result Collector 3가지 역할이 존재한다. 공식 문서에서는 각각 Ventilator, Worker, Sink로 소개하고 있다. 메시지는 항상 PUSH에서 PULL로 이동한다.
배치 작업 처리, 대규모 데이터 처리 작업 등에 사용될 수 있다.
병렬 처리 시도하기
위 여러 패턴에 대한 내용은 공식 문서의 Guide에서 매우 상세한 설명과 코드로 제공한다. 이제부터는 병렬 처리를 시도해보기 위해 Push/Pull 패턴을 활용해보자. 우선 공식 문서에서 제공하는 코드를 실행해보았을 때는, 아래와 같이 소개하는 시간과 비슷한 결과를 얻었다.
- 1 worker: total elapsed time: 5034 msecs.
- 2 workers: total elapsed time: 2421 msecs.
- 4 workers: total elapsed time: 1018 msecs.
중간 worker 역할을 하는 프로세스를 늘리면, 그만큼 작업에 수행하는 시간이 줄어든다. 그렇다면 랜덤 로그 데이터를 생성해서 간단한 병렬 처리를 시도해보자.
log 데이터 처리하기
최근에는 log 데이터도 json으로 받아오는 경우가 많다고 한다. 이를 고려하여 간단하게 랜덤한 로그 데이터를 만드는 코드를 작성했다.
import time
import random
import datetime
import json
def generate_log():
log_data = {
"timestamp": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"ip": f"{random.randint(1, 255)}.{random.randint(1, 255)}.{random.randint(1, 255)}.{random.randint(1, 255)}",
"user_id": random.randint(1, 10000),
"user_info": {
"gender": random.choice(["male", "female"]),
"age": random.randint(20, 60),
},
"url": random.choice(["/api/buy/items", "/api/cart/items", "/api/signup", "/api/login"]),
"param": random.choice(["", "cake"]),
"response_code": random.choice([200, 404, 500])
}
return json.dumps(log_data)아래부터는 순서대로 Producer, Consumers, Result Collector 역할을 하는 코드들이다.
먼저 task를 생성하는 역할이다. 이전에 만들었던 로그 데이터 생성 함수를 활용해 100만 개의 로그를 만든다. 로그를 생성하는 시간을 고려하여, 생성을 먼저 끝마친 후 사용자 입력이 오면 작업을 시작한다. 작업이 시작되면 시간 비용을 측정하기 위해 sink(collector)에게 메세지를 보낸 후, worker(consumers)들에게 작업을 전달한다.
# task ventilator
from log_simulator import generate_log
import zmq
import time
context = zmq.Context()
sender = context.socket(zmq.PUSH)
sender.bind("tcp://*:5557")
sink = context.socket(zmq.PUSH)
sink.connect("tcp://localhost:5558")
logs = []
for _ in range(1000000):
logs.append(generate_log())
print("Press Enter when the workers are ready: ")
_ = input()
print("Sending tasks to workers...")
sink.send(b'0')
for i in range(1000000):
sender.send_string(logs[i])
print("All tasks have been sent.")
time.sleep(1)
다음으로 실질적으로 작업을 수행하게 되는 worker이다. log 데이터를 파싱해서 응답 코드가 200이면서, 아이템을 구매하는 url일 경우 sink에게 해당 정보를 전달한다. 어떤 목적으로 데이터를 분석하느냐에 따라 데이터 처리는 달라질 수 있다.
# task worker
import zmq
import json
context = zmq.Context()
receiver = context.socket(zmq.PULL)
receiver.connect("tcp://localhost:5557")
sender = context.socket(zmq.PUSH)
sender.connect("tcp://localhost:5558")
while True:
log_data = receiver.recv()
log_parsing_data = json.loads(log_data)
if log_parsing_data["response_code"] == 200:
event = log_parsing_data["url"].split("/")[2]
if log_parsing_data["param"] and (event == "buy" or event == "cart"):
sender.send_string(f"{event}")
else:
sender.send_string(f"")
else:
sender.send_string(f"")마지막으로 작업 결과를 수집하는 역할이다. worker에게 buy라는 메시지가 올 경우 해당 정보를 저장했다가 마지막에 출력한다.
