파이썬을 사용하여 웹 크롤링을 사용하기 위해 대부분 BeautifulSoup와 Selenium을 사용한다.
BeautifulSoup
HTML 및 XML 문서를 구문 분석하기위한 Python 패키지이다. HTML에서 데이터를 추출하는 데 사용할 수있는 구문 분석 된 페이지에 대한 구문 분석 트리를 만들며, 웹 스크래핑에 유용하다.
Selenium
BeautifulSoup만으로는 동적으로 생성된 정보는 가져올 수 없다.
때문에 자바스크립트가 동적으로 만든 데이터를 크롤링 하기 위함과 사이트의 다양한 HTML 요소에 클릭
키보드 입력 등 이벤트를 주어 업무 자동화 하기 위해 사용한다.
위 두가지 기술을 사용하기 위해서는 pip를 사용한다.
pip install bs4
pip install selenium위의 명령어를 CMD에 입력하여 설치를 진행한다.
추가적으로 알아두어야 할 점은 Selenium을 사용하기 위해서는 Chromedriver를 설치하여 같은 프로젝트 폴더에 두면 편리하게 사용할 수 있다.
Chromedriver를 설치할 수 있는 경로
https://sites.google.com/chromium.org/driver/downloads?authuser=0
최신 버전을 깔아줘야 현재 최신 크롬 프로그램을 사용할 수 있다.
크롤링 연습 페이지는 한국 관광공사 대한민국 구석구석 페이지를 크롤링 할 것이다.
https://korean.visitkorea.or.kr/main/main.do#home
# https://sites.google.com/chromium.org/driver/downloads?authuser=0 셀레니움 다운로드
# 한국 관광 공사 사이트 : https://korean.visitkorea.or.kr/main/main.do#home
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
import time #페이지가 열려야 할 수 있기 때문에 time으로 대기를 시킨다.
query_txt = input("크롤링할 키워드는 무엇입니까 : ")
# Step 1. 크롬 드라이버를 사용해서 웹 브라우저를 실행
#path = "./chromedriver.exe"
driver = webdriver.Chrome() #최근은 경로를 알아서 찾아준다.
driver.get("https://korean.visitkorea.or.kr/main/main.do#home")
driver.maximize_window() #창 크기 최대화
time.sleep(2) # 창이 모두 열릴 때 까지 2초 기다린다.
element = driver.find_element(By.ID, "inp_search") #click을 할 경우는 뒤에 .click() 을 넣어준다.
element.send_keys(query_txt) #검색어를 입력받은 내용들 send_keys => 이 글자 타이핑하라는 명령
driver.find_element(By.LINK_TEXT, "검색").click() # find_element_by_link_text 특정 글씨를 누를 때나 페이지를 찾을 때 사용현재 코드는 검색창에 특정 키워드를 삽입하여 검색을 하는 과정까지의 코드이다.
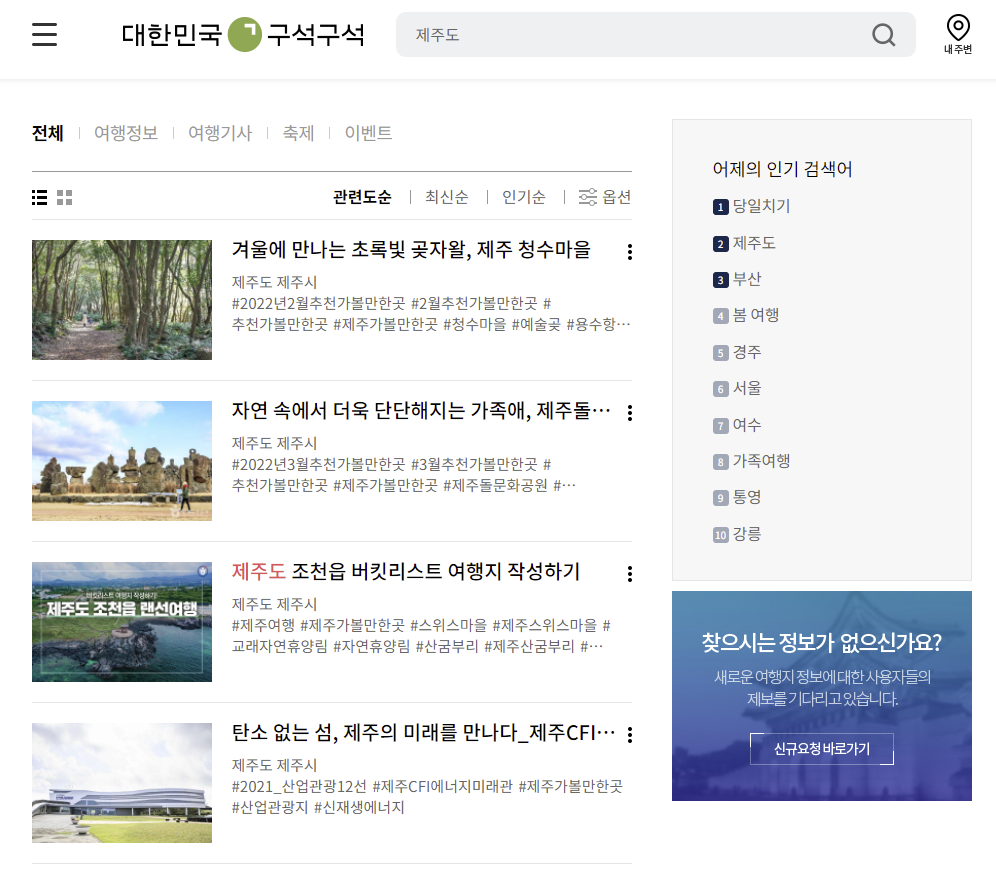
제주도까지 검색을 하면 위와 같은 화면이 보여진다. 이것을 BeautifulSoup를 통해서 HTML 파싱을 통해 분석을 부탁한다.
