교공 알고리즘 스터디 26주차 카카오기출

문제풀이 (2022-03-11 FRI 💻)
⭐ 풀이의 핵심
- 순열을 구하고
- 해당 순열이 조건을 만족하는지 체크하고
- 만족한다면 answer++
생각보다 간단한 흐름이다
하지만 난 문자열을 마주쳐서 또 당황했다..^^
✅ 구글링을 통해 얻은 Tip
처음에는 vector<char> characters = {'A', 'C', 'F', 'J', 'M', 'N', 'R', 'T'}; 와 같이
프렌즈 캐릭터 이니셜을 벡터에 담아주고
int idxA = find(characters.begin(), characters.end(), data[i][0]) - characters.begin();
와 같이 algorithm 라이브러리의 find 함수를 활용하여 조건 있는 캐릭터의 인덱스를 찾아줬는데
구글링을 해보니 string characters="ACFJMNRT"와 같이 문자열에 담아주고
int idxA = characters.find(data[i][0]);와 같이
string 라이브러리의 find 함수를 활용하면
해당 라이브러리 함수 특성 상 속도가 빨라진다는 글을 보았다
실제로 수정해서 결과를 비교해보니 정말 속도 차이가 나서 신기했다
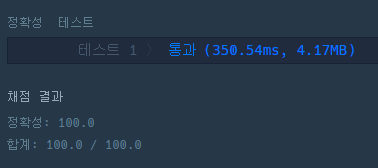
👉 벡터 + algorithm 라이브러리의 find 함수 테스트 결과
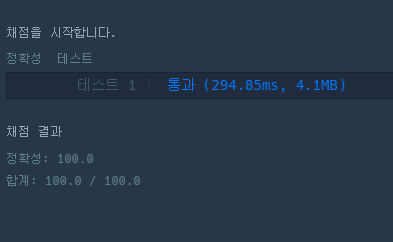
👉 문자열 + string 라이브러리의 find 함수 테스트 결과
🔽 코드 (C++)
#include <string>
#include <vector>
#include <algorithm>
#include <cstdlib>
using namespace std;
int solution(int n, vector<string> data) {
int answer = 0;
string characters = "ACFJMNRT";
do {
bool flag = true;
for (int i=0; i<n; i++) {
int idxA = characters.find(data[i][0]);
int idxB = characters.find(data[i][2]);
int distance = abs(idxA - idxB) - 1;
char sign = data[i][3];
int number = data[i][4] - '0';
if (sign == '=' && distance != number) {
flag = false;
break;
}
else if (sign == '<' && distance >= number) {
flag = false;
break;
}
else if (sign == '>' && distance <= number) {
flag = false;
break;
}
}
if (flag) { answer++; }
} while (next_permutation(characters.begin(), characters.end()));
return answer;
}스터디 (2022-03-13 SUN 📚)
✅ 스터디에서 얻은 Tip
vector<char> characters = {'A', 'C', 'F', 'J', 'M', 'N', 'R', 'T'};
do {
bool flag = true;
for (int i=0; i<n; i++) {
int idxA = find(characters.begin(), characters.end(), data[i][0]) - characters.begin();
int idxB = find(characters.begin(), characters.end(), data[i][2]) - characters.begin();
int distance = abs(idxA - idxB) - 1;
// 이후 코드 생략이처럼 벡터와 algorithm 라이브러리의 find 함수를 활용하여 코드를 짰을 경우
idxA 와 idxB 를 구해줄 때 위와 같이 characters.begin() 을 빼주는 것이
정확한 인덱스를 구하는 방법이기는 하지만
어차피 이 문제에서 idxA 와 idxB 를 구하는 이유는
이 둘의 차이를 나타내는 distance 값을 구하기 위함이므로
int idxA = find(characters.begin(), characters.end(), data[i][0]);
int idxB = find(characters.begin(), characters.end(), data[i][2]);
int distance = abs(idxA - idxB) - 1;과 같이 characters.begin() 을 빼주는 부분을 생략하여 구해도 무방하다