# task sink
import time
import zmq
context = zmq.Context()
receiver = context.socket(zmq.PULL)
receiver.bind("tcp://*:5558")
s = receiver.recv()
start_time = time.time()
buy_cnt = 0
for _ in range(1000000):
s = receiver.recv().decode('utf-8')
if s == "buy":
buy_cnt += 1
end_time = time.time()
print()
print(f"Total time: {(end_time - start_time) * 1000} msec")
print(f"Buy count: {buy_cnt}")수행 결과
결과는 어떻게 됐을까? 아쉽게도 basic 코드와 다른, 예상치 못한 결과를 얻었다. worker가 1개인 경우 10000~12000 msec의 결과를 얻었고, worker가 2개 이상인 경우 7000~8000 msec의 결과를 얻었다. worker가 2개인 경우와 4개인 경우의 차이가 거의 없었다. 오히려 2개인 경우가 더 빠를 때도 있었다.
이유를 찾기 위해 오랜만에 작업 관리자를 열었다.
| worker 1 | worker 2 | worker 4 |
|---|---|---|
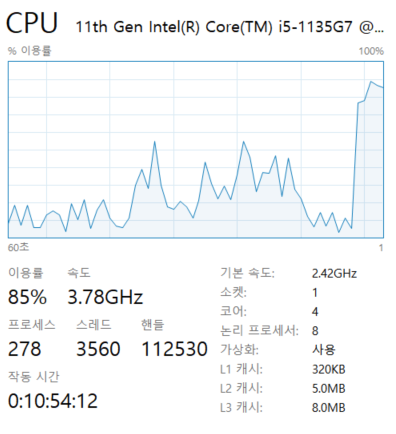 | 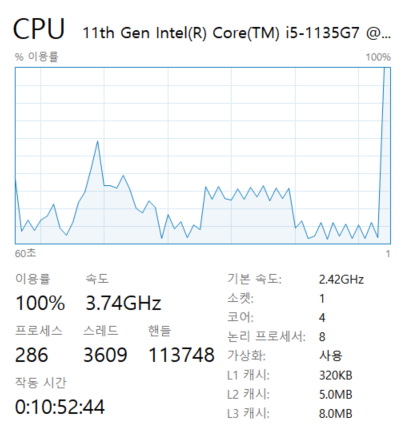 | 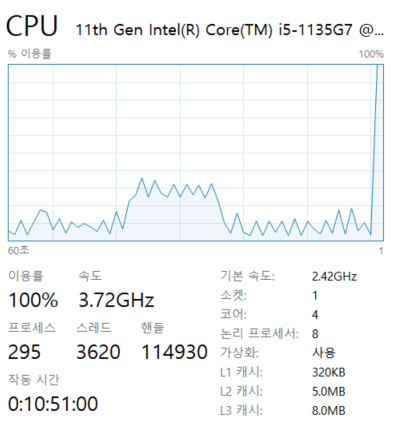 |
문제는 하나의 자원에서 병렬 처리를 시도했기 때문으로 보인다. CPU 사용률을 보면, worker가 2개이든, 4개이든 100퍼센트로 사용하고 있다. 다른 자원을 가진 노드로 worker를 구성한 게 아니라, 하나의 자원 내에 프로세스로 띄었기 때문에 결국은 자원을 공유하게 된다. 2개 이상부터는 CPU 자원을 모두 사용하기 때문에, worker를 늘려봤자 처리 속도가 빨라질 수가 없다.
ZeroMQ의 장점을 온전히 활용하기 위해서는 각각의 노드, 즉 worker가 서로 다른 컴퓨팅 자원을 사용할 수 있어야 한다. 성능에 대한 이점도 있지만, 특정 worker가 죽더라도 다른 worker들은 영향을 받지 않기 때문에 전체적인 시스템 관점에서 안정성을 유지할 수 있기 때문이다.
Reference
https://zeromq.org/get-started/
https://zguide.zeromq.org/docs/chapter1/
