개요
Why Tanstack Query?
서버/네트워크 상태 관리 라이브러리
 Tanstack Query 소개 내용을 보면 강력한 비동기 상태 관리를 지원한다고 한다.
Tanstack Query 소개 내용을 보면 강력한 비동기 상태 관리를 지원한다고 한다.
선언적이고 항상 최신의 자동화된 쿼리와 뮤테이션을 제공하여 UX와 DX 모두를 향상시킨다고 한다.
Tanner Linsley와 Dominik 이 두 명이 초기 오픈소스 컨트리뷰터로 시작했다.
라이브러리 내 코드 대부분을 리액트와 결합되지 않은 순수 JS 코드로 구현하도록 노력하여 여러 FE 프레임워크를 지원하려고 했다. V2까지는 리액트 쿼리라고 불렀지만 이후 부터는 @tanstack namespace를 사용하고 있다.
타사 라이브러리 비교
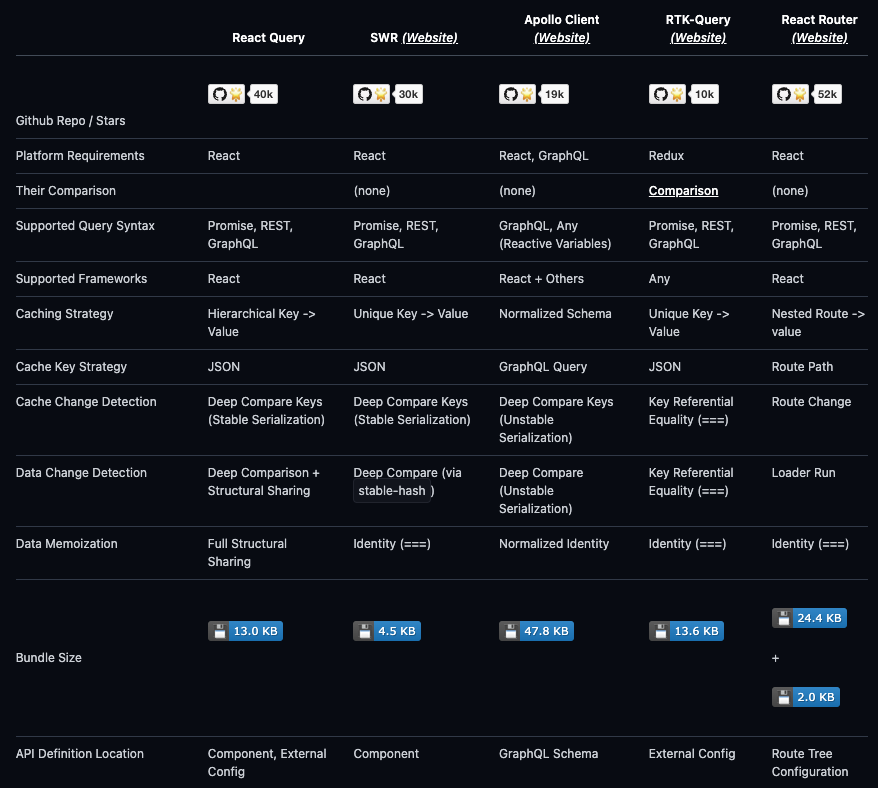 SWR는 Vercel에서 만든 lightweight 서버 상태 라이브러리이고, Apollo Client는 graphQL 기반으로 많이 사용한다. 자세한 것은 해당 공식문서를 통해 비교해보면 좋다.
SWR는 Vercel에서 만든 lightweight 서버 상태 라이브러리이고, Apollo Client는 graphQL 기반으로 많이 사용한다. 자세한 것은 해당 공식문서를 통해 비교해보면 좋다.
Why Tanstack Query?
일반적인 리액트 데이터 fetching 방식을 생각해보면, 서버로부터 받아 올 데이터를 저장할 state 초기화를 하고 이후 useEffect를 이용하여 데이터 fetch 이후 setState한다.
이는 useFetch 같은 커스텀 훅을 통해 공통 추상화가 가능하다.
