84일차 시작.... (가설검정)
'p-value가 5% 수준에서 유의하다'는 의미1종 오류란?검정 통계량 종류검정 통계량이란?귀무 / 대립 가설 설정 연습귀무 / 대립 가설 특징신뢰 구간이란?신뢰 수준이란?유의 수준 (α)이란?유의 확률 (p-value)이란?척도란?척도에 따른 데이터 분석방법통계분석 Map통계적 가설검정이란?통계적 추정의 종류통계적 추정이란?
[교육] Python Analysis
목록 보기
8/15

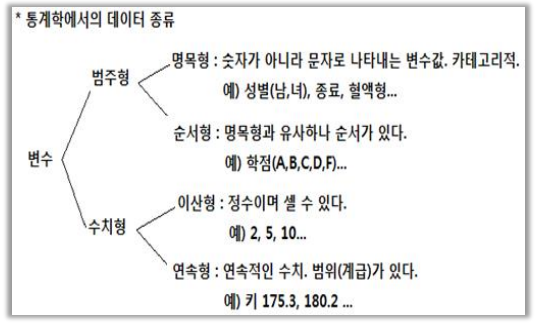
📊 척도(Scale)
📌 척도란?
- 척도
- 자료(데이터)가 수집될 때 관찰된 자료의 특징에 따라 하나의 형태의 값을 할당하기 위해 사용되는 측정 수준
- 척도에 따른 분류
- 범주형(정성적) : 수량화 불가
- 수치형(정량적) : 수량화 가능
- 명목척도(nominal scale)
[ 명목형 ]
- 명칭만 존재하는 변수값
예) 성별, 혈액형, ....
- 서열척도(ordinal scale)
[ 순서형 ]
- 명칭, 순서가 존재하는 변수값
예) 학점, ....
- 등간척도(간격척도, interval scale)
[ 이산형 ]
- 명칭, 순서, 간격이 존재하는 변수값
예) 정수, 심험 점수, ....
- 비율척도(ratio scale)
[ 연속형 ]
- 명칭, 순서, 간격, 절대적 영점이 존재하는 변수값
예) 온도, 키, ....
📌 척도에 따른 데이터 분석방법
- 데이터 분석방법 종류
- 카이제곱 검정 예)
독립변수 : 부모학력 (순서형-[범주형])
종속변수 : 자녀진학여부 (명목형-[범주형])
- T 검정 예)
독립변수 : A1반, A2반 (명목형-[범주형])
종속변수 : 성적 평균 (연속형)

