[논문 리뷰] Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
Self-Supervised Learning (NLP)
📝 참여 스터디: 거꾸로 읽는 self-supervised-learning 시즌2: Contrastive learning on NLP
🔗 논문 링크: Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
📚 발표 자료: by Dien
💻 발표 영상: by Dien
Abstract
Language models pretrained on text from a wide variety of sources form the foundation of today’s NLP. In light of the success of these broad-coverage models, we investigate whether it is still helpful to tailor a pretrained model to the domain of a target task. We present a study across four domains (biomedical and computer science publications, news, and reviews) and eight classification tasks, showing that a second phase of pretraining indomain (domain-adaptive pretraining) leads to performance gains, under both high- and low-resource settings. Moreover, adapting to the task’s unlabeled data (task-adaptive pretraining) improves performance even after domain-adaptive pretraining. Finally, we show that adapting to a task corpus augmented using simple data selection strategies is an effective alternative, especially when resources for domain-adaptive pretraining might be unavailable. Overall, we consistently find that multiphase adaptive pretraining offers large gains in task performance.
Introduction
1. Pretrained Language Model (LM)
- RoBERTa는 영어 백과사전, 뉴스, 문학 작품 등 약 160GB 이상의 대규모 corpus로 사전학습 됩니다.
- Pretrained LM은 다양한 domain에서 가져온 다양한 task에서 강력한 성능을 달성합니다.
- 하지만, 특정 domain 또는 task 데이터 분포에 일반화할 수 있는가에 대해서는 확립되지 않았습니다.
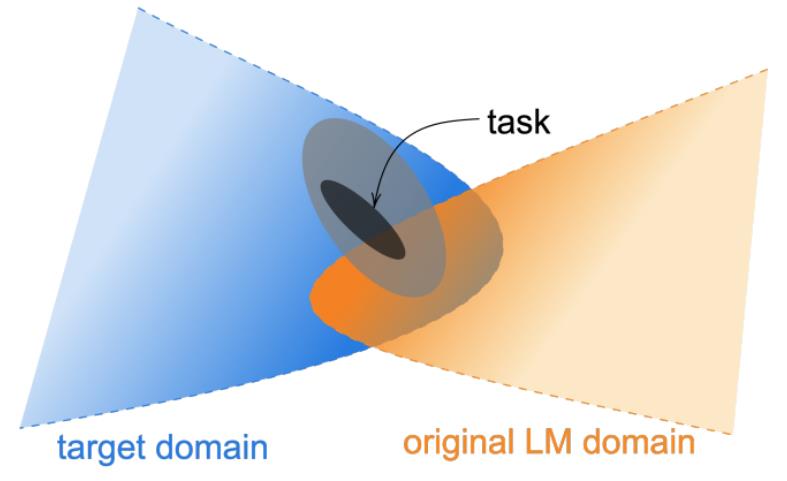
- 여기서 domain이란 특정한 주제 또는 source로 이루어진 corpus, task란 특정한 domain에서 풀고자 하는 문제라고 정의할 수 있습니다.
