VIEW
복잡한 쿼리문(SELECT)을 미리 작성해두고 재사용 할 수 있도록 해주는
읽기 전용의 가상테이블. 읽기 전용이기때문에 테이블의 삽입, 수정, 삭제 작업에 제약을 걸때 사용할 수 있다. java에서 method와 비슷하다.
MySQL에서 뷰(view)는 다른 테이블이나 다른 뷰에 저장되어 있는 데이터를 보여주는 역할만을 수행
VIEW 특징
- 특정 사용자에게 테이블 전체가 아닌 필요한 필드만을 보여줄 수 있다.
- 복잡한 쿼리를 단순화해서 사용할 수 있다.
- 쿼리를 재사용할 수 있다.
단점
- 한 번 정의된 뷰는 변경할 수 없습니다.
- 삽입, 삭제, 갱신 작업에 많은 제한 사항을 가집니다.
- 자신만의 인덱스를 가질 수 없습니다.
뷰는 원본 테이블과 같은 이름을 가질 수 없다.
비즈니스 단위로 테이블이 필요할때 뷰를 호출해서 보게된다
논리적으로 가상에 존재하는것이므로 호출시 편하게 볼수있다
VIEW 생성
-- CREATE VIEW 뷰이름 AS
-- SELECT ~~
CREATE VIEW JOIN_RESULT AS
SELECT R.room_number AS '방번호', C.name AS '고객이름'
FROM Room R INNER JOIN Custom C
# 별칭을 붙이면 수월하게 사용할수 있다.
ON C.id = R.custom_id;
SELECT * FROM Join_Result
WHERE 방번호 = 1002;VIEW 대체
view가 존재하지 않으면 새로 생성하고, 기존에 존재한다면 대체한다.
CREATE OR REPLACE VIEW 뷰이름 AS
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름
WHERE 조건VIEW 수정
-- ALTER VIEW 뷰이름 AS
-- SELECT ~~
ALTER VIEW Join_Result AS
SELECT R.room_number AS '방번호', C.name AS '고객이름', C.email AS '고객이메일'
FROM Room R INNER JOIN Custom C
ON C.id = R.custom_id;
SELECT * FROM Join_Result;VIEW 삭제
-- DROP VIEW 뷰이름
DROP VIEW Join_Result;시험에 나오는 구문
SHOW TABLES;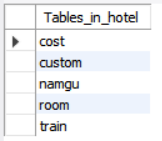
SQL에서 "SHOW TABLES;"는 데이터베이스 내에 존재하는 모든 테이블의 목록을 보여주는 명령문입니다. 이 명령문을 실행하면 현재 선택한 데이터베이스에서 사용 가능한 모든 테이블의 목록을 반환합니다.
예를 들어, MySQL에서 "SHOW TABLES;" 명령문을 실행하면 현재 선택한 데이터베이스 내에 존재하는 모든 테이블의 목록을 보여줍니다.
이 명령문은 보통 데이터베이스의 스키마나 테이블 구조를 파악하는 데 많이 사용됩니다. 데이터베이스에 존재하는 테이블 목록을 확인하려면 이 명령문을 사용하면 됩니다.
SHOW INDEXES FROM Custom;
SQL에서 "SHOW INDEXES FROM table_name;"은 지정한 데이터베이스 테이블의 인덱스 정보를 조회하는 명령문입니다. "table_name" 자리에는 인덱스 정보를 조회하려는 테이블의 이름을 입력하면 됩니다.
예를 들어, "Custom"이라는 테이블에서 인덱스 정보를 조회하려면 다음과 같은 SQL 문을 사용할 수 있습니다.
위의 SQL 문을 실행하면 "Custom" 테이블에 대한 인덱스 정보를 확인할 수 있습니다. 이 명령문을 사용하면 해당 테이블의 인덱스 이름, 인덱스 타입, 칼럼 이름, 중복 여부 등의 정보를 파악할 수 있습니다.
이와 같이 "SHOW INDEXES FROM table_name;" 명령문을 사용하여 데이터베이스 테이블의 인덱스 정보를 조회할 수 있습니다.
