인덱스 스캔 효율화
인덱스 탐색
인덱스 스캔 효율화 튜닝을 이해하려면 인덱스 수직적 탐색, 수평적 탐색을 깊이있게 이해해야된다.
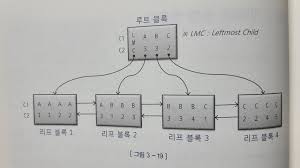
LMC(Leftmost Child)는 루트 블록에서 키 값을 갖지 않는 특별한 레코드이다.
LMC는 자식 노드 중 가장 왼쪽 끝에 위치한 블록을 가리킨다.
LMC가 가리키는 주소로 찾아간 블록에는 키값을 가진 첫번째 레코드보다 작거나 같은 값을 갖는 레코드가 저장돼 있다.
만약 해당 그림에서 WHERE C1 = 'B'의 조건으로 검색한다면 루트 블록 스캔 과정에서 레코드를 찾을 때 그것이 가리키는 리프 블록3으로 내려가면 안된다. 그 직전 C1='A' 레코드가 가리키는 리프 블록 2로 내려가야 된다.
수직적 탐색은 스캔 시작점을 찾는 과정이다.
액세스 조건 & 필터 조건
인덱스를 스캔하는 단계에 처리하는 조건절은 액세스 조건과 필터 조건으로 나뉜다.
액세스 조건
인덱스 스캔 범위를 결정하는 조건절이다.
인덱스 수직적 탐색을 통해 스캔 시작점을 결정하는 데 영향을 미치고, 인덱스 리프 블록을 스캔하다가 어디서 멈출지를 결정하는 데 영향을 미치는 조건절이다.
필터 조건
테이블로 액세스할지를 결정하는 조건절이다.
인덱스로 구성되지 않은 컬럼
인덱스를 이용하든, 테이블을 Full Scan하든, 테이블 액세스 단계에서 처리되는 조건절은 모두 필터 조건이다. 테이블 필터 조건은 쿼리 수행 다음 단계로 전달하거나 최종 결과 집합에 포함할지를 결정한다.
옵티마이저의 비용 계산
비용 = 수직적 탐색 비용 + 수평적 탐색 비용 + 테이블 랜덤 액세스 비용
(= 루트와 브랙치 레벨에서 읽는 블록 수 + 리프 블록을 스캔하는 과정에 읽는 블록 수 + 테이블 액세스 과정에 읽는 블록 수)
비교 연산자 종류와 컬럼 순서에 따른 군집성
테이블과 달리 인덱스에는 같은 값을 갖는 레코드들이 서로 군집해있다.
인덱스 컬럼을 앞쪽부터 누락없이 = 연산자로 조회하면 조건절을 만족하는 레코드는 모두 모여있다.
하지만, 어느 하나를 누락하거나 = 조건이 아닌 연산자로 조회하면 조건절을 만족하는 레코드가 서로 흩어진 상태가 된다.
선행 컬럼이 모두 = 조건인 상태에서 첫 번째 나타나는 범위검색 조건까지만 만족하는 인덱스 레코드는 모두 연속해서 모여있지만, 그 이하 조건까지 만족하는 레코드는 비교 연산자 종류에 상관없이 흩어진다. (우연히 모여있을 수는 있다.)
조건 EX) WHERE C1 = 1 AND C2 = 2 AND C3 = '나' AND C4 = 4만약 C3이 '다' 이상인 값이 없다면 모여있고, 그게 아니라면 흩어져 있을 것이다.
