Elastic 7.11 & 7.12 Webinar
Elastic Korea에서 진행한 웨비나 내용을 정리합니다.
Schema on read(런타임 필드)
기존 엘라스틱서치는 쓰기 스키마만 지원하였습니다. 하지만 7.11 버전부터 읽기 스키마도 지원하게 되었습니다.
쓰기 스키마의 경우 데이터를 저장할 때 필드를 추출하고 데이터를 매핑하는 작업을 진행하고 읽기 스키마의 경우 데이터를 있는 그대로 저장하여 쿼리를 던지는 시점에 필드를 추출하고 스키마를 부여합니다.
먼저 쓰기 스키마, 읽기 스키마 장점에 대해 알아보겠습니다.
-
쓰기 스키마 장점
- ETL(Extract, Transform, Load) => 쿼리 요청에 바로 대응
- 빠른 처리 속도
- 데이터의 볼륨이 커지더라도 일정한 쿼리 성능
-
읽기 스키마 장점
- ETL 없이 거의 그대로 저장 => 쿼리 요청시에 필요한 필드를 준비
- 유연한 데이터 인제스트(Ingest)
- 데이터에 대한 사전지식(Knowledge)없이 시작
- 빠른 인제스트
Elastic 최신 버전에서는 두가지 장점을 결합하였습니다.
예를 들어
218.30.103.62 - - [17/Jan/2019:07:27:57 +0000] "GET /blog/wow.html HTTP/1.1" 200 11388위와 같은 로그 데이터를 파일비트로 엘라스틱서치에 색인한다고 가정합니다.
{ _source: {
"@timestamp": "2019-01-17T07:27:57.956Z",
"ipaddr": "218.30.103.62",
"method": "GET",
"url": "/blog/wow.html",
"status": 200,
"bytes": 11388
}
}위처럼 쓰기 스키마를 통해 데이터가 파싱, 매핑되어 데이터가 색인됩니다.
하지만 쓰기 스키마의 경우 유연성이 떨어집니다. 이러한 단점을 보완하고자 새로운 필드나 필드끼리 합칠 수 있는 런타임 필드를 제공합니다.
Ex) "request" 필드 = "method" + "url"
런타임필드의 특징은 다음과 같습니다.
런타임 필드(Runtime Fields)
- 필요할 때 생성되는 다이나믹 필드(스크립트 등을 통해서 스키마 부여)
- 맵핑 혹은 쿼리 시에 정의되는 필드
- 작은 스토리지 사용과 빠른 인제스트
- 성능이 저장된 필드(Index Field)에 비해서 느림
- 다른 필드처럼 자유롭게 활용
- 기존 존재하는 필드를 필드명으로 사용 가능(기존 필드 데이터를 변형하고 싶을 때)
런타임 필드는 쿼리가 기존에 색인된 인덱스에 들어오는 시점에서 만들어지는 메모리상에 존재하는 필드입니다. 색인된 필드는 저장된 필드, 런타임 필드는 메모리에 만들어지는 필드입니다. 다만 쿼리 입장에서 같은 필드가 두개가 있으면 우선적으로 런타임 필드를 먼저 참조합니다.
Cold Tier
기존의 Hot/Warm Datanode 이외의 Cold/Frozen DataNode를 출시하였습니다.
Cold Tier의 경우 물리적 Hard 용량을 절약하기 위한 Tier입니다.

기존 Hot/Warm Tier의 경우 레플리카를 Hard에 저장하였습니다. 하지만 Cold Tier에서는 Primary Shard는 Hard에 저장하고 레플리카는 저렴한 저장소에 Snapshot으로 저장하여 물리적 장비의 부담을 줄여 주었습니다.
스냅샷이란?
