
시간복잡도란 무엇인가?
알고리즘에서 시간복잡도는 주어진 문제를 해결하기 위한 연산 횟수를 말한다.
일반적으로 파이썬 프로그램에서는 2000만번~ 1억번의 연산을 1초의 수행시간으로 예측할 수 있다.
알고리즘의 로직을 코드로 구현할 때 , 시간 복잡도를 고려한다는 것은 입력값의 변화에 따라 연산을 실행할 때 연산횟수에 비해 시간이 얼마만큼 걸리는가? 라는 말이다.
효율적인 알고리즘을 구현한다는 것은 바꾸어 말해 입력값이 커짐에 따라 증가하는 시간의 비율을 최소화한 알고리즘을 구성했다는 이야기이다.
시간복잡도 정의하기
시간복잡도를 정의하는 유형에는 3가지가 있다.
- 빅-오메가(Ω(n)) : 최선일때(best case) 의 연산횟수를 나타낸 표기법
- 빅-세타(θ(n)) : 보통일때(average case)의 연산횟수를 나타낸 표기법
- 빅-오(O(n)) : 최악일때(worst case)의 연산횟수를 나타낸 표기법
- 빅-오표기법은 최악의 경우를 고려하기때문에,프로그램이 실행되는 과정에서 소요되는 최악의 시간까지 고려할 수 있다.
- 최소한 특정 시간 이상이 걸린다 혹은 이 정도 시간이 걸린다 를 고려하는 것보다 이 정도 시간까지 걸릴 수 있다 를 고려해야 그에 맞는 대응이 가능하다.
- 각각의 케이스를 선택할 경우 생기는 문제를 생각해보자. 결과를 반환하는데 최선의 경우 1초 , 평균 1분 , 최악의 경우 1시간이 걸리는 알고리즘이 있다.
- 최선의 경우(빅-오메가)를 선택했을 경우
- 이 알고리즘을 100번 실행시키면 최선의 경우에는 100초가 걸린다
- 만약 실제로 걸린 시간이 1시간을 훌쩍 넘긴다면 어디에서 문제가 발생한거지? 라는 의문이 생긴다.
- 최선의 경우만 고려하였기 때문에, 어디에서 문제가 발생했는지 알아내기 위해서는 로직의 많은 부분을 파악해야 한다! 고로 문제를 파악하는데 많은 시간이 필요하다.
- 평균의 경우 (빅-세타) 를 선택했을 경우
- 알고리즘을 100번 실행할때 100분의 시간이 소요된다고 생각했는데, 최악의 경우가 발생하여 300분이 넘게 걸렸다면 최선의 경우를 고려한 것과 같은 고민을 하게 된다.
- 즉,어디에서 문제가 발생했는지 알아내기 위해서 로직의 많은 부분을 파악해야한다..
- 최악의 경우 (빅-오) 를 선택했을 경우
- 최악의 경우가 발생하지 않기를 바라며 시간을 계산하는 것보다는 최악의 경우도 고려하여 대비 하는 것이 바람직하다.
- 입력값의 변화에 따라 연산을 실행할 때 연산횟수에 비해 시간이 얼마만큼 걸리는가 를 표현하기 때문에 입력값을 변경해보며 체크가 가능하다.
- 최선의 경우(빅-오메가)를 선택했을 경우
코딩테스트에서는 어떤 시간복잡도 유형을 사용해야 할까?
코딩테스트에서는 빅-오 표기법을 기준으로 수행시간을 계산하는 것이 좋다. 실제 테스트에서는 한개의 테스트 케이스로 합격,불합격을 결정하지 않기 때문이다. 응시자가 작성한 프로그램으로 다양한 테스트 케이스를 수행해 모든 케이스를 통과해야만 합격으로 판단하기 때문에 시간복잡도를 판단할 때는 최악일 때를 염두에 두어야 한다 !