그리고 Loading, Error도 state로 관리하여 추가 작업을 한다.
Loading을 이용하여 Layout Shift 방지가 가능하고 Error는 Infinite Loading 방지가 가능하다.
하지만 최신 서버 데이터로 동기화 되지 않는 문제가 발생할 수 있다.
데이터 fetch하는 시간 자체는 예측이 불가능하다.
만약 다른 상태 변화로 인해 또 다른 fetch 발생 시 2개의 데이터 fetching network in flight 상태가 된다.
최종적으로 어떤 데이터를 사용해야 할지 모르는 race condition 문제가 발생할 수 있다.
Screen flash. 즉 데이터 깜빡임 문제가 발생할 수 있다.
이를 해결하기 위해 useEffect의 clean up function을 이용할 수 있다.
clean up function은 dep Array에 의해 useEffect가 다시 실행되거나(update) 컴포넌트가 DOM에서 제거될 때(unmount) 실행되는 리액트의 기능이다.
전자의 경우 이전 응답에 대한 값을 가지고 있게 할 수 있다.
ignore 같은 flag를 두고 data fetch 시 ignore이 true이면 early return,
cleanup functin에서는 ignore를 false로 설정할 수 있다.
이런 방식을 활용하면 여러 데이터 fetch network in flight 문제 해결이 가능하다.
마찬가지로 커스텀 훅으로 일반화해서 사용이 가능하다.
참고로 ignore 같은 flag 변수가 아닌 AbortController 또는 useRef를 이용한 flag를 사용해서도 처리가 가능하다.
하지만 아직 Data Deduplication 문제가 발생할 수 있다.
이는 네트워크 중복 요청에 대한 문제이다.
모든 리액트 컴포넌트는 자체적인 state에 대한 instance를 가지고 있고 local로 존재한다.
다른 곳에서도 동일한 데이터를 사용하기 위해서는 refetch가 필요하다.
서로 다른 컴포넌트에서 가져온 데이터가 서버 최신 상태와 동기화 되지 못하는 이슈가 발생할 수 있는 것이다.
이는 Context API를 활용하여 해결할 수 있다.
Props drilling을 피하기 위해 보통 Context API를 사용한다.
여러 URL에 대한 데이터, 로딩, 오류 상태를 저장하고 작은 in-memory cache로 활용하는 것이다.
하지만 Context API는 상태의 일부를 구독할 수 없는 단점이 존재하고 또한 전역 상태 변경 사항이 Context API를 구독하는 여러 컴포넌트에서 불필요한 리렌더링 문제가 발생할 수 있다.
또한 Cache Invalidate도 어렵다.
이로써 서버 상태 관리 라이브러리의 필요성이 대두되는 것이다.
대부분의 기존 상태 관리 라이브러리는 클라이언트 상태 관리에는 적합하지만 비동기 서버 상태 관리에는 적합하지 않다. 서버 상태 관리에 있어서 직면하는 여러 이슈가 발생할 수 있다.
서버 상태 관리에 있어서 직면하는 여러 이슈
- Caching
- Deduping multiple requests for the same data into a single request
- Updating "out of date" data in the background
- Knowing when data is "out of date"
- Reflecting updates to data as quickly as possible
- Performance optimizations like pagination and lazy loading data
- Managing memory and garbage collection of server state
- Memoizing query results with structural sharing
그렇다면 Tanstack Query를 사용하면 어떤 문제들을 해결할 수 있고 기능들을 제공해주는 것일까.
Tanstack Query
- Auto Caching/Refetching
- Automatic Garbage Collection
- Polling Queries
- Dependent Queries
- Parallel Queries
- Prefetching
- Paginated/Cursor Queries
- Load-More/Infinite Scroll Queries
- Fetching on Demand
- Data Selectors
- Mutations API
- Optimistic Update
- Suspense Ready!
- Scroll Recovery
- Offline Support
- Dedicated Devtools
- …
너무나도 많은 유용한 기능들을 제공한다.
그럼 본격적인 기능 사용에 앞서서 핵심적으로 알아야 하는 컨셉들에 대해 살펴보자.