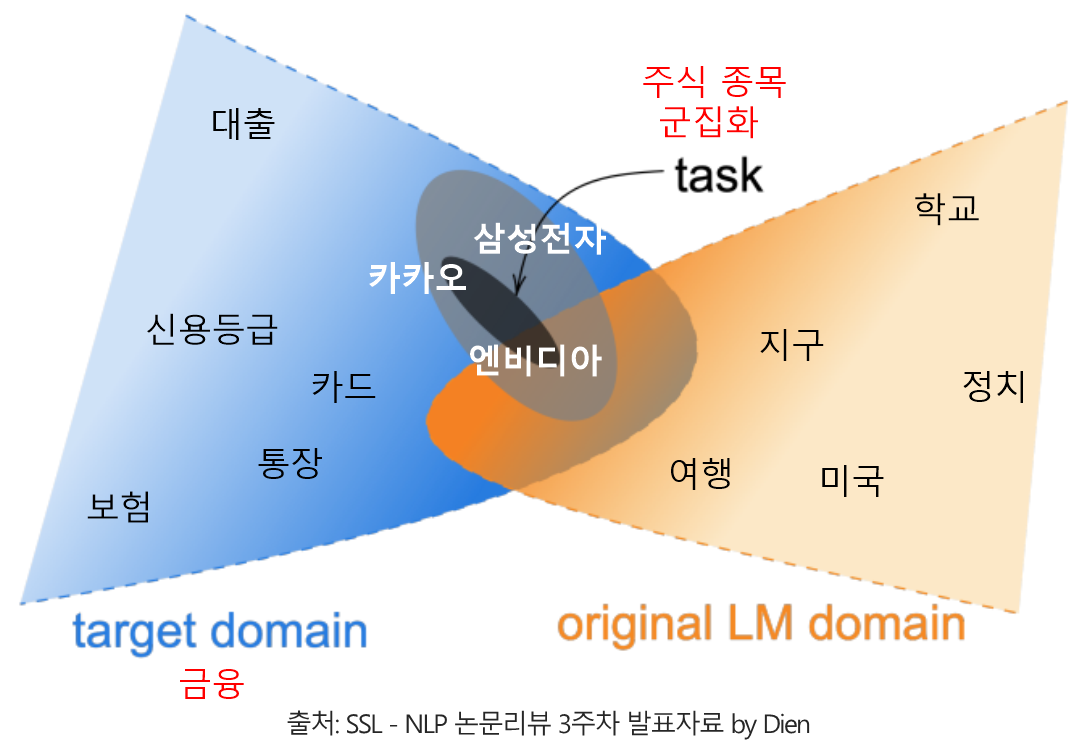
2. Adaptive Pretraining
- Adaptive pretraining이란, pretrained model을 초기 weight로 지정하고 추가로 pretraining하는 것을 말합니다.
- 본 논문에서는 4개의 domain(biomedical, computer science, news, and reviews)에 대해 각각 Domain-adaptive pretrainig(DAPT)를 수행합니다.
- 또한, Task에 보다 더 직접적으로 연관된 task-specific 데이터를 활용해 Task-adaptive pretrainig(TAPT)를 수행합니다.
- 추가로, 상대적으로 적은 데이터를 활용하는 TAPT 방법의 성능 향상을 위해 augmentation 방법을 활용합니다.
이 논문의 contribution은 다음과 같습니다.
- NLP classification 관련 4개의 domain, 8개의 task에서 Domain- and Task- adaptive pretraining에 대한 철저한 분석 진행
- Domain 및 Task 전반에 걸쳐 adapted language model의 transferability 에 대한 연구 수행
- Task adaptive pretraining 수행시 사람이 직접 augmentation 하는 방식과, kNN 을 활용해 자동적으로 augmentation 하는 방법의 효과 강조
Background
1. RoBERTa
- 대규모 corpus를 pretraining하는 대표적인 모델은 Masked language model(MLM) 방법을 활용하는 BERT 계열 모델이 있습니다.
- RoBERTa는 BERT 모델 아키텍쳐를 유지하며 BERT의 10배 규모 corpus로 pretraining되었으며, 학습단계의 여러 hyperparameter를 조정하여 최적화시켰습니다.
- 매 학습마다 새로운 masking 적용 (BERT에서는 학습 전 1번만 masking 적용)
- BERT에서 사용된 Next sentence prediction(NSP) loss 제거
- 2K 이상의 큰 batch size로 학습
- 최대 길이의 sequence length 사용
- 본 연구에서는 pretraining된 RoBERTa 모델을 활용해서 domain 및 task의 adaptive pretraining을 추가로 진행합니다.