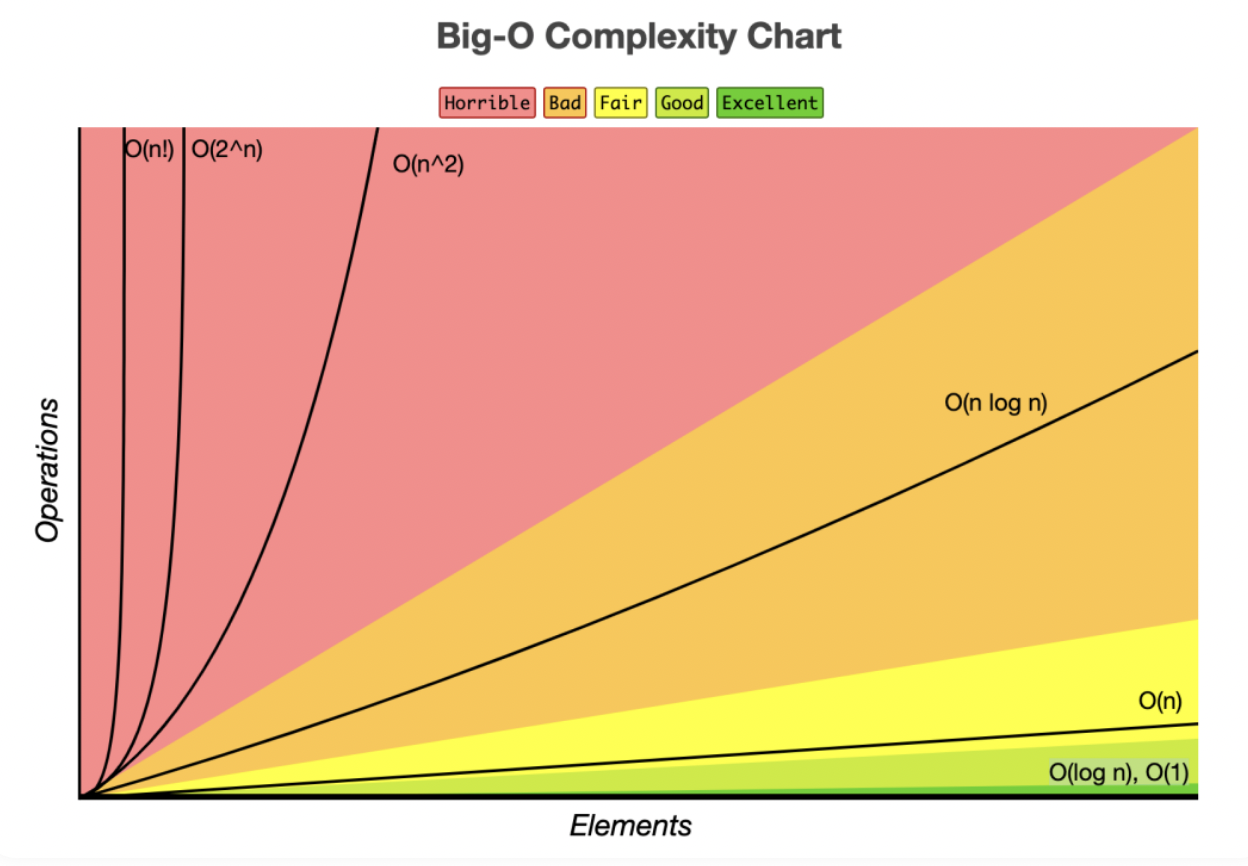
각각의 시간복잡도는 데이터 크기의 증가에 따라 성능(수행시간)이 다르다는 것을 확인할 수 있다.
시간복잡도 활용하기
버블정렬과 병합정렬의 시간복잡도를 각각 O(n^2) O(nlogn)이라고 알고있다고 가정해보자.


시간제한이 2초이므로 이 조건을 만족하려면 4000만번 이하의 연산횟수로 문제를 해결해야한다. 따라서 문제에서 주어진 시간제한과 데이터 크기를 바탕으로 어떤 정렬 알고리즘을 사용해야 할 것인지를 판단할 수 있다.
- 연산횟수는 1초에 2000만번 연산하는것을 기준으로 생각함
- 시간복잡도는 항상 최악일 때! 데이터의 크기가 가장 클때를 기준으로 함!
연산 횟수 계산 방법
- 연산횟수 = 알고리즘 시간 복잡도 N값 데이터의 최대 크기를 대입하여 도출
이 공식을 이용하여 각 알고리즘이 이 문제에 적합한지 판단해보면,
- 버블정렬 = (1,000,000)^2 = 1,000,000,000,000 > 40,000,000 → 부적합
- 병합정렬 = (1,000,000)log2^(1,000,000) = 약 20,000,000 < 40,000,000 → 적합 알고리즘
문제에 주어진 시간이 2초이기 때문에 연산횟수 4,000만번 안에 원하는 답을 구해야한다. 버블정렬의 경우 1조의 연산횟수가 필요하기 때문에 이 문제를 풀기에 적합한 알고리즘이 아니라고 판단할 수 있다. 그에 반해 병합정렬은 약 2,000 만번의 연산횟수로 답을 구할 수 있기 때문에 문제를 풀기에 적합한 알고리즘이라고 판단할 수 있다.