핵심 컨셉
주요 용어/핵심 개념
클라이언트 상태 vs. 서버 상태
클라이언트 상태는 클라이언트에서 독립적으로 관리할 수 있는 상태이다.
웹 브라우저 세션과 관련된 모든 정보, 사용자의 상태 추적 등에 활용할 수 있다.
예를 들어, 언어 선택, 테마 등과 같은 정보가 있다.
서버 상태는 서버에 저장되는 정보이다.
여러 클라이언트에 표시하기 위해서 서버에 저장되어 있는 상태이다.
예를 들어, DB로부터 가져오는 블로그 게시글 데이터가 있다.
Stale Time vs. GC Time
State Time은 기본적으로 0ms이다.
서버 확인 전 데이터의 허용된 오래된 정도를 나타낸다.
데이터가 fresh ~ stale 되기까지의 시간을 의미하며 데이터 refetch할 시기를 결정한다.
시간이 다 지나면 캐시에서 데이터가 삭제되는 것은 아니다. 그건 GC Time에 대한 내용이다.
만약 Infinity로 설정 시 GC Time이 만료되지 않은 한 refetch를 하지 않게 된다.
GC Time은 이전에 Cache Time으로 불렸다.
기본적으로 5분이고 데이터를 캐시에 유지할 시간이다.
시간이 다 지나면 캐시에서 데이터가 삭제된다.
캐시 데이터를 얼마나 오래 보관하고 싶은지에 대한 것이다.
inactive 상태일 때 즉 컴포넌트가 unmount 일 때 GC가 돌면서 캐시에서 데이터가 사라지는 것이다.
데이터가 active 상태이면 GC에서는 제외된다.
데이터가 active 상태라는 것은 observer가 있는 상태를 의미하는데 observer는 곧 살펴보기로 한다.
isLoading/isPending vs. isFetching
isLoading은 isFetching의 부분집합이라고 생각하면 편리하다.
isLoading과 isFetching 모두 비동기 함수 호출이 아직 resolve 되지 않은 상태이다.
isLoading은 이전에 쿼리를 호출한 적이 없는 첫 호출, 즉 캐시된 데이터가 없는 상태를 의미한다.
V5에서는 isPending이라는 상태가 나왔다.
간단히 정리하면 isLoading === isFetching && isPending이다.
isPending은 캐시에 사용 가능한 데이터가 없으며 해당 데이터를 가져오는데 오류가 없었다는 것을 알려줄 뿐이다. 쿼리가 현재 가져오는 중인지는 알려주지 않는다.
따라서 isFetching은 queryFn이 실행된 것을 의미한다.
Query Observer (Observer pattern)
Query Observer는 컴포넌트와 캐시 쿼리 사이의 접착제 역할을 한다.
컴포넌트가 마운트될 때마다 각 호출에 대한 옵저버를 생성하게 되는데 이 옵저버는 특정 쿼리 키를 감시한다.
쿼리 키에 대한 값이 변경되면 observer에게 notify하여 컴포넌트를 다시 렌더링할 수 있으므로 UI가 캐시의 값과 동기화 상태를 유지할 수 있게 된다.