SELECT * FROM mysql.user;
SQL에서 "SELECT * FROM mysql.user;"는 MySQL 데이터베이스 내의 "mysql" 데이터베이스에서 "user" 테이블의 모든 데이터를 조회하는 SQL문입니다.
"user" 테이블은 MySQL 데이터베이스에서 사용자 정보를 저장하는 시스템 테이블 중 하나입니다. 이 테이블에는 MySQL 서버에 등록된 사용자의 정보, 권한 및 비밀번호 등이 저장됩니다.
위의 SQL 문을 실행하면 "user" 테이블의 모든 열과 해당 열에 저장된 데이터가 반환됩니다. "*"는 모든 열을 의미하며, "FROM mysql.user"는 "user" 테이블을 선택하고, "mysql" 데이터베이스에서 조회하도록 지정한 것입니다.
이와 같이 "SELECT" 문을 사용하여 MySQL 데이터베이스의 테이블에서 데이터를 조회할 수 있습니다. "mysql" 데이터베이스의 "user" 테이블에서는 사용자 및 권한 정보를 조회할 수 있으므로, 서버 관리 및 보안 등에 유용하게 사용될 수 있습니다.
INDEX
테이블의 검색속도를 향상시켜주는 기능을 담당하는 요소.
인덱스가 적용되어 있는 필드의 경우 해당 필드를 조건으로 검색을 시도할 때 검색 속도가 향상된다.
인덱스가 적용되어 있는 필드를 수정할 경우 인덱스도 함께 변경되어 검색 속도에 영향을 미칠수가 있다.
INDEX 생성
-- CREATE INDEX 인덱스명
-- ON 테이블명 (필드명, ...);
CREATE INDEX saedaesu_index
ON Namgu (세대수); # 오롯이 세대수를 가지고 검색했을때를 이야기함.INDEX 정보보기

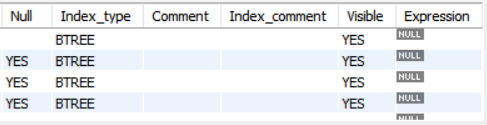
- Table : 테이블의 이름을 표시함.
- Non_unique : 인덱스가 중복된 값을 저장할 수 있으면 1(not unique), 저장할 수 없으면 0을 표시함(unique).
- Key_name : 인덱스의 이름을 표시하며, 인덱스가 해당 테이블의 기본 키라면 PRIMARY로 표시함.
- Seq_in_index : 인덱스에서의 해당 필드의 순서를 표시함.
- Column_name : 해당 필드의 이름을 표시함.
- Collation : 인덱스에서 해당 필드가 정렬되는 방법을 표시함.
- Cardinality : 인덱스에 저장된 유일한 값들의 수를 표시함.
- Sub_part : 인덱스 접두어를 표시함.
- Packed : 키가 압축되는(packed) 방법을 표시함.
- Null : 해당 필드가 NULL을 저장할 수 있으면 YES를 표시하고, 저장할 수 없으면 ''를 표시함.
- Index_type : 인덱스에 사용되는 메소드(method)를 표시함.
- Comment : 해당 필드를 설명하는 것이 아닌 인덱스에 관한 기타 정보를 표시함.
- Index_comment : 인덱스에 관한 모든 기타 정보를 표시함.
-- SHOW INDEX FROM 테이블명 : 해당 필드의 인덱스 다 볼수 있다
SHOW INDEX FROM Namgu;
CREATE INDEX saedaesu_index_2
ON Namgu (세대수, 인구수, 통);
# 아예 인덱스로 설정이 되어있으면 검색속도가 빨라진다.
# 조건절에 적을적에 WHERE ~~ 해서
# 설정한 '순서대로' 적어줘야 인덱스의 검색속도 향상 효과를 볼수있다UNIQUE INDEX 생성
CREATE UNIQUE INDEX saedaesu_unique_index
ON Namgu(세대수);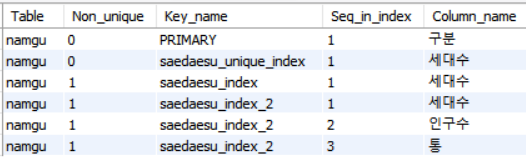
unique로 설정된 레코드들은 Non_unique 0으로 지정된걸 알수 있다.