시간복잡도를 바탕으로 코드 로직 개선하기
시간복잡도는 작성한 코드의 비효율적인 로직을 개선하는 바탕으로도 사용할 수 있다. 시간복잡도를 도출하려면 다음 2가지 기준을 고려해야한다.
-
상수는 시간 복잡도 계산에서 제외한다.
-
가장 많이 중첩된 반복문의 수행횟수가 시간 복잡도의 기준이 된다.
→ 이를테면 O(n)과 O(3n)의 연산횟수 차이는 3배차이이지만 일반적으로 코딩테스트에서는 일반적으로 상수를 무시하기 때문에 모두 시간복잡도는 O(n)으로 같다.(개인적인 생각으로는 리미트 계산할때 상수를 무시했던것과 같은 원리라고 생각한다. 수가 엄청 커지면 제곱근이나, 제곱과 같은 연산에 비해 상수연산은 차이가 미미하기 때문이다)
'''
O(N^2)
'''
N = 100000
cnt = 1
for i in range(N):
for j in range(N):
print("연산횟수" + str(cnt))
cnt += 1
시간복잡도는 가장 많이 중첩된 반복문을 기준으로 도출하므로 이 코드에서는 이준 for문이 전체코드의 시간 복잡도 기준이 된다. 만약 일반 for문이 10개 더 있다고 하더라도 가장 많이 중첩된 반복문의 수행횟수가 시간 복잡도의 기준이 된다. 에 따라서 시간복잡도의 기준에 따라서 시간복잡도의 변화없이 N^2으로 유지된다.
가장 뛰어난 오류 탐색 방법, 디버깅
디버깅은 왜 중요할까?
프로그램에서 발생하는 문법 오류나 논리 오류를 찾아 바로잡는 과정을 디버깅이라고 한다. 문법 오류는 컴파일러가 자동으로 찾아주므로 테스트할 때 문제가 되지않는다. 논리오류는 코드가 사용자의 의도와 다르게 동작하는 것이며 다양한 형태로 발생한다.
디버깅의 중요성
많은 사람이 문법을 배우는 과정에서 디버깅을 가볍게 생각하고 넘어간다. 하지만 디버깅은 코딩테스트에 필요한 기술이고, 그냥 알아두기만 하면 되는 것이 아니라 문제를 풀면서 반드시 해야하는 과정이다. 반드시 디버깅을 익힌 후에 코딩 테스트에 응시해야한다.
디버깅하는 법
디버깅을 하는 방법은 코드에서 디버깅하고자 하는 줄에 중단점을 설정하고 IDE의 디버깅 기능을 실행해 진행하면 된다.
- 코드에서 디버깅하고자 하는 줄에 중단점을 설정한다. 이때 중단점은 여러개 설정할 수 있다.
- IDE의 디버깅 기능을 실행하면 코드를 1줄씩 실행하거나 다음 중단점까지 실행할 수 있으며, 이 과정에서 추적할 변숫값도 지정할 수 있다. 이 방법으로 변숫값이 자신이 의도한대로 바뀌는지 파악한다.
- 변숫값 이외에도 원하는 수식을 입력해 논리오류를 파악할 수 있다.