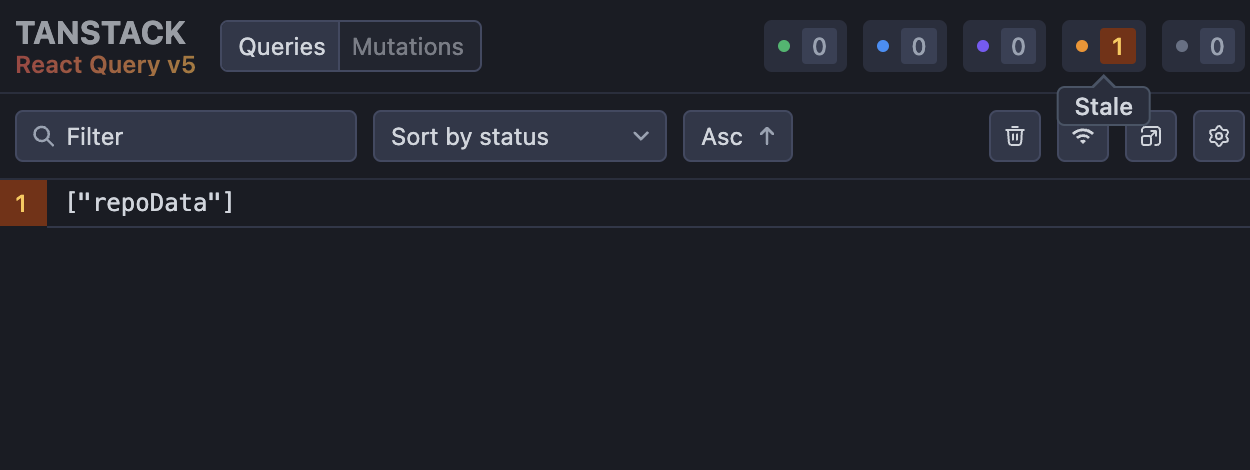
useQuery 라는 훅의 return 값으로 data 타입을 보면 undefined가 뜨는 것을 볼 수 있다.
이유는 우리가 data를 fetch 하는 동안 캐시가 비어있을 수 있기 때문이다.
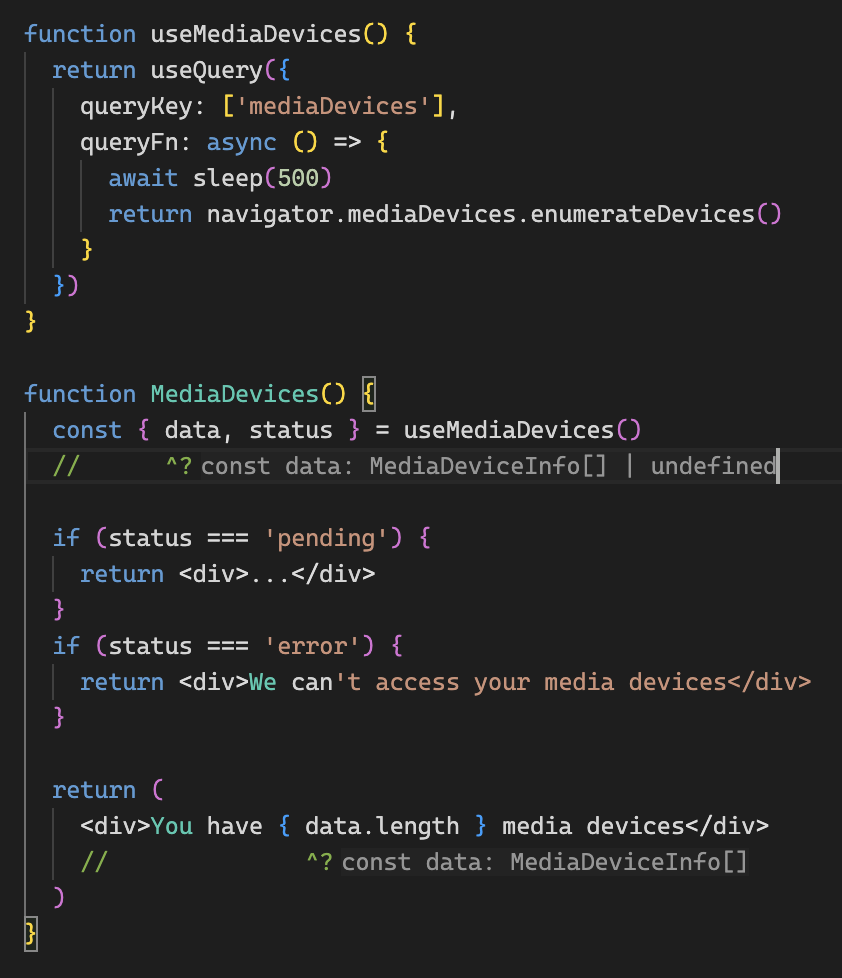
Queries
state는 pending, success, error가 있다.
fetchState는 fetching, paused, idle이 있다.