Group By, Having
남구 데이터 예제에서 면적의 행수를 세고 세대수의 최댓값과 최솟값을 구하면
SELECT count(면적), max(세대수), min(세대수)
FROM Namgu;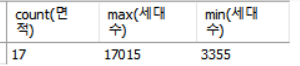
이때, 면적에 따른 분류를 하게 될때 Group By를 사용한다.
SELECT 면적, count(*), max(세대수), min(세대수)
FROM Namgu
GROUP BY 면적;# 면적을 기준으로 그룹화를 시켜서
# 그 그룹내에서 갯수와 최댓값과 최솟값을 구하게된다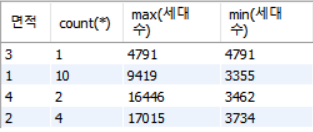
SELECT 면적, count(*), max(세대수), min(세대수)
FROM Namgu
# WHERE max(세대수) >= 5000 # 이거하면 오류뜸.
# 실행되는 순서가 있어서 그룹함수에 조건걸어서 필터처리를 해주고싶다면
# having 이라는 절에 추가해줘야한다!
GROUP BY 면적 # 그룹만들고, 조건걸어서 필터하고, 정렬⭐
HAVING max(세대수) >= 5000 # 그룹 되어있는 애들만 HAVING에서 사용할수있다
ORDER BY 면적; #면적기준으로 정렬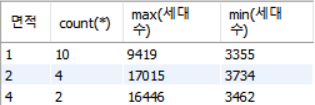
-- Group By 되지 않은 필드는 Having에 사용 불가능
SELECT 면적, count(*), max(세대수), min(세대수)
FROM Namgu
GROUP BY 면적
HAVING 세대수 >= 5000
ORDER BY 면적;
count(*), max(세대수), min(세대수) 의 필드가 group by 된거고
세대수라는 필드는 group by 되지 않았기때문에 사용할수 없다.
웹페이지 DB 구성
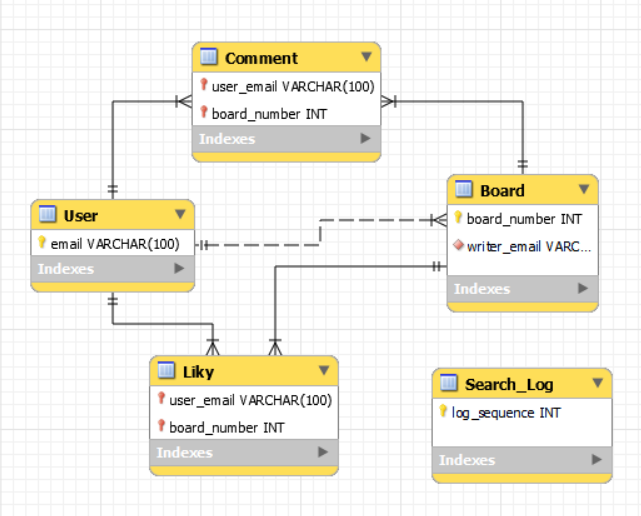
ERD 관계선의 종류
- 실선 : A테이블과 B테이블은 "식별관계", 부모테이블[A 테이블]의 PK가 외래키로써, 자식테이블[B 테이블]의 PK에 포함되는 경우
- 점선 : A테이블과 B테이블은 "비식별관계", 부모테이블[A 테이블]의 PK가 외래키로써, 자식테이블[B 테이블]의 PK가 아닌 일반 속성이 되는 경우
개체가 어떤게 있는지 생각해보기(데이터 관련해서!)