디버깅 활용 사례 살펴보기
#배열의 주어진 범위의 합을 2로 나눈 몫을 구하세요
import random
testcase = int(input())
answer = 0
A = [0]*(100001)
for i in range(0,1001):
A[i] = random.randrange(1,101)
for t in range(1,testcase+1):
start,end = map(int,input().split())
for i in range(start,end+1):
answer = answer + A[i]
print(str(testcase) + " " + str(answer/2))오류 1. 변수 초기화 오류 찾아보기
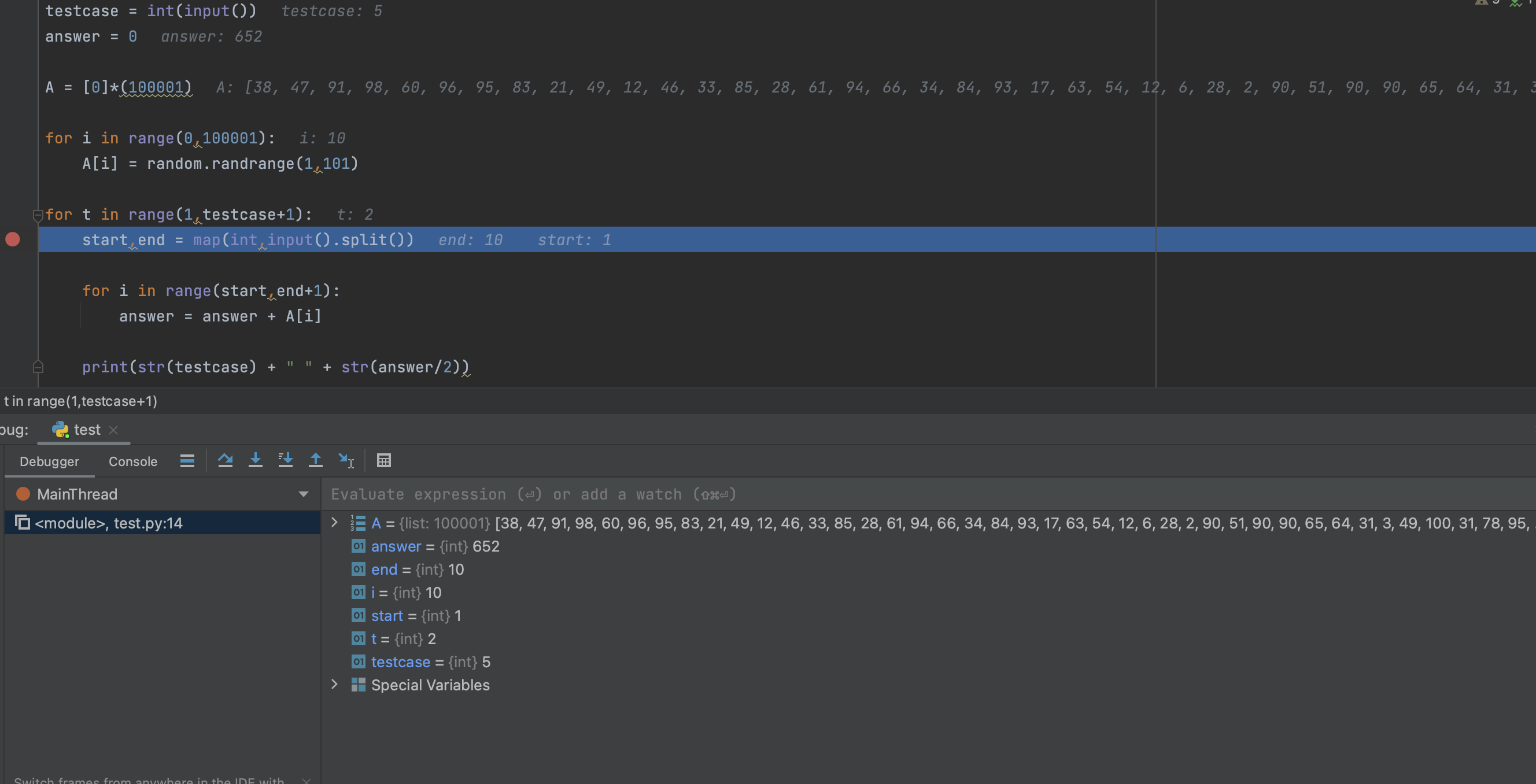
해당 코드는 각 테스트케이스마다 answer 값을 초기화해주어야하는데 해당 코드에서는 answer을 초기화해주지 못했다.
t 값이 2로 2번째 테스트케이스를 계산하는 과정에서 answer 값은 0이 되어야하는데 해당 값은 652로 초기화 되지 않았음을 알 수 있다.
이러한 변수 초기화 로직은 놓치기 쉽다. 코드가 복잡해지면 더욱 그렇다!
실제 코딩테스트의 두번째 테스트 케이스부터 통과되지않을 경우에는 모든 변수가 정상적으로 초기화되고 있는지 디버깅을 이용해 확인해보는 것도 문제 해결에 도움이 된다.