QueryCache를 구독하고 캐시에서 관심있는 데이터가 변경될 때마다 리렌더링이 일어난다.
queryKey는 QueryCache에서 Map의 key로 사용되므로 반드시 globally unique해야한다.
queryFn은 캐시하려는 데이터로 resolve 되는 프로미스를 반환해야 한다.
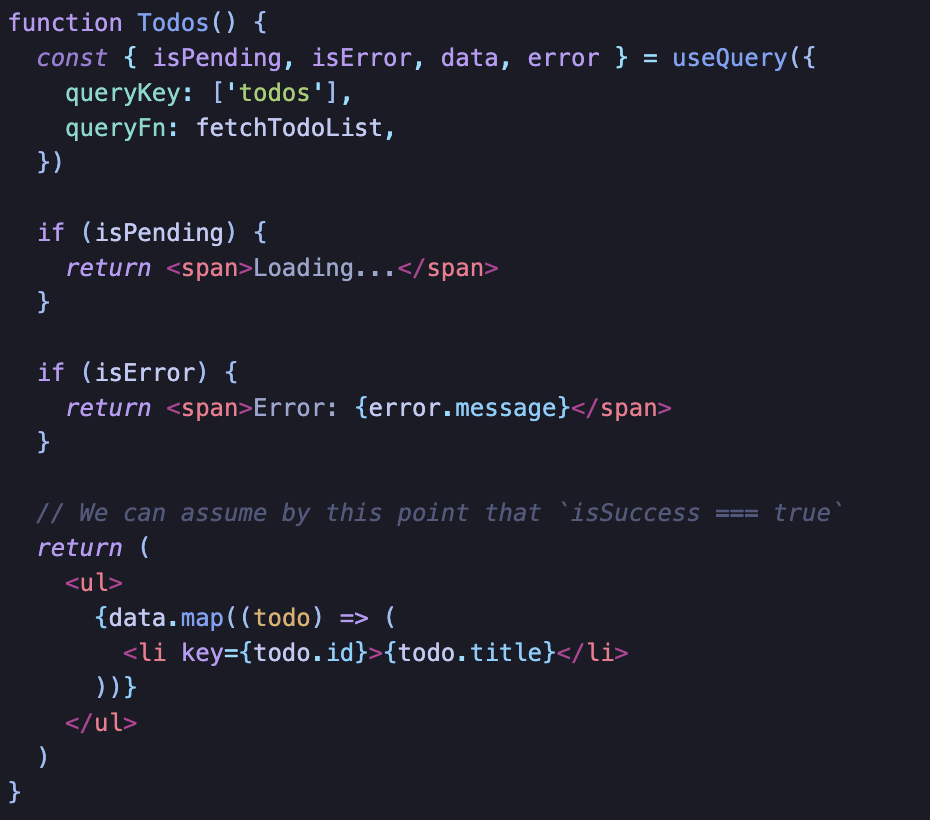
Mutations
state는 idle, pending, success, error가 있다.
캐시 데이터가 필요 없어서 fetching, loading, stale time은 의미가 없게 된다.
