Execution Plan(실행계획)
실행계획은 SQL Server 엔진이 쿼리를 어떻게 실행할지를 결정하고 설명한 "실행 시나리오"이다.
비유하자면, 옵티마이저는 대본을 쓰는 감독(혹은 작가), SQL Server 엔진은 그 대본을 따라 연기하는 배우이다.
구문분석 > 표준화 > 최적화 > 컴파일 > 실행
위 프로세스는 쿼리 처리 과정이다.
실행계획은 최적화 단계에서 통계, 조각정보 등을 바탕으로 만들어 지고 이때 만들어지는 플랜을 재사용을 위해 플랜 캐시하여, 실행계획은 실행계획과 실제 실행계획으로 구분된다.
예상 실행계획은 이전에 생성된 통계정보를 바탕으로 플랜을 구성하고, 실제 실행계획은 현재 상태의 통계정보를 바탕으로 플랜을 구성한다.
실행계획은 다음의 경우 기존의 실행계획을 사용하지 않고 새로운 실행계획을 생성한다.
- 쿼리에서 참조하는 테이블이나 뷰가 ALTER된 경우
- 단일 프로시저가 ALTER된 경우, 이 경우 해당 프로시저의 모든 계획이 캐시에서 삭제된다.
- 실행계획에 사용되는 인덱스가 변경, 삭제 된 경우
- UPDATE STATISTICS 등의 명령문에서 명시적으로 생성되거나 자동으로 생성되어 실행계획에 사용되는 통계가 업데이트 된 경우
- SP_RECOMPILE에 대한 명시적 호출이 있던 경우
UPDATE STATISTICS는 특정 테이블의 통계 정보를 업데이트 하는 것으로, 데이터베이스가 알맞은 인덱스를 선택하도록 관리하는 작업이다.
테이블 통계 자료는 데이터베이스 테이블과 관련된 정보를 분석하고 수집하는 것으로, 주로 SQL 성능 최적화에 활용된다.
이러한 정보는 데이터베이스 옵티마이저가 최적의 실행계획을 수립하는 데 사용되며, 데이터의 양, 테이블 구조, 인덱스 정보 등을 포함한다. 테이블 통계 자료가 부정확하거나 오래되면 쿼리 성능 저하의 원인이 될 수 있으므로 주기적인 갱신이 필요하다.
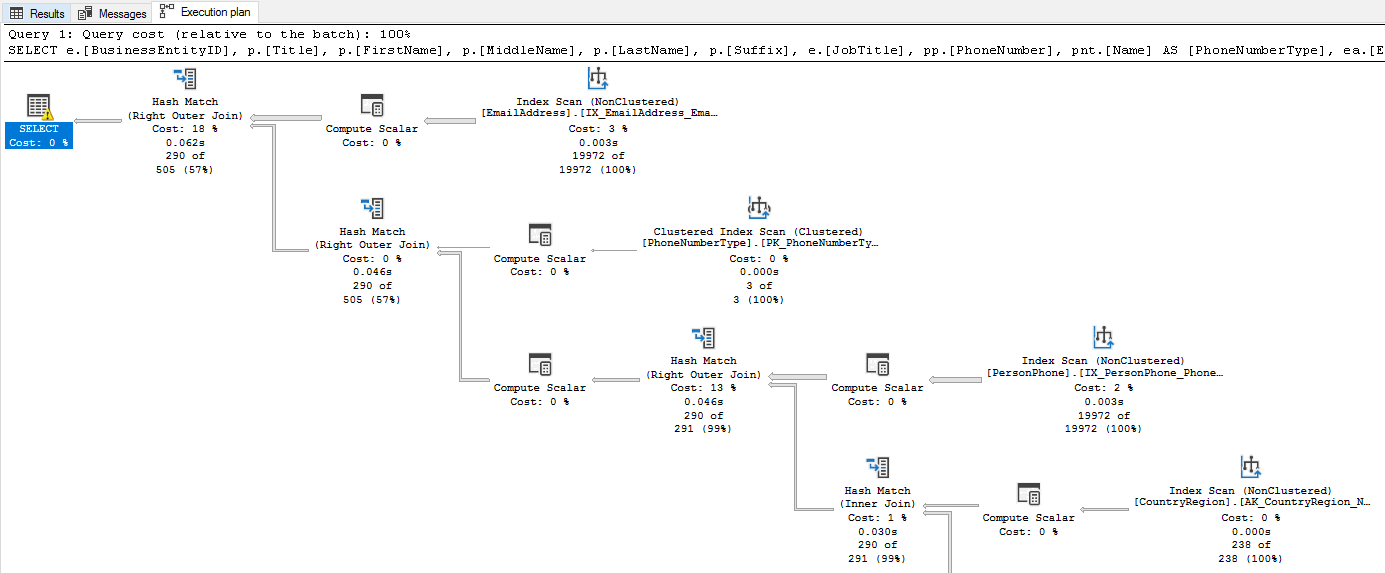
실행계획은 위에서 아래로, 오른쪽에서 왼쪽으로 확인한다.