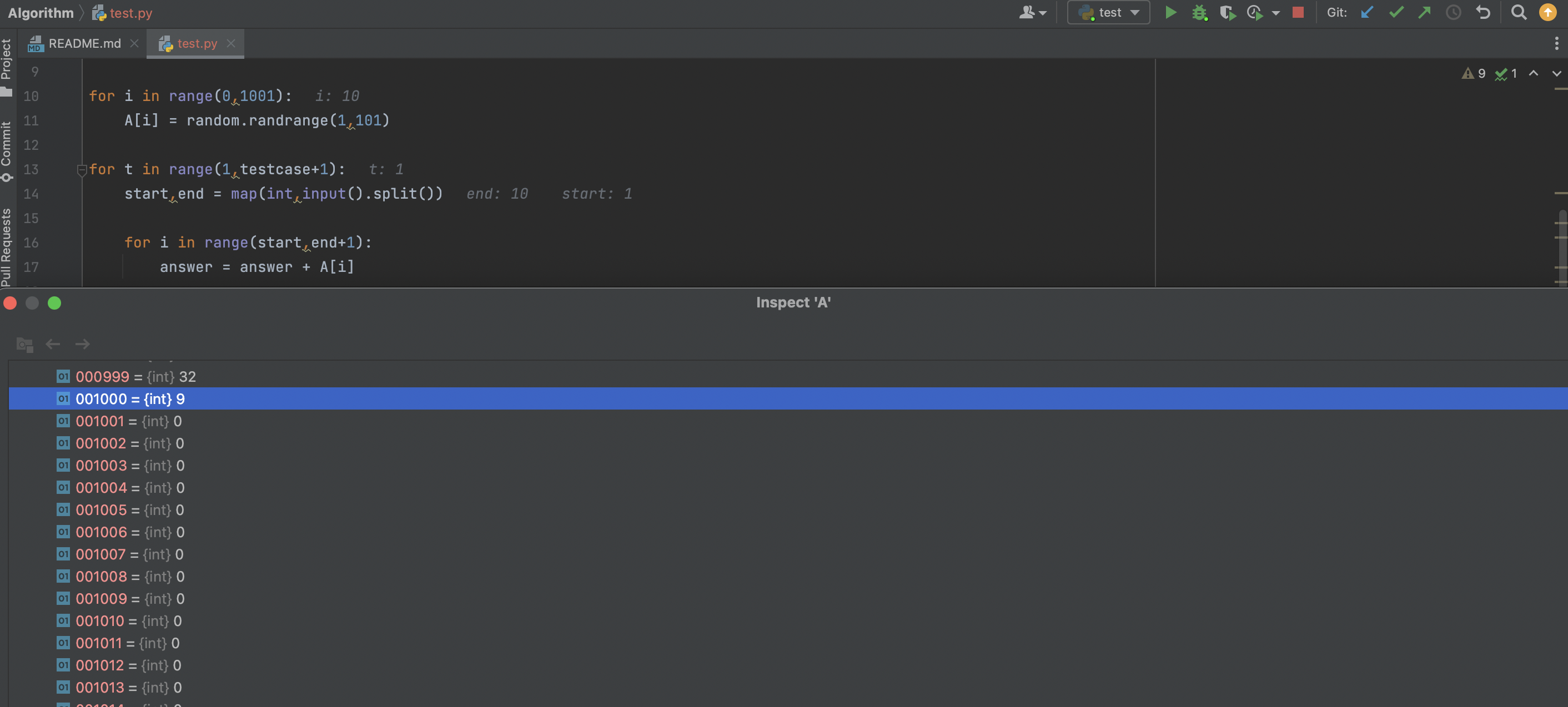
오류 2. 반복문에서 인덱스 범위 지정 오류 찾아보기
해당 오류는 반복문에서 인덱스 범위를 잘못 지정한 경우이다.
종종 반복문에서 반복 범위를 잘못 지정하거나 비교 연산자를 잘못 사용하는 경우가 있다. 위 경우 A[1001]부터 값이 모두 0으로 출력된다. 반복문에서 배열A 에 값을 제대로 저장하지 않은 것이다. 코드를 보면 반복문의 범위를 지정하는데에 있어서 문제가 생긴것을 알 수 있다.