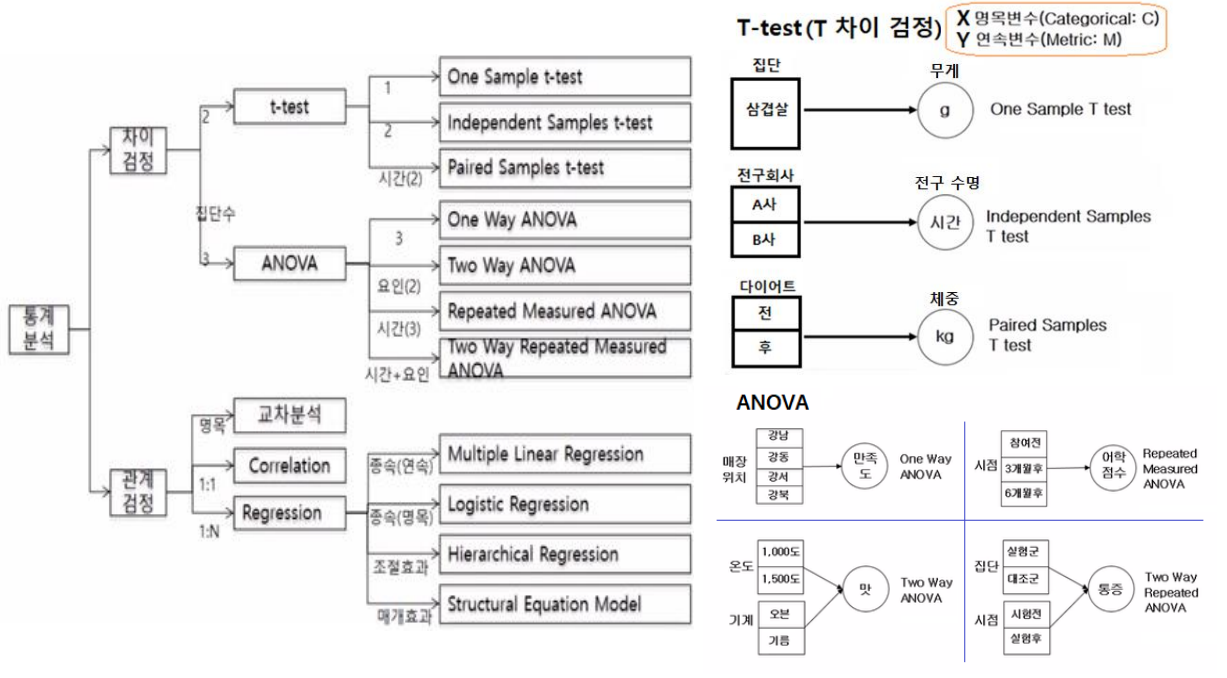
📊 통계분석 Map
📌 통계분석 Map
📊 통계적 추정
📌 통계적 추정이란?
- 정의
- 모집단(전체집단)의 특징을 파악하고자 할 때, 비용과 시간을 절약하고자 일부 표본집단을 추출해 표본집단의 표본통계량을 파악함으로써 모집단의 모수(평균, 표준편차 등)를 추리하는 것
- 정리
1) 모집단의 특징 파악을 원함
2) 표본집단을 추출
3) 검정을 통해 표본집단의 표본통계량을 파악
4) 모집단의 모수가 "이러할 것이다" 라고 모수 추리
📌 통계적 추정의 종류
- 점추정
- 표본의 통계량이 정확하게 하나의 점으로 떨어지도록 표현하는 것
예) 100명의 여자가 있는 표본집단의 평균 키는 160cm 이다.
- 구간 추정
- 표본의 통계량이 점추정치를 기준하여 특정 구간으로 표현하는 것
예) 100명의 여자가 있는 표본집단의 평균 키는 157cm ~ 163cm 이다.
- 특성
- 점추정 : 정확하게 표본통계량 값에 맞추기가 어려워 신뢰도가 낮음
- 구간추정 : 구간 안에 드는 확률은 점추정보다 높으므로 상대적으로 신뢰도가 높음
- 구간 추정의 문제점
[ 구간을 너무 넓게 가지면 오히려 신뢰성이 떨어질 수 있다. ]
📊 신뢰구간 & 신뢰수준
📌 신뢰 구간이란?
- 정의
- 구간 추정을 할 때, 해당 표본통계량의 신뢰도를 해치지 않는 구간을 만든 것
[ 즉, 구간 추정에서 신뢰할 수 있는 구간을 만드는 것이다. ]
- 정리
1) 전체 구간 확률이 1 (100%)라고 할 때,
2) 모수가 틀릴 확률을 α 라고 할 때,
3) 모수가 맞을 확률은 1-α 이다.
4) 1-α 를 나타내는 구간이 신뢰구간이다.

