
☝ 개념
머신러닝을 할 때마다 아래의 작업은 계속 반복된다.

반복되는 작업을 최대한 자동화하면 효율성을 높일 수 있을 것이다.
AutoML은 이렇게 Raw 데이터로부터 모델 배포까지를 자동화해주는 automated machine learning 이다.
🔧 기술
AutoML로 해결하고자 하는 문제는 크게 두가지이다.
- CASH(Combined Algorithm Selection and Hyper-parameter optimization)
-> 최적의 알고리즘과 하이퍼 파라미터 찾기
- NAS(Neural Architecture Search)
-> 최적의 architecture 찾기
📂 패키지 및 시스템
AutoML관련 상용 시스템 및 파이썬 패키지는 아래와 같다.
Auto-WEKA
IBM AutoAI
Microsoft AzureML
Google AutoML
Amazon SageMaker
H20 AI
Auto-sklearn
Neural Network Intelligence
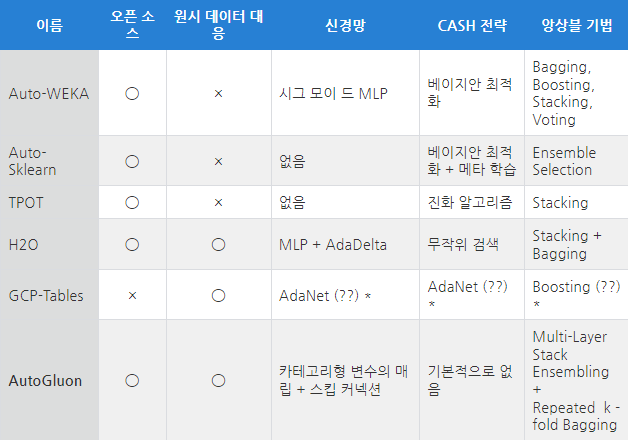
DataRobot아래는 AutoML 프레임워크들을 비교해놓은 표이다.
💧윈도우 pip설치로 H2O Auto ML 사용하기
-
java jdk11 패키지 설치
h2o는 java 8~14 버전만 호환이 가능하므로 11버전 설치하기 -
h2o패키지 설치
# h2o 설치 %pip install requests %pip install tabulate %pip install "colorama>=0.3.8" %pip install future %pip uninstall h2o %pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2o -
필요한 라이브러리 불러오기
import h2o from h2o.automl import H2OAutoML -
h2o 인스턴스 생성하기
h2o.init() h2o.no_progress() -
데이터 불러온 후 모델 학습
# train data, valid data 불러왔다고 가정. aml = H2OAutoML(max_models=20, seed=1) aml.train(x=x, y=y, training_frame=train, validation_frame=valid) -
h2o 학습 결과 저장
# View the AutoML Leaderboard lb = aml.leaderboard lb.head(rows=lb.nrows) # Print all rows instead of default (10 rows) -
예측하기
preds = aml.leader.predict(valid) -
결과 그리기
import matplotlib.pyplot as plt %matplotlib inline # 그리기 plt.figure(figsize=(40, 9)) plt.plot(valid[y].as_data_frame()['~~~'].values, 'b', label = 'actual') plt.plot(preds.as_data_frame()['predict'].values, 'r', label = 'prediction') plt.legend() plt.show()
🌐 구글 코랩에서 Auto-sklearn 사용하기
- auto-sklearn 설치하기
!pip install auto-sklearn==0.11.1 - 학습시키기
# X_train, y_train, X_test, y_test 준비된 상태라 가정. import autosklearn.regression automl = autosklearn.regression.AutoSklearnRegressor( time_left_for_this_task=120, per_run_time_limit=30, n_jobs=1 ) automl.fit( X_train, y_train )
참고자료
1. AutoML 개념
2. AutoML 프레임워크 비교
3. 5분만에 끝장내는 AutoML(h20) 사용법
4. 구글 코랩 및 autoML:Auto-sklearn 설정