이런경우 외에도 배열 인덱스가 0부터 시작한다는 사실을 간과하는 때도 있고 반복문을 N까지 반복하도록 설정해야 하는데 비교 연산자를 잘못 입력하여 N-1까지 반복하도록 설정하는 때도 있다. 인덱스 범위 지정 오류는 여러 형태로 발생할 수 있으니 반복문을 사용할 때마다 범위와 시작 인덱스를 꼼꼼하게 확인하고, 혹시 모를 입력 실수를 대비해 디버깅하는 습관을 들이는게 좋다.
오류 3. 잘못된 변수 사용 오류 찾아보기
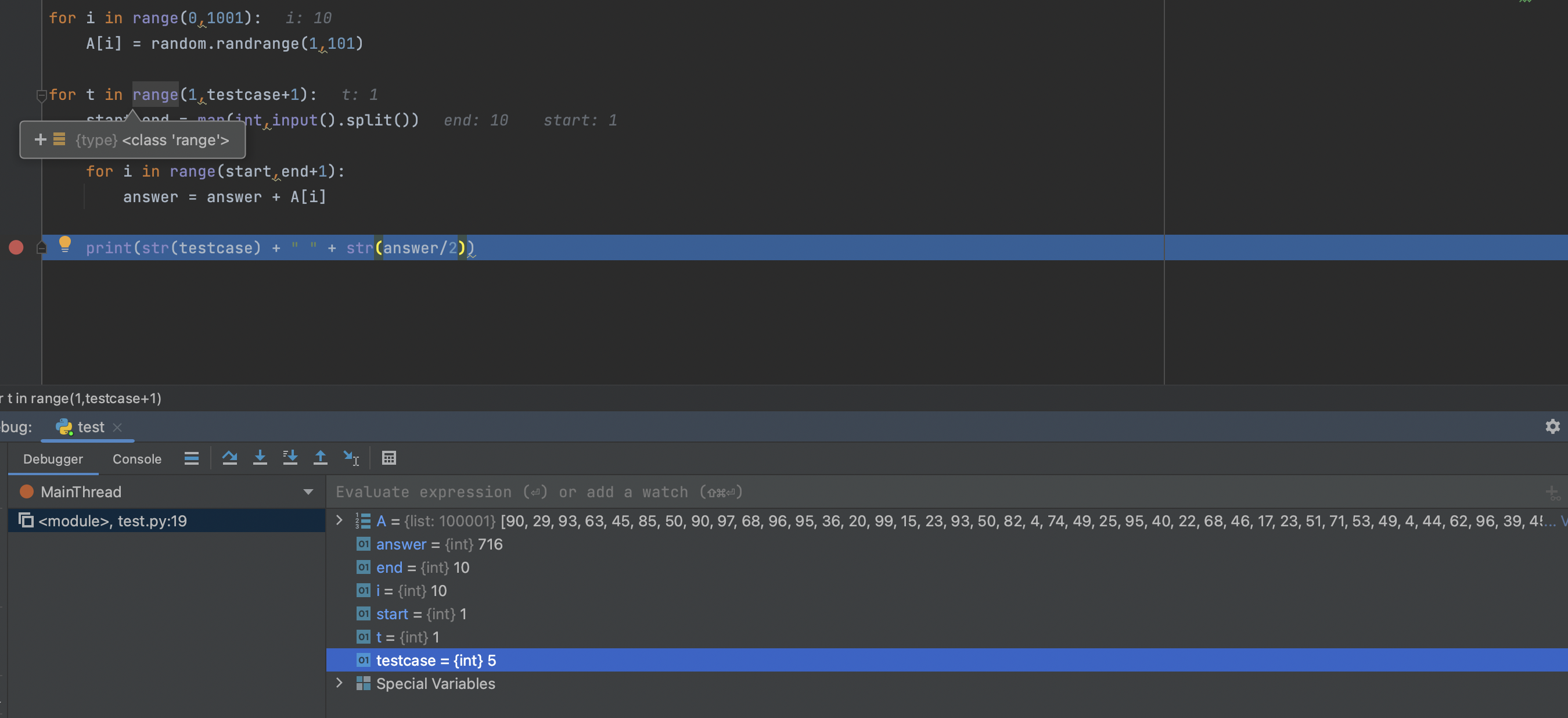
출력부분이나 로직 안에서 사용해야하는 변수를 다른 변수와 혼동하여 잘못 사용하는 경우도 있다. 예를들어 반복문에서 반복변수를 사용해야하는데 기준 변수를 사용하거나 변수 이름 자체가 비슷해서 잘못 사용하는 경우이다.