스냅샷은 기존에 엘라스틱서치 클러스터에 저장되어 있는 인덱스들과 상태 정보들을 백업하는 메커니즘입니다. 데이터베이스의 백업 개념으로 보시면 됩니다. 보통 백업된 데이터를 다시 검색하거나 분석하려면 백업된 스냅샷을 다시 불러와서 검색해야 되는 데 지금 설명하는 검색가능한 스냅샷은 스냅샷 상태에서 바로 검색 분석이 됩니다.
Cold Tier의 경우 원본데이터(Primary shard)에 문제시 복제본(SnapShot)에서 샤드를 복구한 이후 검색이 가능합니다. 복구하는 시간이 있기 때문에 쿼리 속도가 느려지는 단점은 존재합니다.
다음은 Hot/Warm Tier와 Cold Tier의 비교표입니다.
| Hot/Warm Tier | Cold Tier |
|---|---|
| 원본 샤드와 복제본 샤드를 모두 로컬에 저장 | 복제본 샤드를 S3와 같이 저렴한 오브젝트 스토어에 저장해서 로컬 스토리지의 공간을 최적화(50% 비용 절감 효과) |
| 데이터의 읽기/쓰기를 모두 지원 | 읽기 전용(Read-only) 데이터에 사용 |
| 쿼리를 여러 데이터 노드에 분산시켜서 처리함으로써 쿼리 속도를 향상 시키는 것이 가능(복제본도 쿼리에 참여) | 쿼리를 분산시켜서 처리하는데 제한이 있어서 쿼리 속도가 조금 느려짐 |
| 일시적인 데이터 노드 문제에도 일정한 쿼리 성능을 보장 | 데이터 노드에 문제가 발생시에 쿼리 속도가 저하될 수 있음(스냅샷에서 샤드 복구하는 시간 등) |
Frozen Tier
프로즌 티어의 경우 스토리지를 분리하여 성능을 절충하면서 적은 비용으로 데이터를 유지하고 검색할 수 있는 동시에 검색에 필요한 전용 리소스 수를 줄일 수 있습니다.
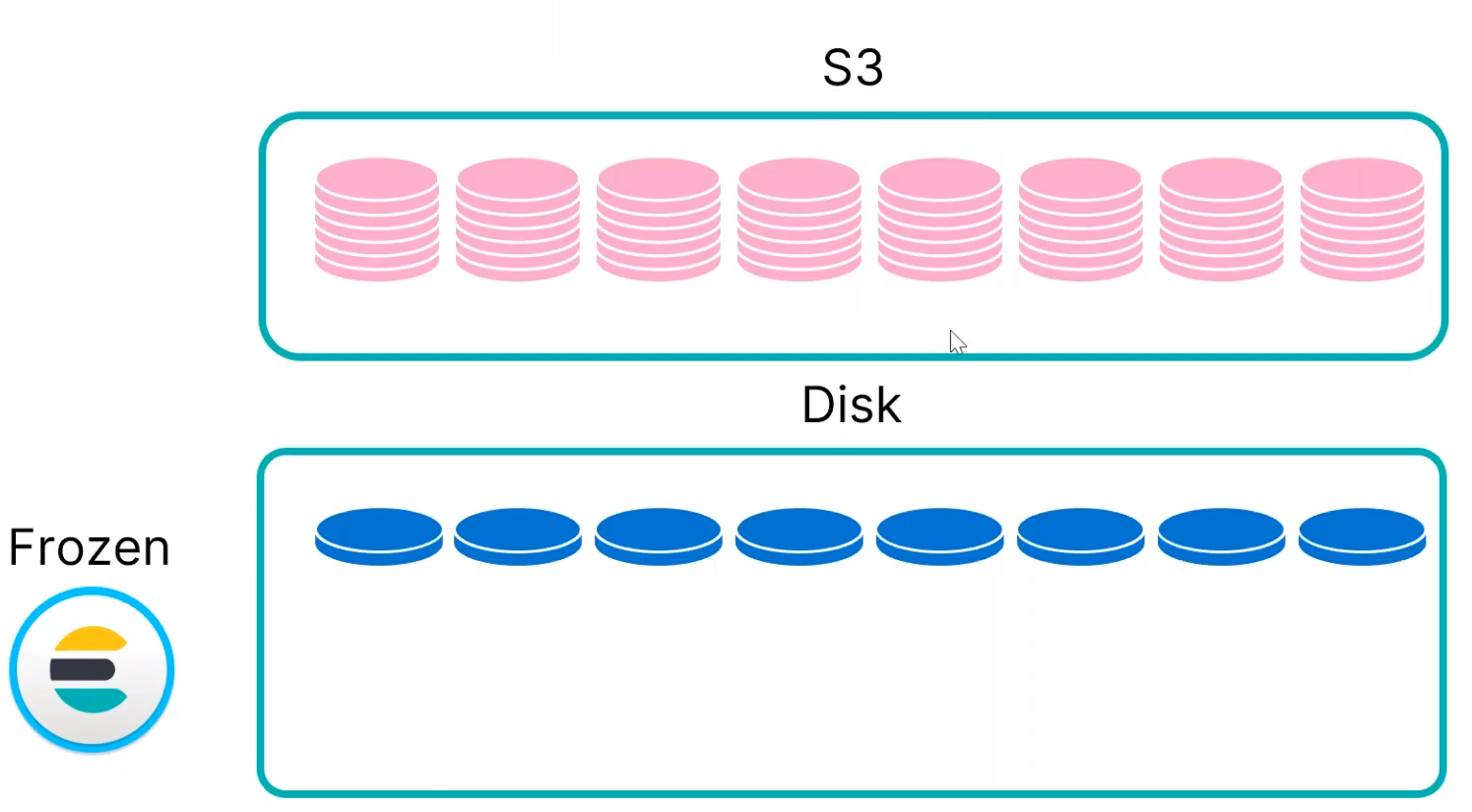
