JPA를 사용할 때 , 엔티티와 연관관계 엔티티를 조회하는 방식의 차이를 비교해보고자 한다.
비교할 방식은 em.find() , join , fetch join을 이용할 경우 지연로딩과 즉시로딩에서의 어떻게 동작하는지 차이점들을 정리해보려고 한다.
먼저 , 상황을 예시로 하나 들어보자면 ,
🤔 상황
- Member 와 Team이라는 Entity가 있다.
- 둘의 관계는 다 대 일 의 관계이다.
- @Setter는 테스트이니 편의상 , 열어두겠다.
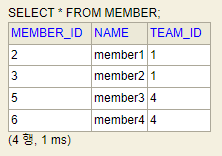
DB에 있는 데이터
//Member
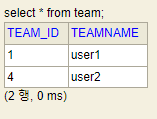
//Team
상황1 즉시 로딩의 경우
//회원 Entity
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String name;
@ManyToOne()
@JoinColumn(name = "TEAM_ID")
private Team team;
//팀 Entity
@Getter
@Setter
@Entity
public class Team {
@Id @GeneratedValue
@Column(name="TEAM_ID")
private Long id;
private String teamName;
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
상황2 지연 로딩의 경우
지연 로딩으로 설정하기 위해서위 예시에서 ```
*로 표시한 부분만 변경됨. Team은 똑같다
```java
//회원 Entity
@Entity
@Getter
@Setter
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY) *변경됨.
@JoinColumn(name = "TEAM_ID")
private Team team;이렇게 2가지 상황에서의 조회가 어떻게 다른지 정리해보자.
잠깐 짚고!!!
- 여기서 em은 EntityManager 객체를 가리키는 참조변수라고 가정하고 사용한다.
👀 em.find()
상황1의 경우
팀을 먼저 조회할 경우
Team team1 = em.find(Team.class, 1L);
for(Member m : team1.getMembers()){
System.out.println("member.name = " + m.getName());
}
@OneToMany는 기본 셋팅이 지연 로딩이다.
고로 , team1을 먼저 조회해올 경우 team을 조회하는 쿼리.
member를 for문으로 돌려 사용하는 시점중에서,
m.getName()부분이 사용될 때 member를 가져오는 쿼리를 한번 더 날린다.
회원을 먼저 조회할 경우
Member member1 = em.find(Member.class, 2L);
System.out.println(member1.getTeam().getTeamName());
@ManyToOne 기본 셋팅이 즉시 로딩으로 처리 되어있다.
그래서 member를 조회함과 동시에 , left outer join을 하여 연관관계인 team도 한번에 조회해온다.
상황2의 경우
테스트로 사용될 코드는 똑같으나 , 보기 편하려고 중복되더라도 계속 가져다 붙이겠다.
-Team은 건든게 없으니 똑같다. 고로 , 여기서는 생략
회원을 먼저 조회할 경우
Member member1 = em.find(Member.class, 2L);
System.out.println(member1.getTeam().getTeamName());em.find에서 Member만 조회해 온다.
그리고 team을 사용하는 부분에서 , 쿼리를 날려 team을 조회해 온다.
잠깐 짚고 넘어가자.
실무에서는 즉시로딩이 기본값으로 셋팅되어 있는 @ManyToOne을 모두 지연로딩으로 설정하고 들어간다고 한다.(@OneToOne도 기본이 즉시이므로 , 지연으로 변경 필요)
em.find야 다쪽을 조회하면 그래도 한번의 쿼리에 해결해주지만 , 한개의 데이터만 조회가 가능하다.
여러개의 데이터를 조회하려면 결국에는 jpql을 사용하는데 , 이때가 즉시로딩으로 설정되면 문제가 발생한다.
왜?
1. 즉시 로딩을 적용하면 , 예상치 못한 sql이 발생 된다.
2. N+1의 문제가 발생된다.
👀 Jpql
- JPQL이 사용되므로 , 여러개의 엔티티를 조회할 수 있다.
- jpql은 em.find와 달리 , 즉시 로딩으로 되어도 조회시 , 연관관계를 함께 조회하기 위해 쿼리를 추가적으로 날린다.
상황1의 경우
팀을 먼저 조회할 경우
List resultList = em.createQuery("select t from Team t").getResultList();
- team은 @OneToMany이므로 지연로딩이 기본 값이다 .
그로 인해 , Member를 조회하는 쿼리를 추가적으로 날리지 않고 team만 조회해 온다.
-team에서 member를 사용하는 코드가 있을 경우 , 그때 조회하는 쿼리를 날린다.
#### 회원을 먼저 조회할 경우
```java
List resultList = em.createQuery("select m from Member m").getResultList();- @ManyToOne은 기본값이즉시 로딩이다. 그로 인해 , team을 조회해옴과 동시에 연관관계인 Member를 조회하는 쿼리를 날린다.
상황2의 경우
팀을 먼저 조회할 경우
- 상황 1과 같다.
회원을 먼저 조회할 경우
List resultList = em.createQuery("select m from Member m")- team데이터를 사용하는 순간, team을 조회하는 쿼리를 날린다.
👀 fetch Join
-
JPQL로 엔티티를 가져올 때 한번의 쿼리에 연관관계를 같이 가져오기 위해 사용한다.
-
한번의 쿼리로 해결하기 때문에 , N+1문제를 방지할 수 있다.
Join과 혼동하면 안된다.(내가 처음에 그랬다 ㅋㅋㅋ)
둘 다 같은데 뭐하러 따로 이름까지 지어가며 , 쓰나......
싶었었다.em.createQuery("select m from Member m left join m.team") -> 회원 필드만 들고온다.
em.createQuery("select m from Member m left fetch join m.team") -> 회원 필드와 팀필드 모두 가져온다.
fetch join의 경우는 일단, 지연 로딩과 즉시 로딩에서의 차이를 설명할 필요는 없을 것같다.
어차피 한번에 조회해 오니까...
이 부분은 fetch join을 사용하게 되는 이유에 대해서 짚고 넘어가는 것이 좋을것 같다.
왜 지연 로딩을 쓰는가?
-
em.find의 경우 pk를 찍고 한번에 조회해오기 때문에 나름 최적화가 된다.
-
jpql의 경우 그렇지 못하다.
그로 인해, 즉시 로딩일 경우 사용하지도 않을 연관관계를 가져오기 위한 추가쿼리 문제가 발생. -
예상치 못한 쿼리가 나간다.
이런 이유들로 지연 로딩을 기본값으로 써야 한다.
fetch join을 왜 쓰는가?
-
사실 즉시 로딩이던 , 지연 로딩이던 jpql을 쓰는 이상 ,
연관관계 엔티티의 데이터도 사용하기 위해서는 n번 이상의 쿼리가 날라가야 한다.이를 한번의 쿼리로 조회하기 위함.
잘못된 부분은 지적 해주시면 감사하겠습니다.