Entity
회원 User, 게시물 Board
회원이 게시물을 작성한다 하는 행위의 결과 = 게시물
회원이 게시물을 작성, 한명의 회원은 여러개의 게시물 작성가능
하나의 게시물에 대해서 한명만 게시물을 작성가능한가? ⭕
회원과 게시물은 1 대 n의 관계
Relation
회원이 게시물을 작성한다 (1 : n)
회원이 게시물을 좋아요누른다 (n : m)
회원이 게시물에 대해서 좋아요를 누르고 댓글을 달수 있다.
게시물에 대해서 좋아요를 누르는건 한명이 여러개의 게시글에 좋아요 가능
하나의 게시물은 여러회원에 대해서 좋아요 눌릴수 있다.
회원이 게시물에 댓글을 단다 (n : m)
한 회원은 한 게시글에 대해서 여러개의 댓글을 달 수 있다.
하나의 게시물은 여러 회원에 대해서 댓글이 달릴수 있다.
Table
검색로그 (pk를 증가하는 정수형태로 지정해주면 된다)
인기검색어, 관련검색어 : 검색결과에 대한 기록, 누적된 값들. 로그데이터
사용자에 대한 기록을 기억하고 저장해둔것. 로그파일
관계가 형성되어있는게 아니라 데이터를 쌓아두는형태로 사용한다
관련검색어는 지금 걸 검색전후에 검색한 것의 기록을 남기는것
로그인할때 쓰여지는것들이 구분자로 쓰여진다
이메일 주소가 로그인시에 쓰이는거니까 유저의 PK를 이메일 주소로 지정
게시물 일반적으로 게시물에서 unique 찾기 힘들다. 찾겠다라고한다면
대부분 존재할수 있는게 작성시간인데 잘 쓰지 않는다.
구분지어주는 임의의 PK를지정, 게시물 번호 형태로 구분을 짓게한다.
페이지에 필요한걸 다 적은다음에 중복되는걸 제거하는방식으로 하는게 좋다
로그인화면에서 필요로하는 데이터
사용자(이메일 주소와 비밀번호)
회원가입화면에서 필요로 하는 데이터
사용자(이메일 주소, 비밀번호, 비밀번호 확인
닉네임 휴대폰번호 주소 상세주소, 개인정보 동의여부)
메인화면에서 필요로 하는 데이터
- 주간 탑3게시글 : 게시물(게시물번호, 게시물 사진, 작성자 프로필사진, 작성자닉네임,작성날짜, 제목, 내용, 조회수, 좋아요수, 댓글수)
- 최신 게시물 : 게시물(게시물번호, 게시물 사진, 작성자 프로필사진, 작성자닉네임,작성날짜, 제목, 내용, 조회수, 좋아요수, 댓글수)
- 인기검색어 : 검색로그(검색어)
검색화면에서 필요로 하는 데이터
-
검색결과 : 게시물(게시물 사진, 작성자 프로필사진, 작성자닉네임,작성날짜, 제목, 내용, 조회수, 좋아요수, 댓글수)
-
관련 검색어 : 검색로그(관련검색어)
상세페이지에서 필요로 하는 데이터
점땡땡땡에 대한 기능 표현위해서 작성자 이메일 게시물에 추가해줌. (본인이 수정 삭제를 해야하기때문에)
1. 게시물 (게시물 제목, 작성자이메일, 작성자프로필사진, 작성자 닉네임, 작성일, 내용, 게시물사진, 좋아요수, 댓글수, [좋아요 리스트, 댓글 리스트])
2. 좋아요리스트 (유저 프로필사진, 유저 닉네임)
3. 댓글리스트 (유저프로필사진, 유저닉네임, 작성시간, 댓글내용)
마이페이지에서 필요로 하는 데이터
- 유저정보 (유저 프로필사진, 닉네임, 이메일)
- 내 게시물(게시물번호, 게시물 사진, 작성자 프로필사진, 작성자닉네임,작성날짜, 제목, 내용, 조회수, 좋아요수, 댓글수)
게시물작성화면에서 필요로하는 데이터
게시물 (제목, 내용 게시물사진)
게시물 수정화면에서 필요로 하는 데이터
게시물 (제목, 내용 게시물사진)
