
Char
char는 character(문자)의 약어이다.
일반적으로 char는 1바이트를 할당 받지만, Rust는 4Byte를 사용한다.
Rust에서 char 타입은 Unicode Scalar를 표현하는 타입이다.
즉, 억양 표시가 있는 문자, 한국어, 중국어, 일본어 등의 표의문자, 이모티콘, 공백 문자 모드가 Rust에서는 Char 타입으로 사용될 수 있는 것이다.
Unicode Scalar
유니코드 스칼라란 유니 코드 표준에서 사용되는 용어이다.
하나의 문자는 각 문자를 나타내는 고유한 숫자 값을 가지고 있게 된다.
🤔 문자에 대한 인간의 직관이 유니코드 정의에 매핑되지 않을 수 있음을 주의해야 한다.
유니코드 스칼라는 일반적으로 16진수 표기법으로 나타내며 U+ 접두사 다음에 16진수 숫자가 오게 된다.
예를 들어,
1. 라틴 대문자 A의 유니코드 스칼라 값은 U+0041이고,
2. 그리스 문자 Α (알파)의 유니코드 스칼라 값은 U+0391이다.
let 라틴_A = char::from_u32(0x0041).unwrap(); // U+0041
let 그리스_A = char::from_u32(0x0391).unwrap(); // U+0391
println!("Latin A: {}", 라틴_A);
println!("Greek Alpha: {}", 그리스_A);즉, String에서 index를 찾지 못하는 것과 유사하다 UTF-8을 사용하게 되면 1바이트에서 4바이트까지 동적으로 나오게 되는 것과 비슷하다!
- 유니코드 스칼라 값에 대한 범위

출처: https://www.unicode.org/glossary/#unicode_scalar_value
Char는 Unicode Character Database 기준이다.
is_alphabetic- Alphabetic Property를 가지고 있는 Char라면 true를 반환한다.
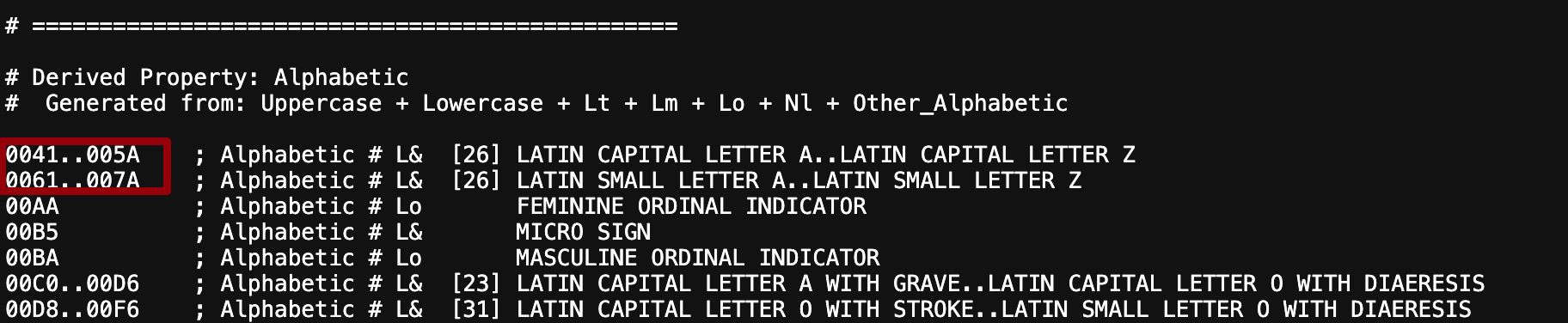
- 잘 보면
0041..005A까지는 Alphabetic이고0060은 포함되지 않는다!!
fn main () {
let latin_a = char::from_u32(0x0041).unwrap();
let char_2 = char::from_u32(0x0042).unwrap();
let char_3 = char::from_u32(0x0060).unwrap();
dbg!(latin_a); // A
dbg!(latin_a.is_alphabetic()); // true
dbg!(char_2); // B
dbg!(char_2.is_alphabetic()); // true
dbg!(char_3); // ` 빽틱!
dbg!(char_3.is_alphabetic()); // false
}- 대부분이 이 데이터베이스를 기준으로 하는 메소드가 많이 존재한다.
is_uppercase,is_whitespace,is_control...- Docs를 들어가 보면 확인해 볼 수 있다!
Unicode Character Database
Unicode Character Database2
Unicode Character Database3
정리
- 러스트의 문자는
유니코드를 기반으로 이루어진다. - 러스트에서 문자는 우리의
직관적으로이어지지 않는다.
-> 즉, 우리의 문자는 유니코드와직관적으로이어지지 않는다. - 유니 코드는 이모지, 한글, 아랍어, 표의문자, 아스키 등 유니코드 코드 포인트를 지원합니다.
-> 따라서 러스트는국제화 및 다국어 어플리케이션의 요구 사항을 충족시키기 위한 텍스트 처리에 적합한 언어이다! - Char 타입은 기본적으로 1바이트가 아니라
4바이트의 공간을 할당 받는다.
-> UTF-8은 1~4바이트로 구성되기 때문이다!
참고 자료
https://doc.rust-lang.org/std/primitive.char.html
https://www.unicode.org/glossary/#unicode_scalar_value
https://coding-insight.com/docs/rust/data-types/scalar/char/