프로즌 티어는 콜드티어와 반대로 원본 데이터(Primary Shard)를 S3에 디폴트로 저장합니다. 쿼리 요청이 들어오게 되면 필요한 데이터만 Hard에 올린 다음에 쿼리를 추출합니다.
프로즌티어의 효율성
- 비용 효율적인 메모리 대비 처리하는 데이터의 비율(1:1600)
(Ex : 64G 메모리로 102TB를 처리) - 루신 레벨의 최적화를 통해 최소한의 리소스를 사용하도록 설계
- 이미 인덱싱된 데이터이고 필요한 데이터 구조만 가져오도록해서 대용량의 데이터에 대해서도 비교적 빠른 검색 속도를 지원
(Ex : Warm Tier에서 수초단위 성능인 경우 Frozen Tier에서는 수분단위의 성능(적용시에 테스트 필요))
Hot/warm/Cold/Fronze 티어에 어떤 데이터들을 저장하고 어떤 방식으로 데이터를 분류하는지 유스케이스가 있을까요?
데이터 티어링은 일반적으로 시계열 데이터를 처리할 때 일반적인 유스케이스라서 로그나 메트릭 분석쪽은 거의 데이터 티어링을 사용하고 있습니다. 보통 실시간으로 볼 기간, 실시간이 아니라 배치로 볼 기간에 대한 데이터 정책을 먼저 정하고 나서 이용하면 되겠습니다.
https://www.elastic.co/kr/blog/implementing-hot-warm-cold-in-elasticsearch-with-index-lifecycle-management
Background Search Sessions : 비동기 서치(Async Search)
비동기 서치
- 대량의 데이터에 대해서 오래 걸리는 쿼리를 백그라운드에서 실행하여 처리된 데이터부터 비동기적으로 전달하고 그 실행 경과를 관리하는 비동기 검색
- 비동기 서치를 세션으로 관리하는 기능을 추가
- 동기 서치의 타임아웃에 구애받지 않고 백그라운드에서 쿼리를 실행
- 콜드 프로즌 티어의 대용량 데이터에 대해서도 배치 쿼리를 실행할 수 있음