이는 쿼리가 실행되는 순서이다.
실행계획의 노드를 선택하면 다음과 같은 속성을 확인 할 수 있다.
| 속성 | 설명 |
|---|---|
| Physical Operation | 논리 연산자의 지시에 따라 연산을 구현하는 연산자이다. 모든 물리 연산자는 일반적으로 작업을 수행하는 개체이다. Clustered Index Scan, Index Seek 등이 있다. |
| Logical Operation | 이 연산자는 쿼리를 처리하는 데 사용되는 실제 대수 연산을 설명한다. Right Anti, Semi Join, Hash Join 등이 있다. |
| Estimated Execution Mode | Actual Execution Mode와 유사하나 추정값을 보여준다. |
| Storage | 쿼리 최적화 프로그램이 쿼리에 의해 추출되는 결과를 저장하는 방법을 알려준다. |
| Estimated I/O Cost | 결과 집합의 입출력 작업 비용을 알려준다. |
| Estimated Number of Executions | Number of Executions와 유사하지만 추정 값이다. |
| Object | 작업이 수행되는 테이블을 나타낸다. |
| Estimated Number of Rows Per Execution | 옵티마이저가 연산자에 의해 반환될 것이라고 생각하는 행 수를 나타낸다. |
| Estimated Number of Rows to be Read | 옵티마이저가 운영자가 읽을 것이라고 생각하는 행 수를 나타낸다. |
| Estimated Number of Rows for All Executions | Number of Executions 와도 유사하지만 추정 값이다. |
| Estimated Row Size | 연산자의 각 행에 대한 저장 크기이다. |
| Estimated Rebinds | 반복 실행되는 연산자(EX) Nested Loops)의 외부 참조 값이 변경되어 다시 바인딩되는 예상 횟수를 나타낸다. Rebind는 루프의 각 반복마다 외부 값이 변경될 때 발생한다. |
| Estimated Rewinds | 외부 참조 값이 변경되지 않고 반복 실행될 때(즉, 재사용되는 경우)의 예상 횟수를 나타낸다. Nested Loops와 같은 연산자에서 내부 쿼리를 반복 실행할 때 발생한다. |
| Defined Values | 해당 연산자가 정의(생성)하는 컬럼이나 표현식 값을 보여준다. |
| Output List | 해당 연산자가 출력하는 컬럼 목록을 나타낸다. 이 정보는 상위 연산자에게 전달된다. |
| Parallel | 연산자가 병렬 실행계획의 일부인지 여부를 나타낸다. 병렬 실행이 가능하면 "True" 또는 병렬 스레드 수가 표시된다. |
| Ordered | 작업을 수행할 데이터 세트가 정렬된 상태인지 여부를 결정한다. |
| Forced Index | 인덱스 힌트 또는 옵티마이저 지시에 따라 강제로 사용된 인덱스를 나타낸다. 강제되지 않은 경우 비어있을 수도 있다. |
| Node ID | 오른쪽에서 왼쪽, 위에서 아래로 읽는 Execution Plan에서 오퍼레이터가 호출된 순서대로 번호를 자동 할당한다. |
| Table Cardinality | 테이블의 전체 행 수를 나타낸다. 쿼리 최적화 시 통계 기반으로 사용된다. |
| Force Scan | 옵티마이저가 인덱스 사용 대신 전체 테이블 또는 전체 인덱스 스캔을 강제하도록 설정되었는지를 나타낸다. |
| NoExpandHint | 뷰에 대해 NOEXPAND 힌트가 사용되어 뷰가 확정되지 않고 그대로 사용되었는지를 나타낸다. 인덱스가 뷰를 사용할 떄 유용하다. |
SQL Server 실행계획 연산자
옵티마이저가 실행계획을 결정할 때 사용하는 “물리적 연산(Physical Operation)”이다.