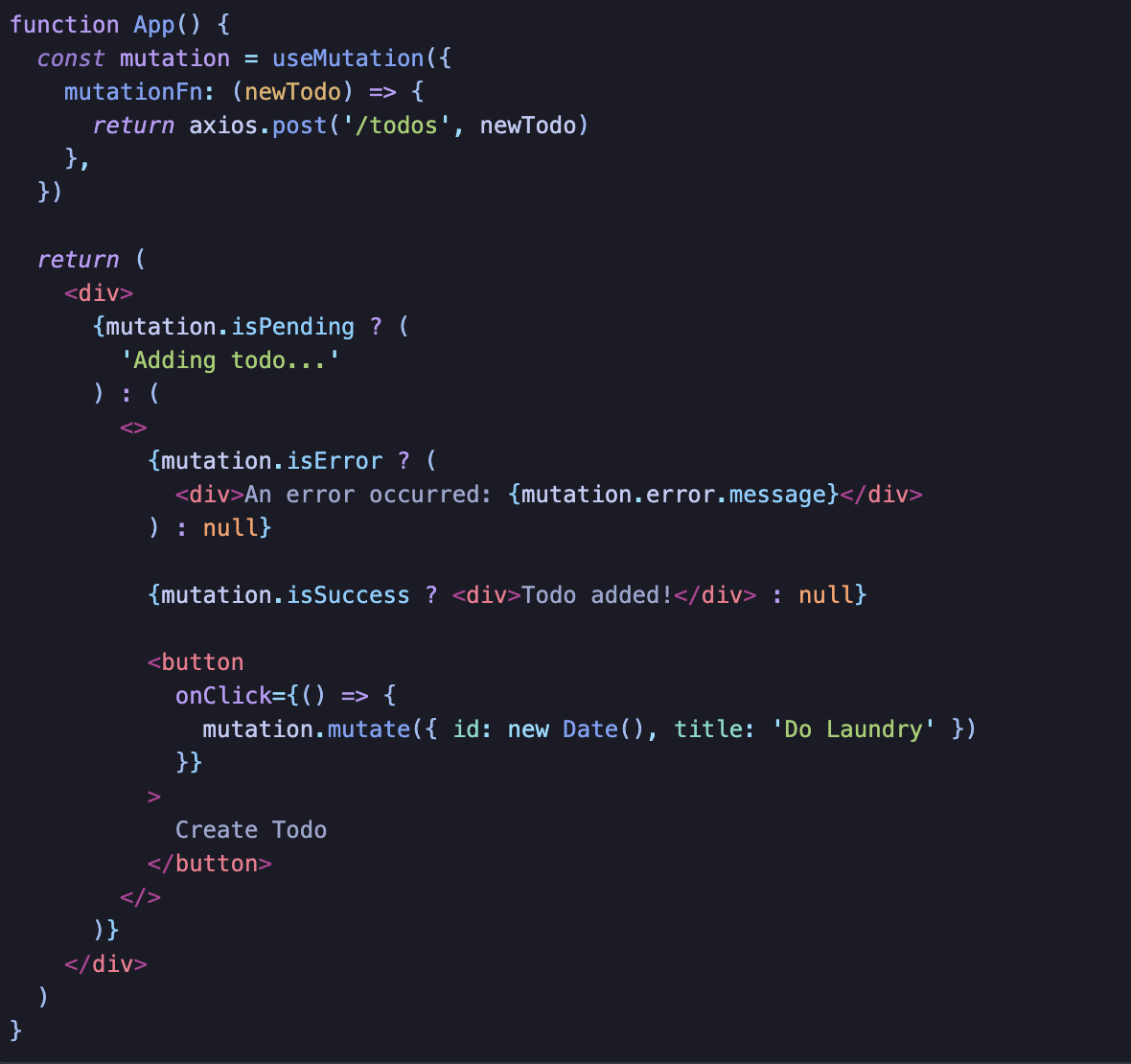
Query Invalidation
Mutation 이후 클라이언트와 서버 동기화가 이뤄지도록 하는 것이다.
Query를 stale 상태로 만들고 해당 Query가 active state 이면 refetch trigger가 발생한다.
Query Key는 쿼리 매칭 패턴으로 순서가 매우 중요하다.
그래서 Query dep이 배열로 되어 있는 것이다.
데이터 업데이트 방식
Invalidate Queries
쿼리를 invalidate하면 클라이언트 데이터를 서버 데이터와 동기화하기 위해 서버에 재요청한다.
페이지 새로고침 없이 업데이트된 데이터를 바로 볼 수 있다.