Domain-Adaptive Pretraining
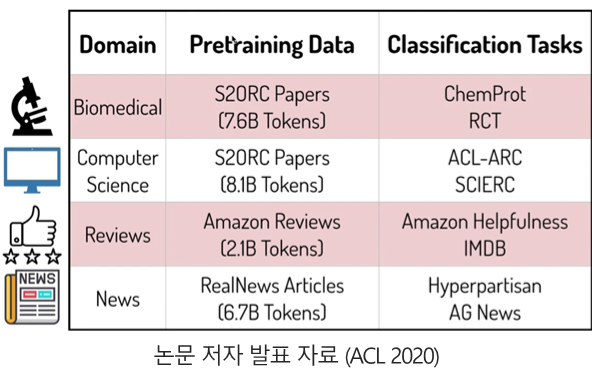
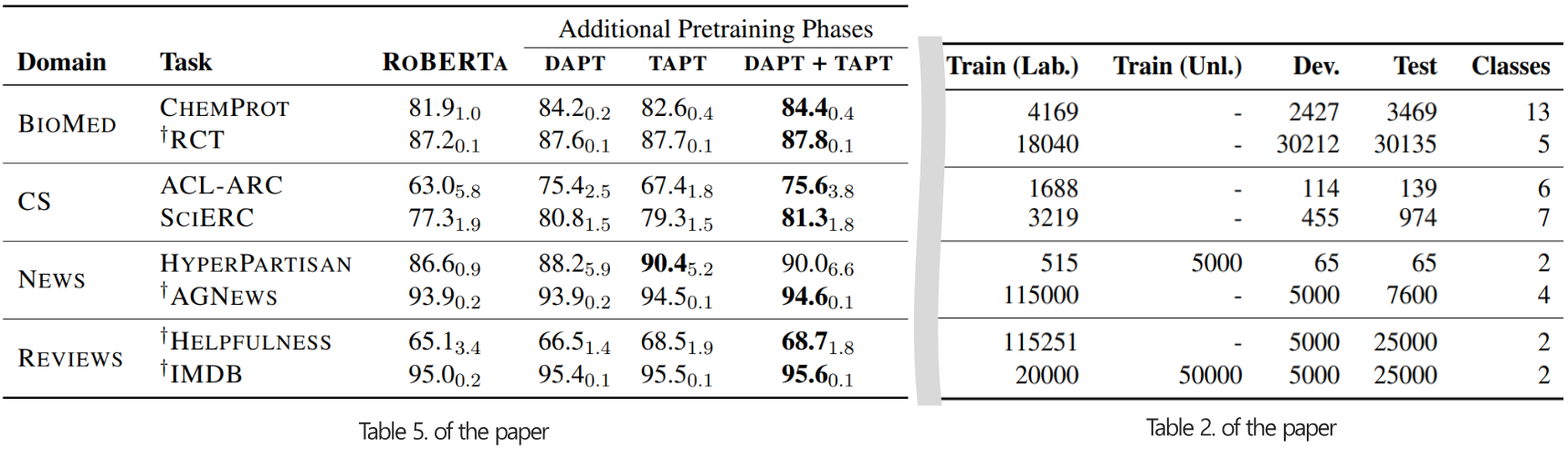
- 선행 연구에서 자주 다뤄지는 4개의 domain(biomedical papers, computer science papers, new text, AMAZONE review)을 선정했습니다.
- 성정된 domain에는 각각 2개씩 classification task가 존재합니다.
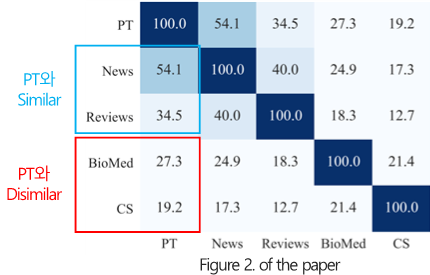
1. Analyzing Domain Similarity
- PT(RoBERTa의 corpus) 및 각 domain의 corpus에서 상위 10K 단어 기반 vocabulary overlap (%) 비교 분석을 통해 domain별 유사도를 평가합니다.
2. Experiments
Pretraining 성능 비교 (unsupervised MLM loss)
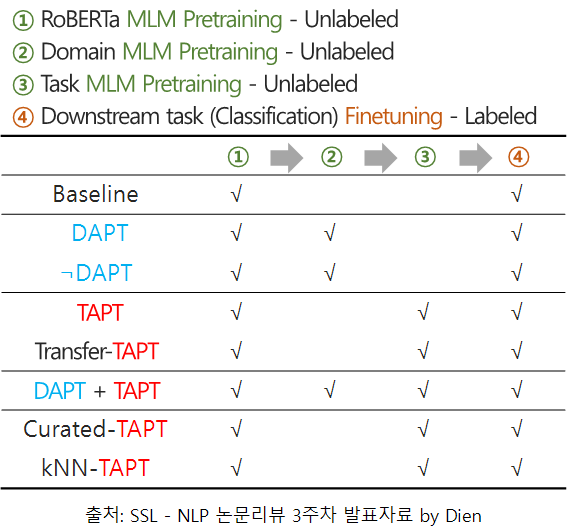
- (Baseline) RoBERTa pretraining 모델로 각 domain에 대한 MLM loss를 계산합니다.