옵티마이저가 물리적 연산을 선택하는 기준
| 기준 | 설명 |
|---|---|
| 비용 기반 최적화 | CPU, I/O, 메모리 등 연산 비용을 계산해 총 비용이 가장 낮은 실행계획을 선택한다. |
| 통계 정보 | 데이터 분포, 행 수, 선택도(selectivity) 등을 참고해 효율적인 연산자를 판단한다. |
| 필터 조건(WHERE 절) | 조건절이 인덱스 키와 얼마나 일치하는지, 인덱스가 필터링에 얼마나 효과적인지 평가한다. |
| 커버링 인덱스 여부 | 인덱스가 쿼리에서 필요한 모든 컬럼을 포함하면 추가 조회 없이 인덱스만으로 작업이 가능해 비용이 절감된다. |
| 테이블 크기 | 작은 테이블일 경우, 인덱스 사용보다 전체 스캔이 더 빠를 수 있다. |
| 병렬 처리 가능성 | 병렬 처리로 작업이 빠르게 수행될 수 있는 연산자를 선택한다. |
| 메모리 및 시스템 부하 | 시스템 상태나 메모리 상황에 따라 실행계획을 달리 선택할 수 있다. |
| 힌트 및 옵션 | 사용자가 지정한 힌트가 있으면 옵티마이저가 이를 우선적으로 반영한다. |
물리적 연산자의 종류
테이블 스캔(Table Scan)
생성된 SQL 쿼리 실행계획에서 SQL Server 엔진이 데이터를 검색하기 위해 Table Scan 연산자를 사용하여 모든 전체 테이블 행을 스캔한다는 것을 의미한다.
SQL Server 엔진은 WHERE 절을 추가하여 특정 레코드 집합을 가져오려고 할 때 해당 테이블에 생성된 인덱스가 없으면 Table Scan 연산자를 사용하여 모든 전체 테이블 행을 스캔한다.
옵티마이저는 이미 캐시에 실행계획이 있다면 그 계획을 그대로 사용한다.
만약 캐시에 실행계획이 없다면 옵티마이저가 새 계획을 만드는데,
아래와 같은 경우 인덱스를 사용하지 않고 테이블 스캔을 선택할 수 있다.
- 인덱스가 유용하지 않은 경우
인덱스가 있어도 선택도(필터링 효과)가 낮은 경우이다. - 테이블에 적은 수의 행이 포함된 경우
테이블 자체가 작아서 인덱스를 타는 것보다 그냥 한 번에 다 읽는 게 더 빠르다. - 쿼리가 대부분의 행을 반환하는 경우
인덱스를 통해 조건을 걸더라도 어차피 대부분의 데이터를 읽어야 한다면, 여러 번 랜덤 I/O를 하는 인덱스 탐색보다 한 번에 쭉 읽는 테이블 스캔이 더 빠르다.
| 용어 | 설명 |
|---|---|
| 클러스터형 인덱스 스캔 (Clustered Index Scan) | 클러스터형 인덱스를 처음부터 끝까지 쭉 읽음 → 조건 없이 전체 읽기거나, 조건이 인덱스 필터로 적합하지 않을 때 |
| 클러스터형 인덱스 검색 (Clustered Index Seek) | 클러스터형 인덱스를 조건에 따라 빠르게 탐색 → 주로 기본키나 조건절이 인덱스 키와 일치할 때 |
| 비클러스터형 인덱스 스캔 (Nonclustered Index Scan) | 비클러스터 인덱스를 처음부터 끝까지 순차적으로 스캔 → 부분적으로 조건을 거는 경우, 또는 커버링 쿼리 |
| 비클러스터형 인덱스 검색 (Nonclustered Index Seek) | 비클러스터 인덱스를 통해 조건에 맞는 데이터 위치를 빠르게 찾음 |
| RID 조회 (RID Lookup) | 비클러스터형 인덱스로 찾은 행이 Heap(클러스터 인덱스 없는 테이블)에 있을 때, 해당 Row ID를 사용해 본문 데이터를 조회 |
| 키 조회 (Key Lookup) | 비클러스터형 인덱스로는 찾을 수 없는 나머지 컬럼을 클러스터형 인덱스를 통해 추가 조회하는 연산 → 주 테이블로부터 나머지 정보 읽기 (Bookmark Lookup이라고도 불림) |
SQL Server Architecture
MSSQL은 기본적으로 클라이언트-서버 아키텍처이다.