해당 코드의 경우 1번 테스트 케이스의 정답 이런식으로 출력해야하는데 testcase라는 변수를 사용해서 테스트케이스의 총 개수를 출력하고 있다. 즉, t와 testcase를 혼동하여 사용한 경우라고 볼 수 있다.
오류 4. 파이썬 자동 형 변환 조심하기
데이터 계산 도중 다양한 연산이 수행될 때 예상하지 못한 형 변환이 일어날 수 있다.
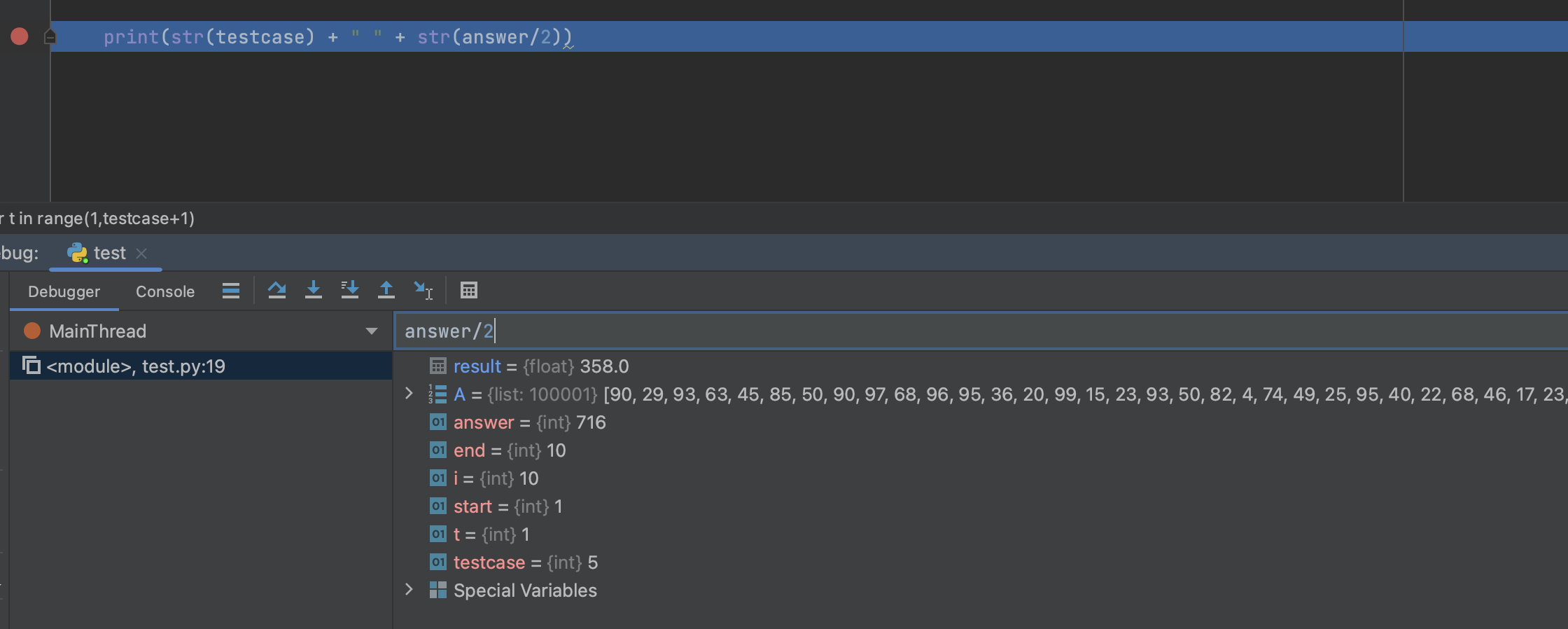
이런식으로 answer/2 값을 입력하여 주면 float형으로 자동으로 형변환이 되어 출력되는 것을 확인 할 수 있다.
실제로 문제에서 몫의 값은 자연수 값으로 출력을 원하기 때문에 제출 시 실패가 발생하게 된다.
- 실제로 파이썬에서 이런일을 방지하기 위해 // 연산자가 준비되어있으니 해당 부분을 참고하자
참고자료