- (DAPT) RoBERTa pretraining 모델을 초기 weight롤 설정하고, 각 domain corpus를 활용해 추가로 pretraining을 진행하여 MLM loss를 계산합니다.

- NEWS domain을 제외한 모든 domain에서 MLM loss가 감소한것을 알 수 있습니다.
- 특히, PT와 유사도가 낮은 BIOMED 및 CS domain에서 성능 향상이 높게 나타나는데 이는 domain 유사도가 낮을수록 DAPT의 잠재력이 높아짐을 시사합니다.
Downstream task 성능 비교 (supervised Finetuning classification F-score)
- (Baseline) RoBERTa pretraining 모델로 각 domain의 downstream task에 대한 classification finetuning을 진행합니다.
- (DAPT) 각 domain으로 추가 pretraining을 진행한 뒤에, classification finetuning을 진행합니다.
- (¬DAPT) 해당 task의 domain과 무관한(dissimilar) domain으로 추가 pretraining을 진행한 뒤에, classification finetuning을 진행합니다.
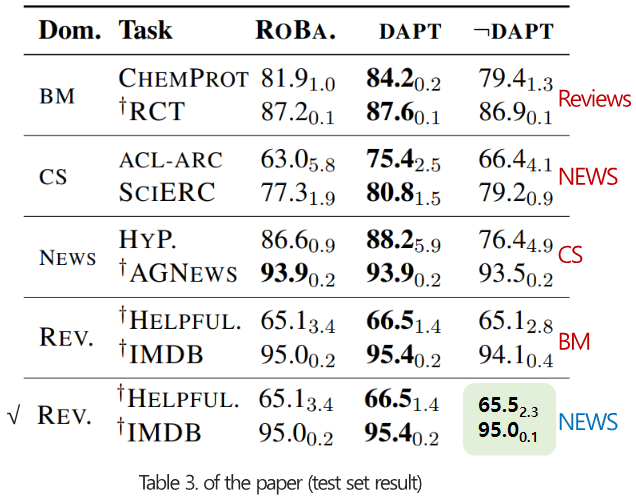
- DAPT가 Baseline보다 대부분의 경우에 좋은 성능을 나타냈습니다.
- MLM loss 변화에서 시사했던 것처럼 BM과 CS domain에서 효과가 가장 두드러졌습니다.
3. Domain Relevance for DAPT
- Target domain과 dissimilar한 domain으로 DAPT를 수행한 결과(¬DAPT), 오히려 baseline보다 성능이 떨어졌습니다.
- 이는 DAPT 수행시, 단순히 더 많은 데이터에 노출시키는 것이 아닌, domain-relevant가 중요하다는 것을 시사합니다.
- NEWS로 DAPT를 수행한 모델은 CS domain에서 Baseline보다 오히려 성능이 좋아졌는데, 이는 NEWS domain이 PT와 유사하기 때문이라고 추측됩니다.
(논문에는 없는 내용으로, 거꾸로 읽는 SSL-NLP의 3주차 발표 영상 by Dien에서 간단하게 논의되었습니다.)
4. Domain Overlap
- Domain간 유사도가 높다면, 다른 domain이라 할지라도 긍정적인 transfer 효과를 보일 수 있습니다.
- 위의 Table 3의 마지막 행에 유사도가 높은(40%) 두 domain에 대한 결과를 추가로 표시했습니다.
- NEWS로 DAPT를 수행한 모델은 REVIEW domain에서 비슷한 성능을 보였습니다.