MSSQL의 프로세스는 클라이언트 Application이 Request를 보내는 것으로 시작된다.
이 요청은 MSSQL과 Client 간에 연결된 네티워크 인터페이스를 통해 들어온다.
SQL Server는 처리된 데이터를 가지고 Acceptance, Processing, Reponse한다.
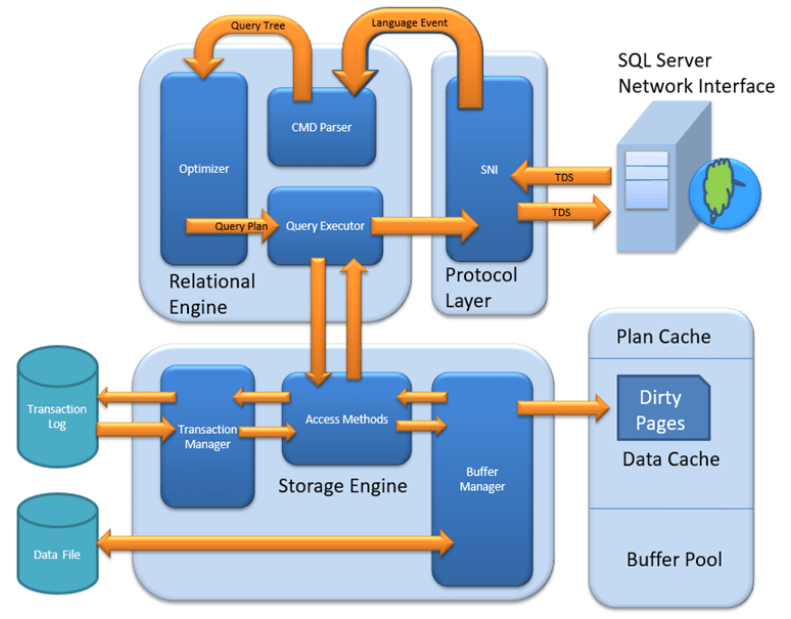
SQL Server Architecture Diagram
SQL Server의 다이어그램은 크게 3가지의 주요 모듈로 이루어져있다.
프로토콜 계층 - SNI
MSSQL Server 프로토콜 계층은 3가지 유형의 클라이언트 서버 아키텍처를 지원한다.
- 공유 메모리(Shared Memory)
클라이언트와 MSSQL Server는 동일한 시스템에서 실행된다. 둘 다 공유 메모리 프로토콜을 통해 통신할 수 있다.
로컬 개발 또는 테스트 개발에서 사용한다. - TCP/IP
클라이언트와 MSSQL 서버는 원격이며 별도의 시스템에 설치된다.
가장 일반적이고 보편적인 통신 프로토콜이다. - Named Pipe
클라이언트와 MSSQL Server는 LAN을 통해 연결된다.
Named Pipe에서 구성 및 설치데스크 옵션이 기본적으로 비활성화되어 있으며, SQL 구성 관리자에서 활성화해야 된다. 클라리언트와 서버가 동일한 LAN에 있을 때 사용되며, TCP 445 포트를 사용한다. TCP/IP 프로토콜이 없는 환경에서는 사용할 수 없다. - TDS
TDS는 테이블 형식의 데이터 스트림을 나타낸다.
3가지 프로토콜 모두 TDS 패킷을 사용한다. TDS는 네트워크 패킷에 캡슐화된다. 이를 통해 클라리언트 컴퓨터에서 서버 컴퓨터로 데이터를 전송할 수 있다.
관계형 엔진(Relational Engine)
관계형 엔진은 Query Processor라고도 불린다.
사용자가 작성한 SQL 쿼리를 분석, 최적화, 실행 계획 생성 및 실행 요청하는 역할을 한다.
쿼리가 수행해야 할 작업이 무엇인지 파악하고, 이를 가장 효율적으로 수행할 수 있는 방법(실행계획)을 결정하는 SQL Server의 핵심 구성 요소이다.
- CMD Parser
프로토콜 계층에서 수신된 데이터는 관계형 엔진으로 전달된다. CMD Parser는 쿼리 데이터를 수신하는 관계형 엔진의 첫 번째 구성요소이다. CMD Parser의 주요 작업은 구문 및 의미 오류에 대한 쿼리를 확인하는 것이다. 그리고는 쿼리 트리를 생성한다.