조건절
1) WHERE C1 = 1 AND C2 = 'A' AND C3 = '나' AND C4 = 'A'2) WHERE C1 = 1 AND C2 = 'A' AND C3 = '나' AND C4 >= 'A'3) WHERE C1 = 1 AND C2 = 'A' AND C3 BETWEEN '가' AND '다' AND C4 = 'A'4) WHERE C1 = 1 AND C2 <= 'A' AND C3 = '나' AND C4 BETWEEN 'A' AND 'B'5) WHERE C1 BETWEEN 1 AND 3 AND C2 <= 'A' AND C3 = '나' AND C4 = 'A'| 액세스 조건 | 필터 조건 | |
|---|---|---|
| 조건절 1 | C1, C2, C3, C4 | |
| 조건절 2 | C1, C2, C3, C4 | |
| 조건절 3 | C1, C2, C3 | C4 |
| 조건절 4 | C1, C2 | C3, C4 |
| 조건절 5 | C1 | C2, C3, C4 |
인덱스 선행 컬럼이 = 조건이 아닐 때 생기는 비효율
인덱스 스캔 효율성은 인덱스 컬럼을 조건절에 모두 = 조건으로 사용할 때 가장 좋다.
리프블록을 스캔하면서 읽는 레코드는 하나도 걸러지지 않고 모두 테이블 액세스로 이어지므로 인덱스 스캔 단계에서의 비효율은 전혀 없다.
인덱스 컬럼 중 일부가 조건절에 사용되지 않거나 = 조건이 아니더라도, 그것이 뒤쪽 컬럼일 때는 비효율이 없다.
만약, 지금 A, B, C, D 인덱스에서 A, B, C는 = 를 사용하고 D를 BETWEEN을 사용한다면 적은 횟수의 스캔을 하지만, D가 선두컬럼이였다면 얘기가 달라질 것이다.
인덱스 선행 컬럼이 모두 = 조건일 때 필요한 범위만 스캔하고 멈출 수 있는 것은, 조건을 만족하는 레코드가 모두 한데 모여있기 때문이다.
BETWEEN을 IN-List로 전환
범위검색 컬럼이 맨 뒤로 가도록 인덱스를 변경하면 좋지만 운영 시스템에서 인덱스 구성을 바꾸기는 쉽지 않다. 이럴 때 BETWEEN 조건을 IN-List로 바꿔주면 큰 효과를 얻을 수 있다.
WHERE D IN ('A', 'B', 'C') AND A = '1' AND B = '2' AND C = '3'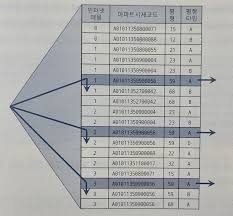
해당 인덱스 구성에서 BETWEEN을 사용했을 때와 IN-List로 바꾸었을 때 스캔하는 양을 생각해보기를 바란다.
해당 그림에서 왼쪽에서 화살표가 3개인 이유는 수직적 탐색이 3번 발생했기 때문이다.
주의할 점
BETWEEN 조건을 IN-List 조건으로 전환할 때 주의할 점은, IN-List 개수가 많지 않아야 된다는 것이다. IN-List 개수가 많으면 수직적 탐색이 많이 발생한다. 그러면 BETWEEN 조건 때문에 리프 블록을 많이 스캔하는 비효율보다 IN-List 개수만큼 브랜치 블록을 반복 탐색하는 비효율이 더 크다. 루트에서 브랜치 블록까지 Depth가 깊을 때 특히 그렇다.
스캔 과정에서 조회되는 레코드들이 서로 멀리 떨어져 있을 때만 유용하다.
부서코드, 직급 순으로 구성한 인덱스에서 "직급 = 과장" 조건을 만족하는 레코드가 서로 멀리 떨어져 있을 때만 BETWEEN 조건을 IN-List로 전환하는 기법이 유용하다.
BETWENE 조건으로 인덱스를 비효율적으로 스캔하더라도 블록 I/O 측면에서는 소량에 그치는 경우가 많다.
리프블록에는 테이블 브록과 달리 매우 많은 레코드가 담기기 때문이다.
게다가 IN-List 개수가 많으면 수직적 탐색 과정에서 이미 많은 블록을 읽게 된다. 데이터 분포나 수직적 탐색 비용을 따져보지도 않고 BETWEEN을 IN-List로 변환하는 실수를 하면 안된다.