Task-Adaptive Pretraining
1. Experiments
- (TAPT) 각 domain별 task corpus를 활용해 RoBERTa pretraining 모델에 추가 pretraining을 진행하고, 해당 task에 대한 classification finetuning을 진행합니다.
- (DAPT+TAPT) DAPT 모델에 task corpus를 활용해 추가 pretraining을 진행하고, 해당 task에 대한 classification finetuning을 진행합니다.
- DAPT보다 활용할 수 있는 데이터의 수가 적지만, task-specific하기 때문에 효율적일 것이라 기대합니다.
TAPT, Combined DAPT and TAPT
- Baseline 대비 TAPT가 모든 task에서 성능 개선을 보였습니다.
- DAPT 대비 적은 resource임에도 몇가지 task에서는 오히려 성능 개선을 보였습니다.
- CS에서는 DAPT 대비 꽤 감소하였는데 이는 low resource가 이유라고 추측됩니다.
- DAPT+TAPT는 비용측면에서 비싸지만, 가장 좋은 성능을 보였습니다.
Cross-Task Transfer
- (Transfer-TAPT) 같은 domain내에서 다른 task를 활용해 TAPT를 진행합니다.
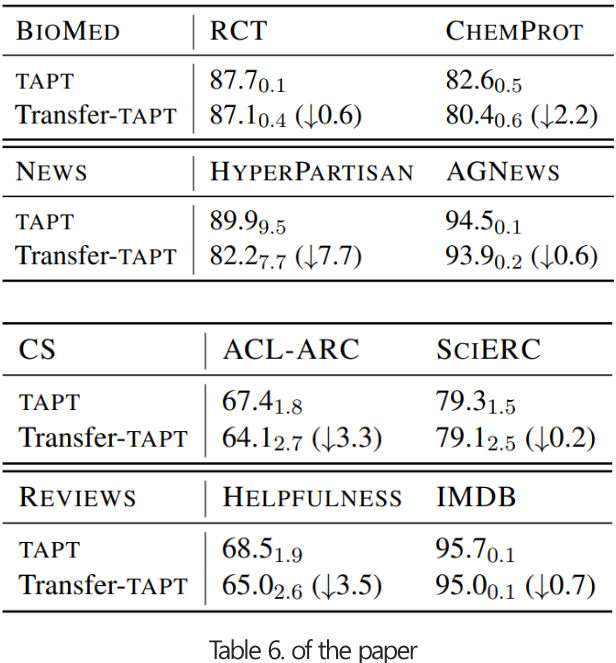
- 같은 domain이라 할지라도, task별로 데이터 분포가 다를 수 있음을 시사합니다.
Augmenting Training Data for Task-Adaptive Pretraining
- TAPT의 적은 resource 한계를 극복하기 위해 두가지 agumentation 방법을 제안합니다.
1. Human Curated-TAPT
- 사람이 직접 해당 domain내의 unlabeled corpus에서 task 관련 corpus를 curation(선별)하여 data augmentation을 진행합니다.
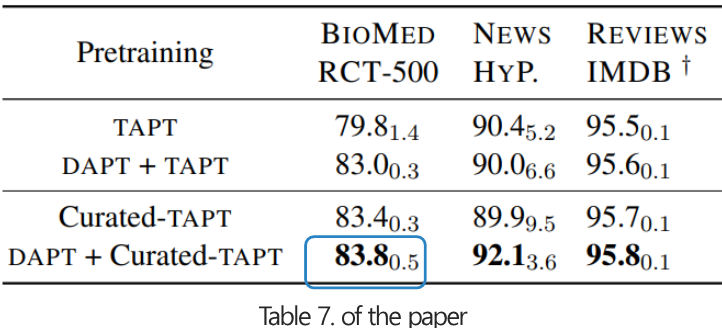
- Curated-TAPT를 추가한 것이 더 나은 성능을 보였습니다.
- 특히 파란색 상자 안의 결과를 살펴보면, 0.3% 수준의 데이터를 추가한 것 만으로 95% 수준(87.8 -> 83.8)의 성능을 보여주었습니다.
2. Automated Data Selection for TAPT
- Curated-TAPT의 경우 사람의 노력이 들어가는 resource가 발생합니다.
