공부 내용 정리 목적입니다.
참고 : 양희재 교수님(OS)
참고 : https://velog.io/@codemcd/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9COS-13.-%ED%8E%98%EC%9D%B4%EC%A7%95
1.해결방안
1)Compaction
단편화 된 hole들을 하나로 모아주는 것을 의미한다.
단 , hole들을 이동할 때 어느 hole을 옮기는 것이 가장 효율적인지 계산하는 작업과 ,
그 hole들을 모아주기 위해 이동 되어져야 할 프로세스들 때문에 부담이 크다.
2)Paging
메모리에 로드하려는 프로세스를 분리 시켜 로드 한다.
한가지 의문점이 생긴다. 그동안은 메모리에 그래도 프로세스 하나가 매번 주소는 바뀔 지 언정
연속된 공간에 할당되어 실행 되었다.
만일 분리 되어 실행할 경우 별도의 MMU를 두어 cpu를 속이는데 어떻게?
paging이라는 것은 프로세스의 크기를 나눌 때 동일한 크기로 나눈다.
예를 들어 100byte 짜리 프로세스가 있을때 페이징 크기를10byte로 선정할 경우 ,
프로세스는 10byte씩 10부분으로 나눠질 것이고 , 제 각기 메모리의 빈 부분에 들어가게 될 것이다.
이때 MMU에서는 각 분리된 페이징들의 메모리 주소와 CPU가 보내는 논리적 주소마다 relocate register를 매핑하여 테이블 형태로 관리해주고 맵핑 하여 연속 메모리를 참조하는 것처럼 CPU를 속인다.
(맵핑 해주기위해서 많은 relocate register를 가지고 있는 mmu를 페이지 테이블이라고 한다.)
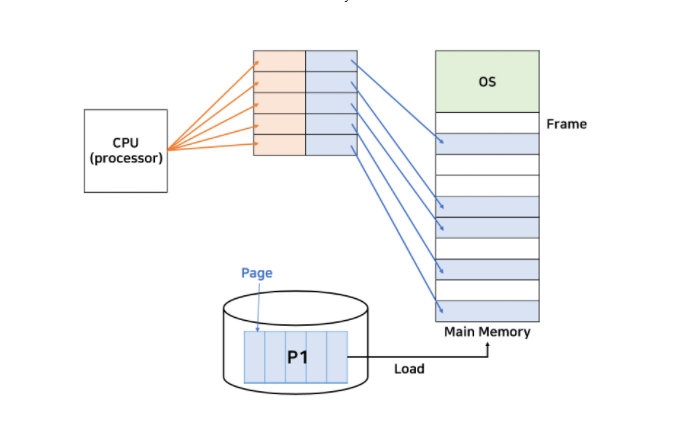
참고 : 프로세스를 나눈 조각을 page / 메모리를 나눈 조각을 frame라고 한다.
즉 , 프로세스는 page의 모음이고 , 메모리는 frame의 모음이라고 할 수 있다.2.내부 단편화란
page단위로 적재된 경우에도 hole들이 페이지 크기의 배수가 아니어서 남게 되는 경우를 의미한다.
사실, 내부 단편화는 해결방안이 없다. 하지만 외부 단편화에 비해 낭비되는 메모리 공간은 무시할 정도로 매우 작다.
1)페이지 테이블 만들기
cpu와 메모리 사이에 페이지 테이블이 있는 것처럼 위에서 표현하였다.
맞는 말이긴 하지만 , 다른 방법들이 더 있다.
1-1) cpu 내부에 레지스터로 만들기
주소 변환이 빨라진다는 장점이 있다. 하지만 cpu내부의 register를 이용하는 만큼 페이지 테이블의 크기가 커질 수록 제한이 된다.
1-2) 메인 메모리에 넣어 만들기
cpu내부에 생성하는 것과 정반대다 . 페이지 테이블의 크기가 커도 사용할 수 있지만 주소 변환이 느리다.
1-3) TLB(Translation Look-aside Buffer)
페이지 테이블을 캐시로 만들어서 해결한다.
CPU보다 변환 속도는 느리고 메모리보다 테이블 크기는 작지만, CPU보다 테이블 크기가 크고 메모리보다 변환 속도가 빠르다.
메모리와 CPU사이에 위치하여 위 두 방법의 극단적인 장단점을 보완하였다.
2)보호와 공유
보호(Protection)
모든 주소는 페이지 테이블을 경유하므로, 테이블을 이용해서 보호 기능을 수행할 수 있다. 대표적으로 페이지 테이블마다 r(read), w(write), x(execute) 비트를 두어, 해당 비트가 켜져 있을 때 그 수행이 가능 하도록 한다.

공유(Sharing)
공유는 메모리 낭비를 방지하기 위함이다. 같은 프로그램을 쓰는 복수 개의 프로세스가 있다면, 프로세스의 메모리는 code + data + stack 영역으로 나뉘는데 프로그램이 같다면 code 영역은 같을 것이다. 그러므로 하나의 code 영역을 복수 개의 프로세스가 공유하여 메모리 낭비를 줄이는 것이다. 단, code가 공유되려면 code가 변하지 않는 프로그램이어야 한다. 이를 non-self-modifying code = reentrant code(재 진입가능 코드) = pure code 라고 한다.
