ROLLUP
SELECT
AUTHOR_ID,
AUTHOR_NAME,
CATEGORY,
TOTAL_SALES
FROM (
SELECT
NVL(TO_CHAR(A.AUTHOR_ID), '전체') AS AUTHOR_ID,
NVL(A.AUTHOR_NAME, '전체') AS AUTHOR_NAME,
NVL(B.CATEGORY, '전체') AS CATEGORY,
TO_CHAR(SUM(B.PRICE * S.SALES), '999,999,999') AS TOTAL_SALES
FROM BOOK B
JOIN AUTHOR A ON B.AUTHOR_ID = A.AUTHOR_ID
JOIN BOOK_SALES S ON B.BOOK_ID = S.BOOK_ID
GROUP BY ROLLUP(A.AUTHOR_ID, A.AUTHOR_NAME, B.CATEGORY)
)
ORDER BY AUTHOR_ID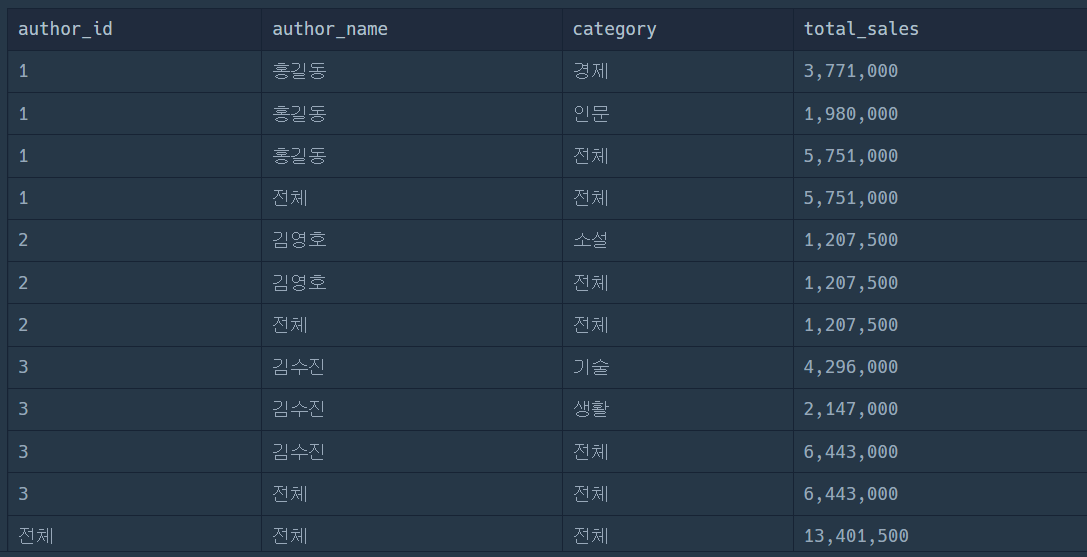
GROUP BY 시 ROLLUP으로 소계, 총합을 표현하는 코드를 작성했고, 이렇게 작성 시 1 전체 전체 5,751,000 같은 필요없는 값이 나오게 되었다. 물론 MAX 함수를 통해 AUTHOR_NAME을 뽑았다면 해결 가능하지만, 오늘 팀장님께 QUERY 교육 중 GROUPING_ID의 존재에 대해 알게 되어 정리한다.
GROUPING_ID
SELECT
AUTHOR_ID,
AUTHOR_NAME,
CATEGORY,
TOTAL_SALES
FROM (
SELECT
NVL(TO_CHAR(A.AUTHOR_ID), '합계') AS AUTHOR_ID,
NVL(A.AUTHOR_NAME, '합계') AS AUTHOR_NAME,
NVL(B.CATEGORY, '소계') AS CATEGORY,
TO_CHAR(SUM(B.PRICE * S.SALES), '999,999,999') AS TOTAL_SALES,
GROUPING_ID(A.AUTHOR_ID, A.AUTHOR_NAME, B.CATEGORY) gid
FROM BOOK B
JOIN AUTHOR A ON B.AUTHOR_ID = A.AUTHOR_ID
JOIN BOOK_SALES S ON B.BOOK_ID = S.BOOK_ID
GROUP BY ROLLUP(A.AUTHOR_ID, A.AUTHOR_NAME, B.CATEGORY)
ORDER BY AUTHOR_ID
)
WHERE gid != 3
ORDER BY AUTHOR_ID이렇게 처리하게 되면,
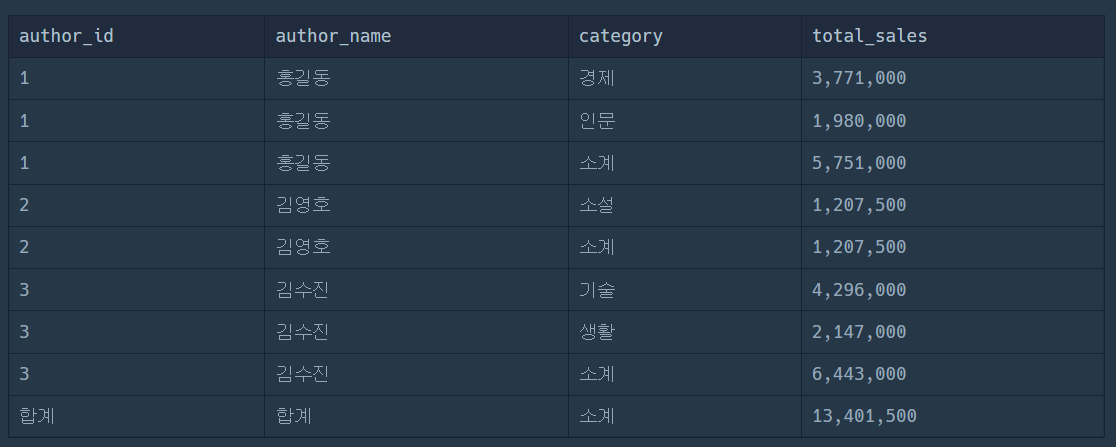
0, 0, 1, 3, 0, 1, 3, 7 이렇게 2의 3승개의 데이터가 나오게 되어 3, 3을 제거하면 우리가 필요로 하지 않았던 데이터가 사라지게 된다.
필요없는 데이터를 처리하기 위해 GROUPING_ID를 활용한 경험을 정리해보았다.

Junior Backend Developer