한글
한글은 초성, 중성, 종성으로 이루어져 있다.
초성 중성 종성의 사전적 정의는 아래와 같다.
초성 2 初聲
1.명사 언어 음절의 구성에서 처음 소리인 자음. ‘님’에서 ‘ㄴ’ 따위이다.
2.명사 음절의 구성에서 처음 소리의 자리.중성 3 中聲
1.명사 언어 음절의 구성에서 중간 소리인 모음. ‘땅’에서 ‘ㅏ’, ‘들’에서 ‘ㅡ’ 따위이다.
2.명사 음절의 구성에서 중간 소리의 자리.종성
종성 4 終聲
1.명사 언어 음절의 구성에서 마지막 소리인 자음. ‘감’, ‘공’에서 ‘ㅁ’, ‘ㅇ’ 따위이다.
2.명사 음절의 구성에서 마지막 소리의 자리.
예를 들면 김 -> ㄱ, ㅣ, ㅁ 으로 분리되고 앞의 순서대로 초성, 중성, 종성이 되는 것이다.
유니코드
한글을 표현하기 위해서 보통 유니코드를 활용한다.
유니코드는 The Unicode Standard의 약자로 전 세계의 모든 문자를 컴퓨터에서 일관적으로 표현하고 다룰 수 있도록 설계된 표준 코드이다.
⛳️ 유니 코드의 목적은 현존하는 문자 인코딩 방법을 모두 유니코드로 대체하여 다국어 환경에서 호환되지 않는 문제점을 해결하기 위함이다.
한글 소리는 유니코드에서AC00 ~ D7A3 사이의 값 11,172개의 코드를 할당 받고 있다.
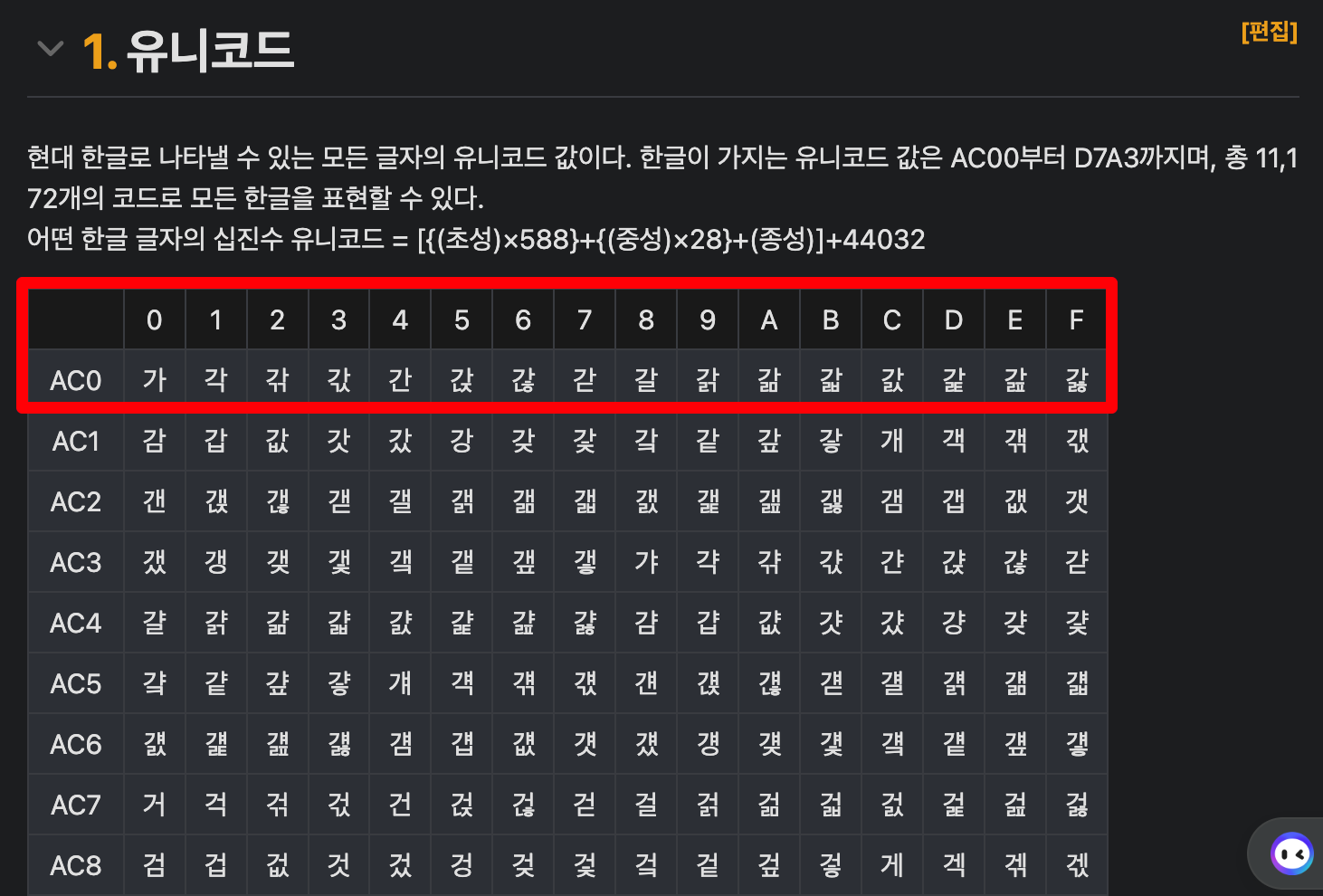
현대 한글의 모든 글자/유니코드를 보면 시작 코드U+AC00가 가인 것으로 확인할 수 있다.