📌 신뢰 수준이란?
- 정의
- 신뢰구간을 정하는 확률을 의미한다.
[ 일반적으로 신뢰수준은 90%, 95%, 99%의 확률 사용 ]
- 다른 용어
- 채택역 : 1-α
📊 가설 검정
📌 통계적 가설검정이란?
- 용어 설명
- 귀무 가설(H0) : 원래부터 사용해오던 현재의 가설
- 대립 가설(H1) : 귀무가설과 완전 대립하는 새로운 가설
- 정의
- 기존에 사용하던 귀무가설에 대립하는 [ 대립가설을 통해 귀무가설이 틀렸음을 증명하는 것 ]
📌 귀무 / 대립 가설 특징
- 특징
- 귀무가설 : 일반적으로 보수적인 내용을 나타낸다.
ex) 차이 없음, 같다, ....- 대립가설 : 일반적으로 진보적인 내용을 나타낸다.
ex) 차이 있음, 다르다, ....
📌 귀무 / 대립 가설 설정 연습
- 연습1)
개와 고양이의 평균수명을 조사하였다. 두 집단의 평균수명이 차이가 있는지를 파악하기 위해 가설검정을 하려 한다. 귀무가설과 대립가설을 설정하라.- 귀무가설 : 평균 수명 차이는 5~7 년 차이가 난다.
- 대립가설 : 평균 수명 차이는 5~7 년 차이가 나지 않는다.
- 연습2)
새우깡 과자를 생산하는 기계1과 기계2가 있다. 기계1에서 생산한 제품의 분산이 큰 것으로 알려져 있다. 과연 그런지 검정하려고 하는데, 여기에 적당한 귀무가설과 대립가설을 설정하라.- 귀무가설 : 기계1에서 생산한 제품의 분산이 크다.
- 대립가설 : 기계1에서 생산한 제품의 분산이 크지 않다.
- 연습3)
A제품과 B제품이 있는데, A제품의 품질불량에 대한 항의전화가 많이 온다고 한다. 이런 이유로 A제품의 불량률이 B제품의 불량률보다 더 클 것이라는 얘기가 나오고 있다. 실제로 그런지를 알아 보기 위해 가설검정을 하려 할 때, 귀무가설과 대립가설을 설정하라.- 귀무가설 : A제품의 불량률이 B제품의 불량률보다 더 크다.
- 대립가설 : A제품의 불량률이 B제품의 불량률보다 더 크지 않다.
📊 1종 오류 & 유의수준 & 유의확률
📌 1종 오류란?
- 정의
- 모수가 같은데 잘못 판단하여 다르다고 선언하여 귀무가설을 기각하는 것이다.
[ 귀무가설이 맞았는데 틀렸다고 기각하는 것 ]
📌 유의 수준 (α)이란?
- 정의
[ 1종 오류를 범할 정해진 확률 ]
- 유의수준보다 작거나 큰 개념이 아니다.
- 유의수준 안에 들거나 벗어난다는 개념이다.
예) 즉, 유의수준 5% 안에 들면 1종 오류를 범한다. (귀무가설 기각)
- 다른 용어
- 기각역 : α
📌 유의 확률 (p-value)이란?
- 정의
- 귀무가설을 기각할 최소한의 확률값
- 검정을 통해서 나오는 확률값이다.
예) 유의수준 5%일 때, 유의확률(p-value)가 0.01이면 귀무가설 기각
- 정리
p-value < 0.05(유의수준) : 1종오류를 범할 확률에 속함 → 귀무가설 기각
p-value > 0.05(유의수준) : 1종오류를 범할 확률에 벗어남 → 귀무가설 채택
📌 'p-value가 5% 수준에서 유의하다'는 의미
- 의미 파악
1) p-value가 0.05보다 작다.
2) p-value < 0.05
3) 두 집단의 모수가 유의미한 차이를 보인다(대립가설)는 의미
4) 귀무가설 기각
📊 검정 통계량
📌 검정 통계량이란?
- 정의
- 가설검정에서 귀무가설과 대립가설 중 어느 가설이 맞는 지를 판정하기 위해 사용하는 확률값이다.
- 비용, 시간적 측면에서 모수를 사용할 수 없기 때문이다.
- 표본통계량 == 검정통계량
- 정리
[ 확률분포를 사용해 귀무가설의 기각 여부를 선택하는데 사용하는 확률값 ]
[ p-value와 동일한 역할 ]

📌 검정 통계량 종류
- 종류
- x제곱-value : 카이제곱 검정(교차검정)을 통해 도출된 확률값
- t-value : t-검정(평균 차이 검정)을 통해 도출된 확률값
- f-value : ANOVA 검정(분산 분석 검정)을 통해 도출된 확률값

데이터 사이언티스트를 목표로 하는 개발자