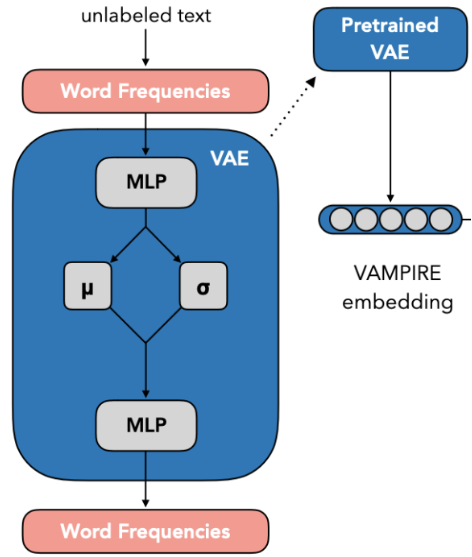
- 따라서, domain corpus 내에서 unsupervised 방식(VAMPIRE를 활용한 text embedding)으로 task distribution과 관련된 데이터를 샘플링하는 방법(kNN-TAPT)을 제안합니다.
- 합리적인 시간내에 모든 문장들을 embedding할 수 있을 정도로 가벼운 모델 필요
- VAMPIRE(VAriational Methods for Pretraining In Resource-limited Environments, Gururangan et al. "Variational pretraining for semi-supervised text classification." (2019))라는 unigram 단위 Bag-of-words language model 사용
- Text의 word frequencies를 input과 target으로 설정하여 VAE 학습
- 학습된 VAE의 encoder로 text embedding 진행
- Task와 domain corpus가 같은 공간에 embedding 될 수 있도록 함께 학습
- 학습된 text embedding 모델로 domain과 task corpus를 embedding하고, task corpus를 기준으로 가장 가까운 k개의 domain corpus를 sampling함
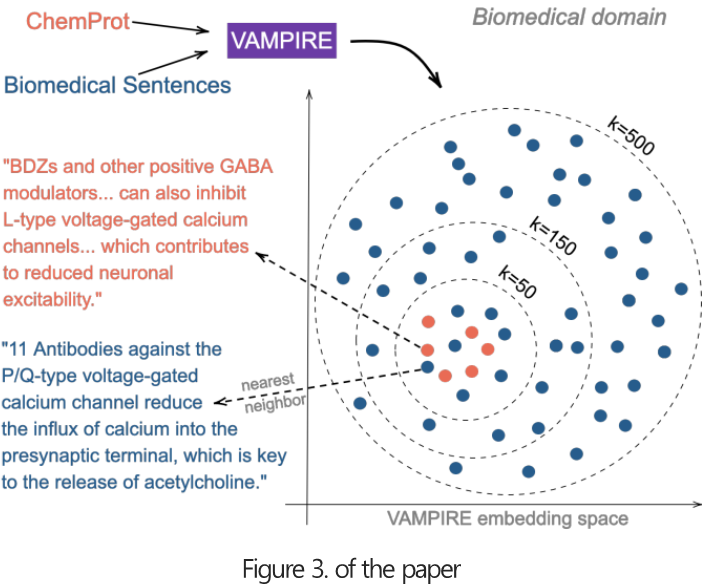
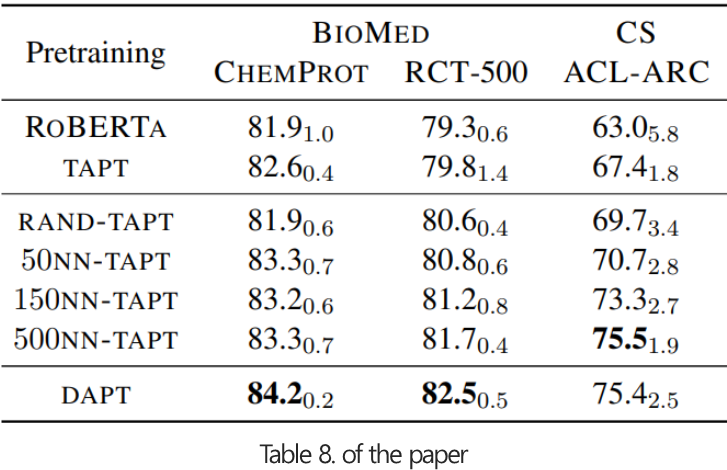
- kNN-TAPT가 모든 경우에서 TAPT 성능을 개선시킨것을 보여줍니다.