🤔 그럼 소리를 구성하는 자/모음 ㄱ... ㅎ, ㅏ.. ㅔ 등은 어디에 있을까?
유니코드 영역 위키백과를 들어가보면 한글 자모가 U+1100 ~ U+11FF에 위치하고 있는 것을 확인 할 수 있다.

초성 중성 종성
한글을 표현하기 위해서는 초성, 중성, 종성의 조합이 필요하다.
현대 한글에서 초성, 중성, 종성을 활용하여 표현할 수 있는 경우의 수는 11,172(19 21 28)개이다.
-> 한글에서 초성은 19개, 중성은 21개, 종성은 28개가 존재하기 때문이다.
우리는 위에서 유니코드에서 U+AC00 ~ U+D7A3까지 소리 마디마다 코드를 매핑해 놓은 것을 확인했다.
✅ AC00(44032) - D7A3(55203) + 1 = 11,172
유니코드 초성/중성/종성 순서 값
한글 소리 마디 유니 코드에서 초성/중성/종성에 대한 순서 값은 아래와 같다.
| 값 | 초성 | 중성 | 종성 | 값 | 초성 | 중성 | 종성 |
|---|---|---|---|---|---|---|---|
| 0 | ㄱ | ㅏ | 채움 | 14 | ㅊ | ㅜ | ㄿ |
| 1 | ㄲ | ㅐ | ㄱ | 15 | ㅋ | ㅝ | ㅀ |
| 2 | ㄴ | ㅑ | ㄲ | 16 | ㅌ | ㅞ | ㅁ |
| 3 | ㄷ | ㅒ | ㄳ | 17 | ㅍ | ㅟ | ㅂ |
| 4 | ㄸ | ㅓ | ㄴ | 18 | ㅎ | ㅡ | ㅄ |
| 5 | ㄹ | ㅔ | ㄵ | 19 | ㅢ | ㅅ | |
| 6 | ㅁ | ㅕ | ㄶ | 20 | ㅣ | ㅆ | |
| 7 | ㅂ | ㅖ | ㄷ | 21 | ㅇ | ||
| 8 | ㅃ | ㅗ | ㄹ | 22 | ㅈ | ||
| 9 | ㅅ | ㅠ | ㄺ | 23 | ㅊ | ||
| 10 | ㅆ | ㅘ | ㄻ | 24 | ㅋ | ||
| 11 | ㅇ | ㅛ | ㄼ | 25 | ㅌ | ||
| 12 | ㅈ | ㅙ | ㄽ | 26 | ㅍ | ||
| 13 | ㅉ | ㅚ | ㄾ | 27 | ㅎ |
🤔 그럼 한글 소리에서 초성, 중성, 종성 값을 특정할 수 있을까?

코드 값이 커질 때마다 매핑되어 있는 소리 음절의 변화를 보면
- 종성이 먼저 변경된다.
- 종성이 초기화되고 중성이 변경된다.
- 종성, 중성이 초기화되고 초성이 변경된다.
✅ 즉, 종성 -> 중성 -> 초성의 순서 값 순으로 오름차순되어 있는 것을 확인할 수 있다.
우리는 이제, 유니코드 시작 지점부터 규칙적인 초성, 중성, 종성의 변화 주기를 구할 수 있다.
- 종성값의 변경 주기는
1이며 28개째에 초기화된다. - 중성값의 변경 주기는
28이며 588(21 * 28)개 째에 초기화된다. - 초성값의 변경 주기는
588이며 11,172(21 28 19)개 째에 초기화된다.
초성/중성/종성 뽑아내기
🤔
가에서ㄱ,ㅏ,""로 분리해보자
가는 유니코드의 시작지점으로 U+AC00(44032) 코드 값을 가진다.
- 시작 지점(U+AC00(44032)를 뺀다.
const unicode = "가".charCodeAt() - 44032;- 초성 순서값 구하기
초성 순서값을 구하기 위해 위 unicode 값에 588(21 * 28)을 나눈 몫을 구한다.
- 중성 순서값 구하기
종성 순서값을 구하기 위해 위 unicode 값에 588(21 * 28)로 나눈 나머지를 28로 나눈 몫을 구한다.
- 종성 순서값 구하기
종성 순서값을 구하기 위해 위 unicode 값에 28을 나눈 몫을 구한다.
순서 값에 따라 미리 할당해 놓은 배열에 해당 값을 인덱스로 초성/중성/종성을 찾아낸다.
export const choseong = [
'ㄱ', 'ㄲ', 'ㄴ', 'ㄷ', 'ㄸ',
'ㄹ', 'ㅁ', 'ㅂ', 'ㅃ', 'ㅅ',
'ㅆ', 'ㅇ', 'ㅈ', 'ㅉ', 'ㅊ',
'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ',
];
export const jungseong = [
'ㅏ', 'ㅐ', 'ㅑ', 'ㅒ',
'ㅓ', 'ㅔ', 'ㅕ', 'ㅖ',
'ㅗ', 'ㅘ', 'ㅙ', 'ㅚ',
'ㅛ', 'ㅜ', 'ㅝ', 'ㅞ',
'ㅟ', 'ㅠ', 'ㅡ', 'ㅢ',
'ㅣ',
];
export const jongseong = [
'', 'ㄱ', 'ㄲ', 'ㄳ',
'ㄴ', 'ㄵ', 'ㄶ', 'ㄷ',
'ㄹ', 'ㄺ', 'ㄻ', 'ㄼ',
'ㄽ', 'ㄾ', 'ㄿ', 'ㅀ',
'ㅁ', 'ㅂ', 'ㅄ', 'ㅅ',
'ㅆ', 'ㅇ', 'ㅈ', 'ㅊ',
'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ',
];참고자료
