기초 통계랑(1) 대푯값
- 데이터
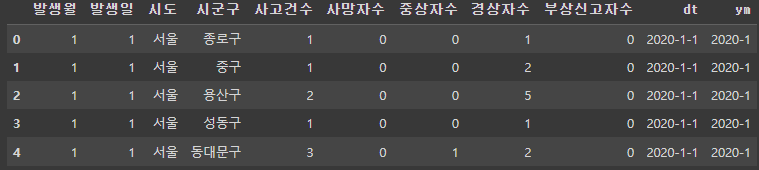
df = pd.read_excel("/content/drive/MyDrive/패스트캠퍼스/도로교통공단_일자별 시군구별 교통사고 건수.xlsx") # date format 변경 a = range(0, 59724) b = range(0, 59724) df['dt'] = pd.DataFrame(list(map(lambda x, y: '2020-'+ str(df['발생일'][x]) + '-' + str(df['발생일'][y]), a, b))) df['ym'] = pd.DataFrame(list(map(lambda x : '2020-'+ str(df['발생월'][x]), a))) df['dt'] = df['dt'].map(lambda x : datetime.strptime(x, '%Y-%m-%d').strftime('%Y-%m-%d')) df['ym'] = df['ym'].map(lambda x : datetime.strptime(x, '%Y-%m')).strfitme('%Y-%m')
평균(mean)
- 평균의 종류 : 산술평균, 기하평균, 조화평균
- 기하평균(증가율 관련) : 기본값을 1로 놓고 1에서 증가 감소하는 퍼센트를 더하거나 빼고 더워서 갯수 만큼 제곱
- 조화평균(속력관련) : 2ab/a + b
평균의 함정
- 평균을 흔드는 극단적인 값이 존재할 때도 있다.
- 평균으로 보기전에 데이터를 확인해봐야한다
산술평균
# 산술평균 df.mean() # ym별 평균 df.groupby('ym').사고건수.mean()
기하평균
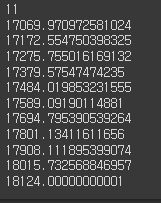
- 2020년 월 평균 사고건수의 증가율은?
tmp = pd.DataFrame(df.groupby(['ym']).사고건수.sum()).reset_index() tmp['shift_data'] =tmp['사고건수'].shift(-1) tmp['ratel'] = ((tmp['shift_data'] - tmp['사고건수']) / tmp['사고건수']) # abs는 절댓값 tmp['rate2'] = '' # 기본 1의 값에 변동 적용 tmp.loc[tmp['ratel'] < 0, 'rate2'] = 1 - abs(tmp['ratel']) tmp.loc[tmp['ratel'] > 0, 'rate2'] =abs(tmp['ratel']) +1 tmp.dropna(axis=0, inplace=True) from functools import reduce arr = tmp['rate2'] reduce(lambda x, y: x * y, arr) # 문자열들 가운데에 *삽입하여 연결 '*'.join([str(n) for n in arr]) # eval => 계산 num1 = eval('*'.join([str(n) for n in arr])) import math # pow(X,y) x**y num2 = math.pow(num1, 1/11) val = 16968 print(len(tmp)) for i in range(len(tmp)): val = val*num2 print(val)
중앙값(median)
- 데이터를 크기 순으로 정렬했을 때 가운데에 있는 데이터
# 중앙값 df.median()
최빈값(mode)
- 가장 빈도가 높은 값
# 최빈값 df.mode() # ym별 최빈값 df.groupby('ym')['사고건수'].agg(pd.Series.mode)

가보자가보자~