time.sleep(1)
html = driver.page_source # 화면에 떠있는 HTML 전체 코드를 불러온다.
soup = BeautifulSoup(html, 'html.parser')
blog_list = soup.find('ul', class_='list_thumType type1')
for i in blog_list:
print(i.text.strip())
print("\n")find 함수를 통하여 특정 클래스의 리스트를 추출하여 변수에 저장시킨다.
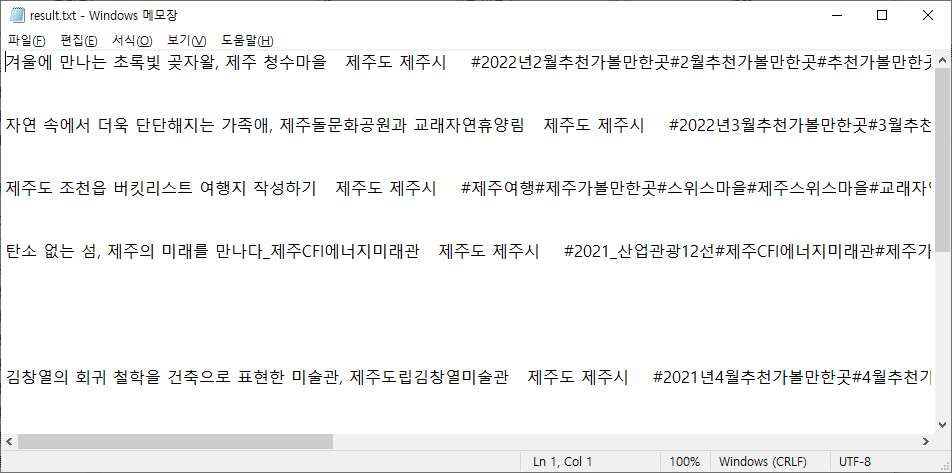
겨울에 만나는 초록빛 곶자왈, 제주 청수마을 제주도 제주시 #2022년2월추천가볼만한곳#2월추천가볼만한곳#추천가볼만한곳#제주가볼만한곳#청수마을#예술곶#용수항#성김대건신부제주표착기념관#자구내포구#차귀도#수월봉#공공누리#겨울여행#제주도 더보기 즐겨찾기 공유하기
자연 속에서 더욱 단단해지는 가족애, 제주돌문화공원과 교래자연휴양림 제주도 제주시 #2022년3월추천가볼만한곳#3월추천가볼만한곳#추천가볼만한곳#제주가볼만한곳#제주돌문화공원#교래자연휴양림#스누피가든#아부오름#하도리별방진#가시리유채꽃단지#사려니숲무장애나눔길#BTS#bts여행#bts투어#bts지민#제주도#공공누리 더보기 즐겨찾기 공유하기
제주도 조천읍 버킷리스트 여행지 작성하기 제주도 제주시 #제주여행#제주가볼만한곳#스위스마을#제주스위스마을#교래자연휴양림#자연휴양림#산굼부리#제주산굼부리#해안누리길#닭머르해안길 더보기 즐겨찾기 공유하기
탄소 없는 섬, 제주의 미래를 만나다_제주CFI에너지미래관 제주도 제주시 #2021_산업관광12선#제주CFI에너지미래관#제주가볼만한곳#산업관광지#신재생에너지 더보기 즐겨찾기 공유하기
위 와 같은 출력 값을 볼 수 있다.
# 텍스트를 추출하여 txt 파일에 저장
# 현제 페이지에 있는 내용을 화면에 출력하는 것이 아니라 파일에 저장 -> 리다이렉션
orig_stdout = sys.stdout # 출력 방향을 바꾸기 전에 원래 표준 출력 저장
f = open(f_name, 'a', encoding='UTF-8') #파일 저장 옵션 지정
sys.stdout = f #출력 방향을 바꿈
time.sleep(1)
html = driver.page_source # 화면에 떠있는 HTML 전체 코드를 불러온다.
soup = BeautifulSoup(html, 'html.parser')
blog_list = soup.find('ul', class_='list_thumType type1')
for i in blog_list:
print(i.text.strip())
print("\n")
sys.stdout = orig_stdout #원위치로 돌림
f.close()
print("요청하신 데이터 수집 작업이 정상적으로 완료되었습니다.")text를 파일로 저장 하려면 출력방향을 바꾸어 저장하는 방식이 있다. 화면에 출력하는 방식이 아닌,
파일 저장으로 출력방식을 지정하면 지정한 파일에 값이 저장되는 것을 확인 할 수 있다.