구문검사
다른 프로그래밍 언어와 마찬가지로 MSSQL에는 사전 정의된 키워드 세트가 있다. 또한 SQL Server에는 SQL Server가 이해하는 자체 문법이 있다.
SELECT, INSERT, UPDATE 및 기타 다수의 문법은 MSSQL 사전 정의 키워드 목록에 속한다.
CMD Parser는 구문 검사를 수행하고 사용자 입력이 언어 구문이나 문법 규칙을 따르지 않으면 오류를 반환한다.
의미검사
의미검사는 Normalizer에 의해 수행된다.
가장 간단한 형태로 조회 중인 Column명, Table명이 Schema에 존재하는지 확인한다. 존재하는 경우 쿼리에 Binding한다.
사용자 쿼리에 View가 포함되면 복잡성이 증가한다. Normalizer는 내부적으로 저장된 뷰 정의 등으로 대체를 수행한다.
쿼리 트리 생성
쿼리를 실행할 수 있는 다른 실행 트리를 생성하는 단계이다.
다른 모든 트리는 동일의 원하는 출력을 가진다.
- Optimizer
최적화 프로그램의 작업은 사용자 쿼리에 대한 실행 또는 계획을 만드는 것이다.
쿼리 비용은 CPU 사용량, 메모리 사용량 및 입출력 요구와 같은 조건을 기반으로 계산된다.
MSSQL 옵티마이저는 내장된 Exhaustive/Heuristic 알고리즘에서 작동한다. 목표는 쿼리 시간을 최적화하는 것이다.
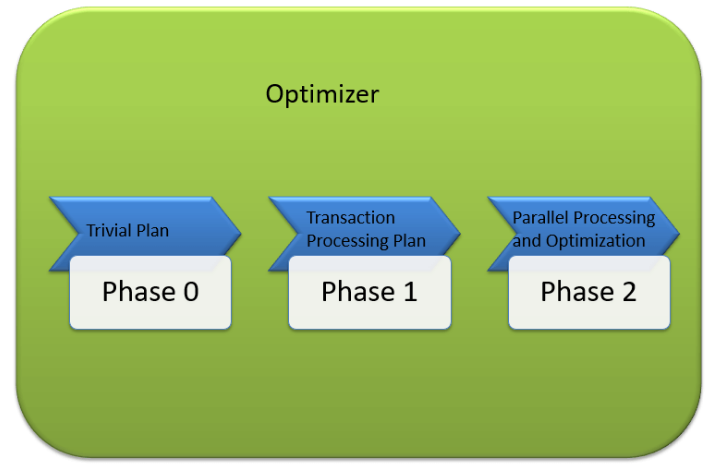
Phase0 - 일반적인 계획 탐색
사전 최적화 단계라고도 한다.
어떤 경우에는 일반적인 계획으로 알려진 실행 가능한 계획이 하나만 있을 수도 있다.
그 이유는 더 많이 검색하면 동일한 런타임 실행 계획을 찾을 수 있기 때문이다.
전혀 필요하지 않은 최적화된 계획을 찾는데 추가 비용이 발생하기 때문에 최적화된 계획을 만들 필요가 없다.
어떠한 계획도 찾을 수 없는 경우 Phase1이 시작된다.
Phase1 - 트랜잭션 처리 탐색 계획
여기에는 단순 및 복합 계획 검색이 포함된다.
단순 계획 검색 - 쿼리에 관련된 컬럼 및 인덱스의 과거 데이터를 통계 분석에 사용한다. 이는 보통 테이블당 하나의 인덱스로 구성되지만 이에 제한되지는 않는다.
그래도 단순 계획이 없으면 더 복잡한 계획이 검색된다. 테이블당 다중 인덱스를 포함한다.
Phase2 - 병렬 처리 및 최적화
위의 전략 중 어느 것도 작동하지 않으면 옵티마이저는 병렬 처리 가능성을 검색한다. 이것은 기계의 처리 능력과 구성에 따라 다르다.
그래도 가능하지 않으면 최종 최적화 단계가 시작된다. 최종 최적화 목표는 최상의 방법으로 쿼리를 실행하기 위해 가능한 다르 모든 옵션을 찾는 것이다. 최종 최적화 단계의 알고리즘은 MicroSoft 소유이다.
- 쿼리 실행기(Query Executor)
옵티마이저가 생성한 실행계획을 이용하여 단계별로 쿼리를 실행하는 부분이다.
