인덱스 구조 및 탐색
테이블에서 데이터를 찾는 방법은 Table Full Scan과 Index를 사용하는 두 가지의 방법이 있다.
인덱스 탐색 과정은 수직적 탐색과 수평적 탐색, 두 단계로 이루어진다.
- 수직적 탐색 : 인덱스 스캔 시작지점을 찾는 과정
- 수평적 탐색 : 데이터를 찾는 과정
만약 유저 테이블에서 특정 유저를 직접 찾는다면 이름순으로 정렬된 상태에서 데이터를 찾는 것이 빠를 것이다. 이것이 "인덱스"이다.
인덱스는 큰 테이블에서 소량 데이터를 검색할 때 사용된다. 온라인 트랜잭션 처리(OLTP) 시스템에서는 소량 데이터를 주로 검색하므로 인덱스 튜닝이 중요하다.
인덱스 튜닝의 두 번째 핵심 요소는 테이블 액세스 횟수를 줄이는 것이다. 인덱스 스캔 후 테이블 레코드를 액세스할 때 랜덤 I/O 방식을 사용하므로 이를 "랜덤 액세스 최소화 튜닝"이라고 한다.
유저 테이블에서 주소가 '서울'이고 이름이 'KGJ'인 사용자를 찾는다고 하자.
전체 유저 중 서울에 사는 사람은 약 10만 명이지만, 이름이 'KGJ'인 사람은 30명밖에 없다.
이 경우 이름 컬럼에 인덱스를 사용하는 것이 훨씬 효율적이다.
이름이 'KGJ'인 유저 30명만 먼저 조회한 후, 그 중에서 주소가 '서울'인지만 확인하면 되기 때문이다.
반면 주소에 인덱스를 사용하면 10만 건을 먼저 읽고 다시 이름 조건을 확인해야 한다.
인덱스 구조
DBMS는 일반적으로 BTree 인덱스를 사용한다.
BTree는 트리 형태로, Root가 위쪽에 있고, Branch를 거쳐 맨 아래에 Leaf가 있다.
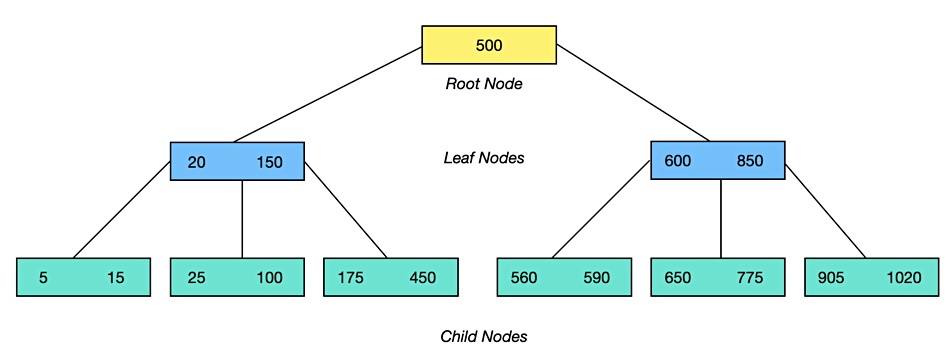
Root와 Branch 블록에 있는 레코든즌 하위 블록에 대한 주소값을 갖는다. 키값은 하위 블록에 저장된 키값의 범위를 나타낸다.
예를 들어, "500" 레코드가 가리키는 하위 블록에는 "500"보다 크거나 같은 레코드가 저장돼 있다는 뜻이다.
Leaf 블록에 저장된 각 레코드는 키값 순으로 정렬돼 있을 뿐만 아니라 테이블 레코드를 가리키는 주소값, 즉 ROWID를 갖는다. 인덱스 키값이 같으면 ROWID 순으로 정렬된다. 인덱스를 스캔하는 이유는, 검색 조건을 만족하는 소량의 데이터를 빨리 찾고 거기서 ROWID를 얻기 위해서다.
ROWID가 갖는 테이블 블록 주소(Data Block Address)
- ROWID : 데이터 블록 주소 + 로우 번호
- 데이터 블록 주소 : 데이터 파일 번호 + 블록 번호
- 블록 번호 : 데이터파일 내에서 부여한 상대적 순번
- 로우 번호 : 블록 내 순번
인덱스 수직적 탐색
정렬된 인덱스 레코드 중 조건을 만족하는 첫 번째 레코드를 찾는 과정이다. 즉, 인덱스 스캔 시작지점을 찾는 과정이다.