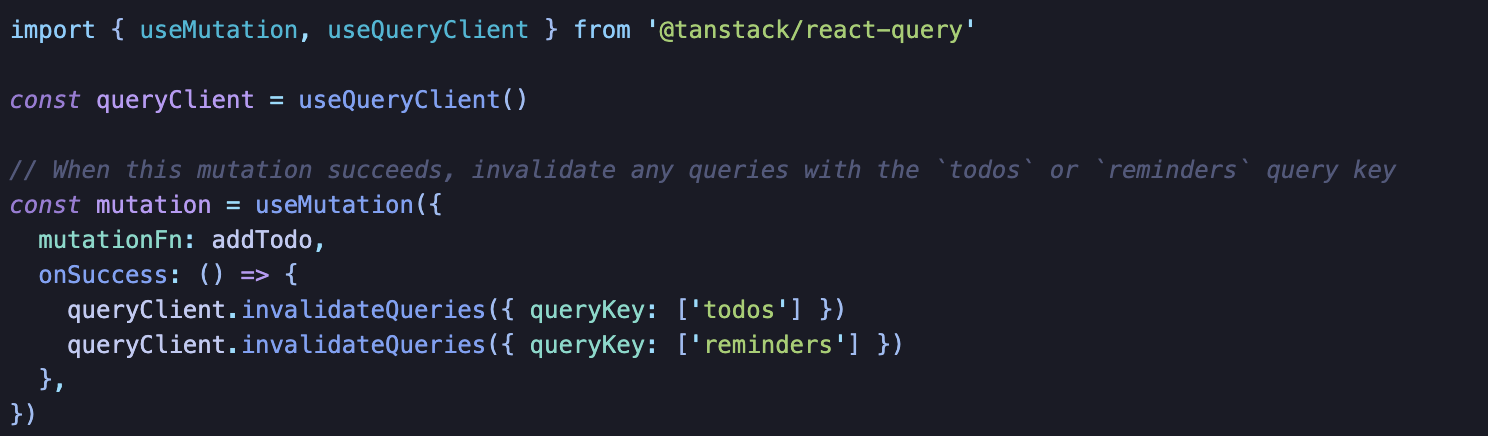
Mutation 이후 받은 데이터로 캐시 업데이트
queryClient.setQueryData로 수동으로 캐시 데이터를 업데이트할 수 있다.
mutation 이후 서버로부터 받은 데이터를 가지고 쿼리 캐시를 업데이트 하는 것이다.
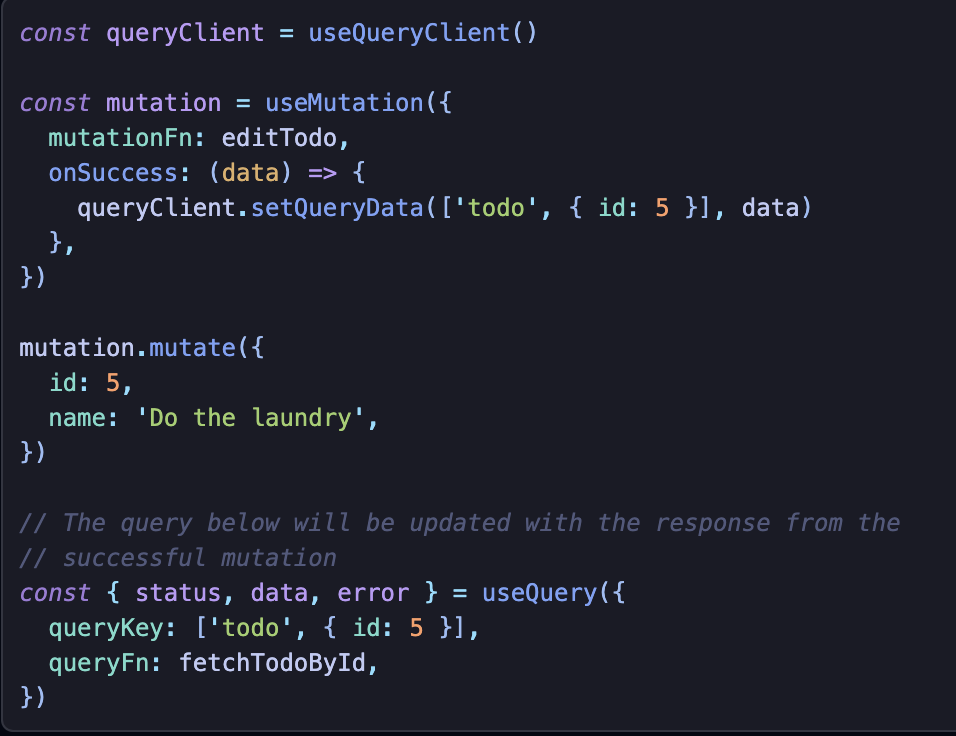
낙관적 업데이트
UI 접근 방식과 Cache 접근 방식이 있다.