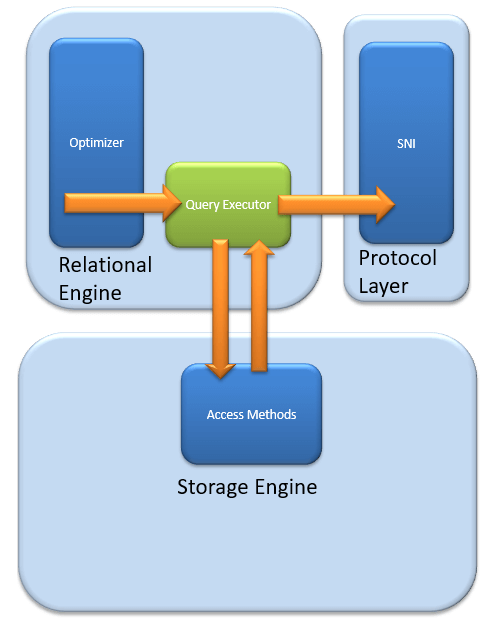
쿼리 실행자는 액세스 방법을 호출한다. 실행에 필요한 SELECT 로직에 대한 실행 계획을 제공한다. Storage Engine에서 데이터를 수신하면 결과가 프로토콜 계층에 게시된다.
Storage Engine
스토리지 엔진의 작업은 디스크 또는 SAN과 같은 스토리지 시스템에 데이터를 저장하고 필요할 때 데이터를 검색하는 것이다.
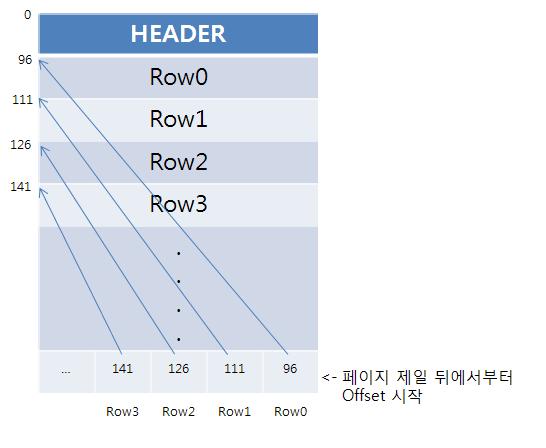
데이터 파일은 물리적으로 데이터 페이지의 형태로 데이터를 저장하며 각 데이터 페이지 크기는 8KB이다. SQL Serever에서 가장 작은 저장 단위를 형성한다. 이러한 데이터 페이지는 논리적으로 그룹화되어 익스텐트를 형성한다. (페이지 8개가 모여 1개의 익스텐트를 만든다.)
페이지에는 페이지 유형, 페이지 번호, 사용된 공간 크기, 여유 공간 크기 및 다음 페이지 및 이전 페이지에 대한 포인터와, 같은 페이지에 대한 데이터 정보를 전달하는 96Byte 크기의 페이지 헤더라는 섹션 등이 있다.
-
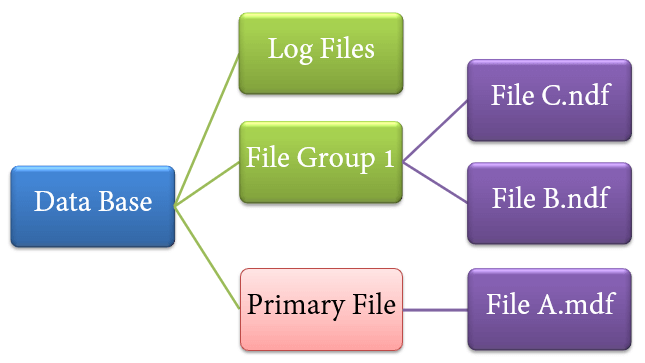
기본파일
모든 데이터베이스에는 하나의 기본 파일이 있다.
테이블, 뷰, 트리거 등과 관련된 모든 중요한 데이터를 저장한다.
확장자 - .mdf -
보조파일
데이터베이스는 여러 개의 보조 파일을 포함할 수 있고 포함하지 않을 수도 있다.
선택사항이며 사용자별 데이터를 포함한다.
확장자 - .ndf -
로그파일
미리 스기 로그라고도 한다.
트랜잭션 관리에 사용된다.
원치 않는 인스턴스에서 복구하는데 사용된다. 커밋되지 않은 트랜잭션으로 롤백하는 중요한 작업을 수행한다.
확장자 - .ldf