인덱스 수직적 탐색은 Root 블록에서부터 시작된다. 루트를 포함해 Branch 블록에 저장된 각 인덱스 레코드는 하위 블록에 대한 주소값을 갖기 떄문에 루트에서 시작해 리프블록까지 수직점 탐색이 가능하다.
인덱스 수평적 탐색
수직적 탐색을 통해 스캔 시작점을 찾았다면, 찾고자 하는 데이터가 더 안 나타날 때까지 인덱스 리프 블록을 수평적으로 스캔한다. 인덱스가 본격적으로 데이터를 찾는 과정이다.
인덱스 리프 블록끼리는 서로 옆의 블록에 대한 주소값을 갖는다. 즉, Double Linked List 구조다. 좌에서 우로, 우에서 좌로 수평적 탐색이 가능한 이유다.
인덱스를 수평적으로 탐색하는 이유는 다음과 같다.
1. 조건절에 만족하는 데이터를 모두 찾기 위해서이다.
2. ROWID를 얻기 위해서이다.
조회하고 싶은 컬럼을 모든 인덱스가 모두 갖고 있어 인덱스만 스캔하고 끝나는 경우도 있지만, 일반적으로 인덱스를 스캔하고서 테이블도 액세스한다. 이때 ROWID가 필요하다.
테이블을 액세스 한다는 것은, 인덱스만으로는 원하는 데이터를 다 가져올 수 없기 때문에, 실제 테이블까지 가서 데이터를 더 읽어야 한다는 뜻이다.
결합 인덱스 구조와 탐색
두 개 이상의 컬럼을 결합해서 인덱스를 만들 수도 있다.
예를 들어, 성별 이름으로 인덱스를 만든다면 Male & Kim라는 레코드가 생성된다.
주목할 것은, 인덱스를 "성별 & 이름"으로 구성하는 것과 "이름 & 성별"로 구성하는 것은 읽는 블록 개수가 똑같기 때문에 성능이 같다.
비교 연산 횟수가 줄어드는 건 사실이지만 성능에서 차이는 없다.
애매하네 이건
Balanced?
DELETE 작업 떄문에 인덱스가 UnBalanced 상태에 놓일 수 있다고 설명하는 자료들이 있다.
하지만, BTree 인덱스에서 이런 현상은 절대 발생하지 않는다. BTree의 "B"가 "Balanced"의 약자임을 기억하자.
인덱스 기본 사용법
데이터베이스에서는 인덱스 컬럼을 가공하지 않아야 인덱스를 정상적으로 사용할 수 있다.
인덱스를 정상적으로 사용한다는 표현은 리프 블록에서 스캔 시작점을 찾아 거기서부터 중간에 멈추는 것을 의미한다.
즉, 리프 블록 일부만 스캔하는 Index Range Scan을 의미한다.
인덱스 컬럼을 가공 하더라도 인덱스를 사용할 수는 있지만, 스캔 시작점을 찾을 수 없고 멈출 수도 없어 리프 블록 전체를 스캔해야된다.(Index Full Scan)
인덱스를 Range Scan 할 수 없는 이유
인덱스를 가공하면 인덱스를 정상적으로 사용할 수 없다라는 것은 기본 중에 기본이다.
Index Range Scan에서 "Range"는 "범위"를 의미한다. Range Scan은 인덱수에서 일정 범위를 스캔한다는 뜻이다. 일정 범위를 스캔하기 위해서는 "시작지점"과 "끝지점"이 명확하게 있어야 된다.
인덱스를 Range Scan하기 위한 가장 첫 번째 조건은 인덱스 선두 컬럼이 조건절에 있어야 된다.
인덱스 선두 컬럼이 가공되지 않은 상태로 조건절에 있으면 인덱스 Range Scan이 무조건 가능하다는 것이다.
EX)
SELECT ~
FROM TableName AS A
WHERE A.TeamCd = '003'
AND (범위, OR, ISNULL 등)해당 쿼리에서 두번째 WHERE에 범위, OR, ISNULL의 함수가 사용되더라도 선두 컬럼인 TeamCd에 "="를 사용했기 때문에 Range Scan이 가능한 것이다.
하지만, 인덱스 Range Scan 한다고 해서 항상 성능이 좋은 것은 아니다.
인덱스를 정말 잘 타는지는 리프 블록에서 스캔하는 양을 따져봐야 알 수 있다.