- k가 증가할수록 kNN-TAPT의 성능은 꾸준히 증가하여 DAPT에 근접하게 됩니다.
- 향후 kNN-TAPT에 대한 보다 정교한 데이터 선택 방법이 연구될 수 있습니다. (kNN-LMs, RETRO 등)
3. Computational Requirements
- BM domain의 RCT-500 task에서 실험을 진행했습니다.
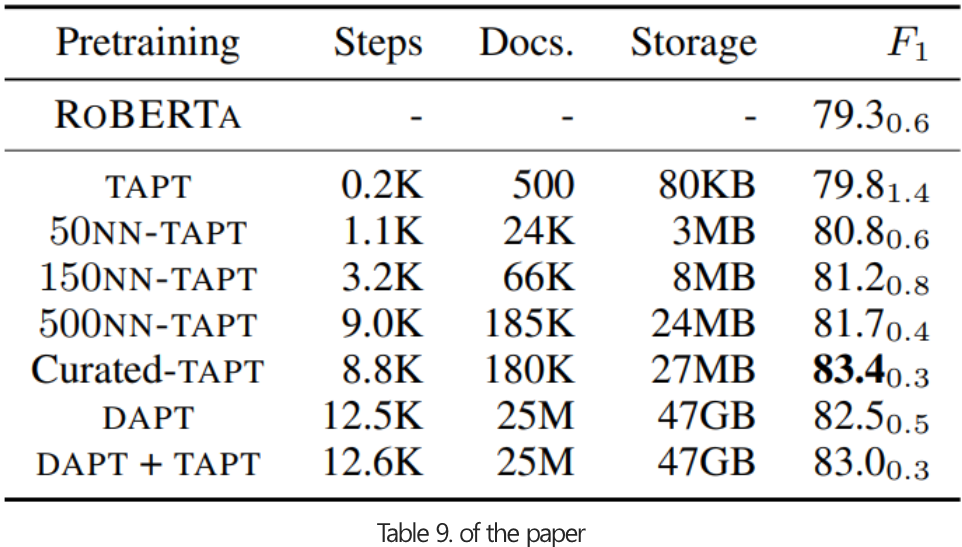
- DAPT를 활용하는 것이 좋은 성능을 보였지만, TAPT 대비 storage는 약 40배의 resource가 필요합니다.
- Curated-TAPT가 가장 좋은 성능을 보였지만, 사람이 직접 데이터를 선별해야하는 비용이 발생합니다.
- kNN-TAPT가 적은 resource대비 합리적인 성능을 보여주었습니다.
Conclusion
- 여러 실험 결과, Language model은 도메인 특성에 따른 complexity(복잡도)를 인코딩하는 것에 어려움이 존재합니다.
- 특정 domain 또는 task에 대해 모델을 추가 pretraining하면 성능을 향상시킬 수 있습니다.
- Language model을 고도화하기 위해, domain 및 task에 적합한 corpus를 추가 사용하는 것이 중요합니다.
🙆🏻♂️ 논문을 읽고 나서..
- 일반적으로 언어 모델을 가져와서 풀고자하는 task에 finetuning만 진행했었는데, 추가 pretraining 하는 것이 더 좋은 성능을 보일 수 있다는것을 알게 되었다.
- 발표영상에서 언급된 kNN-LMs 및 RETRO의 kNN을 활용한 document retriver 방법이 궁금하며, 추후 살펴볼 생각이다. 🤷🏻♂️
- 발표영상이 유튜브로 박제된다는 것이 무척 긴장되었는데, 역시 발표영상에 긴장된 모습이 고스란히 담긴 것 같아 아쉽다.. 🤦♂️😂
- 그래도 좋은 경험이였으며 많은 도움을 받았다. 앞으로 자주 이런 활동에 기여하며 발전하고 싶다는 생각을 했다. 💪