ORDER BY 절에서 컬럼 가공
조건절이 아닌 ORDER BY 또는 SELECT-LIST에서 컬럼을 가공함으로 인해 인덱스를 정상적으로 사용할 수 없는 경우도 종종 있다.
PK가 "상품번호 & 생성날짜"로 이루어졌다고 가정했을 떄, 상품번호가 같은 레코드는 생성날짜를 기준으로 정렬돼있다. 그래서 상품번호에 "="조건으로 검색할 때 PK 인덱스를 사용하면 결과집합은 생성날짜 순으로 출력된다.
옵티마이저는 이러한 속성을 활용해 SQL에 "ORDER BY 상품번호, 생성날짜"가 있어도 정렬 연산을 따로 수행하지 않는다.
그런데 만약, "ORDER BY 상품번호 || 생성날짜"로 작성했다면 정렬 연산을 생략할 수 없다. 가공하지 않은 상태로 값을 저장했지만 가공한 값 기준으로 정렬을 요청했기 때문이다.
자동 형변환
코드값으로 데이터를 조회하는 쿼리를 보자.
SELECT TeamCd, TeamNm
FROM Team AS A
WHERE A.TeamCd = 123해당 쿼리에서는 조건절에 컬럼을 가공하지 않았는데도 Table Full Scan을 선택한다.
그 이유는, 옵티마이저가 해당 쿼리를 아래와 같이 변환했기 때문이다.
SELECT TeamCd, TeamNm
FROM Team AS A
WHERE TO_NUMBER(A.TeamCd) = 123각 조건절에서 양쪽 값의 데이터 타입이 서로 다르면 값을 비교할 수 없다.
인덱스 확장기능 사용법
Index Range Scan
Index Range Scan은 B*Tree 인덱스의 가장 일반적이고 정상적인 형태의 액세스 방식이다.
인덱스 Root에서 Leaf 블록까지 수직적으로 탐색한 후에 필요한 Range만 스캔한다.
인덱스를 Range Scan하려면 선두 컬럼을 가공하지 않은 상태로 조건절에 사용해야 된다.
성능은 인덱스 스캔 범위와 테이블 액세스 횟수를 얼마나 줄일 수 있느냐로 결정된다.
Index Full Scan
수직적 탐색 없이 인덱스 Leaf 블록을 처음부터 끝까지 수평적으로 탐색하는 방식이다.
데이터 탐색을 위한 최적의 인덱스가 없을 때 차선으로 선택된다.
인덱스 선두 컬럼이 조건절에 없으면 옵티마이저는 먼저 Table Full Scan을 고려한다.
만약 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 아주 일부만 테이블을 액세스 하는 상황이라면, 면적이 큰 테이블보다 인덱스를 스캔하는 쪽이 유리하다. 그럴 때 옵티망지ㅓ는 Index Full Scan 방식을 선택한다.
하지만 대부분의 데이터가 조건을 만족하는 상황에서 Index Full Scan을 선택하면, 거의 모든 레코드에 대해 테이블 액세서가 발생하므로 Table Full Scan보다 오히려 효율적이지 못하다.
SELECT /*+ first_rows */ *FIRST_ROWS 힌트는 전체 결과보다 처음 몇 행을 빠르게 보여주는 것이 목표이다.
그래서 옵티마이저는 정렬을 피하고, 인덱스를 이용한 빠른 접근 방식(Index Full Scan 등)을 선택할 수 있다.
이런 상황에서 인덱스만으로 원하는 순서가 맞춰진다면, 불필요한 정렬 없이 바로 앞부분 데이터만 읽게 돼서 성능이 크게 좋아질 수 있다.
주의할 점은, 사용자가 처음 의도와 달리 Fetch를 멈추지 않고 데이터를 끝까지 읽는다면 Table Full Scan보다 훨씬 더 많은 I/O를 일으키고 결과적으로 수행 속도도 훨씬 더 느려진다.
Index Unique Scan
Index Unique Scan은 수직적 탐색만으로 데이터를 찾는 스캔 방식으로, Unique 인덱스를 "=" 조건으로 탐색하는 경우에 작동한다.
Unique 인덱스가 존재하는 컬럼은 중복 값이 입력되지 않게 DBMS가 데이터 정합성을 관리해준다.
따라서 해당 인덱스 키 컬럼을 모두 "=" 조건으로 검색할 때는 데이터를 한 건 찾는 순간 더 이상 탐색할 필요가 없다.
Unique 인덱스라도 범위검색 조건으로 검색할 때는 Index Range Scan으로 처리된다.