UI 접근 방식은 mutate state로 isPending을 이용한다.
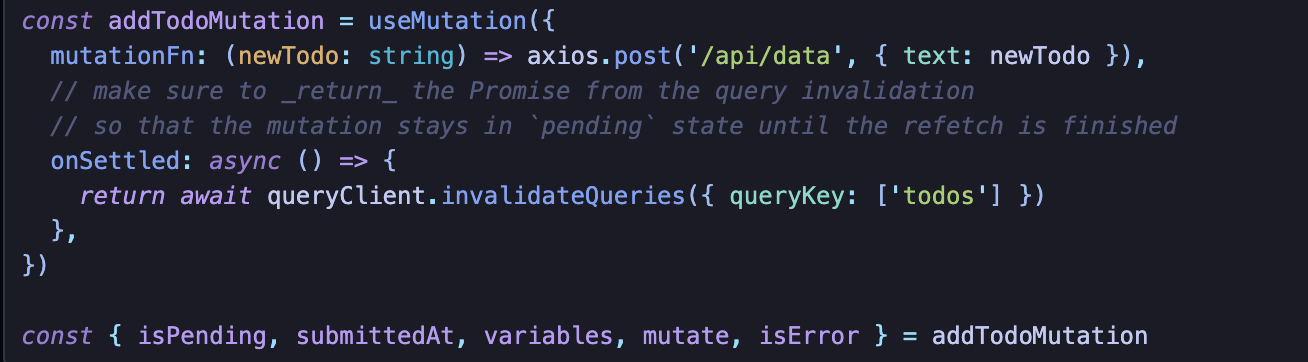

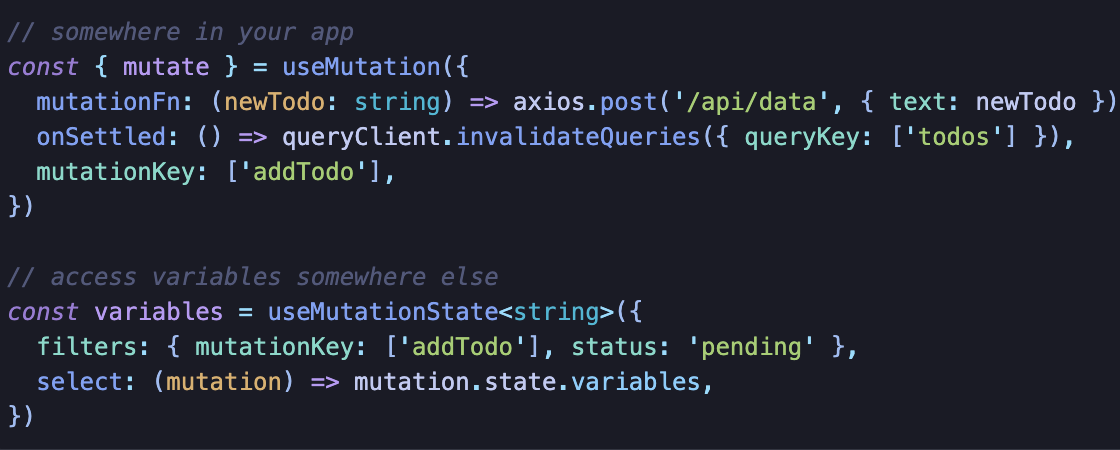
Cache 접근 방식은 onMutate/onSuccess/onError/onSettled와 같은 콜백을 이용하는 것이다.
서버 호출이 잘 되었을 것이라 가정하고 낙관적으로 업데이트하고, 잘 안되었으면 다시 rollback하는 것이다.
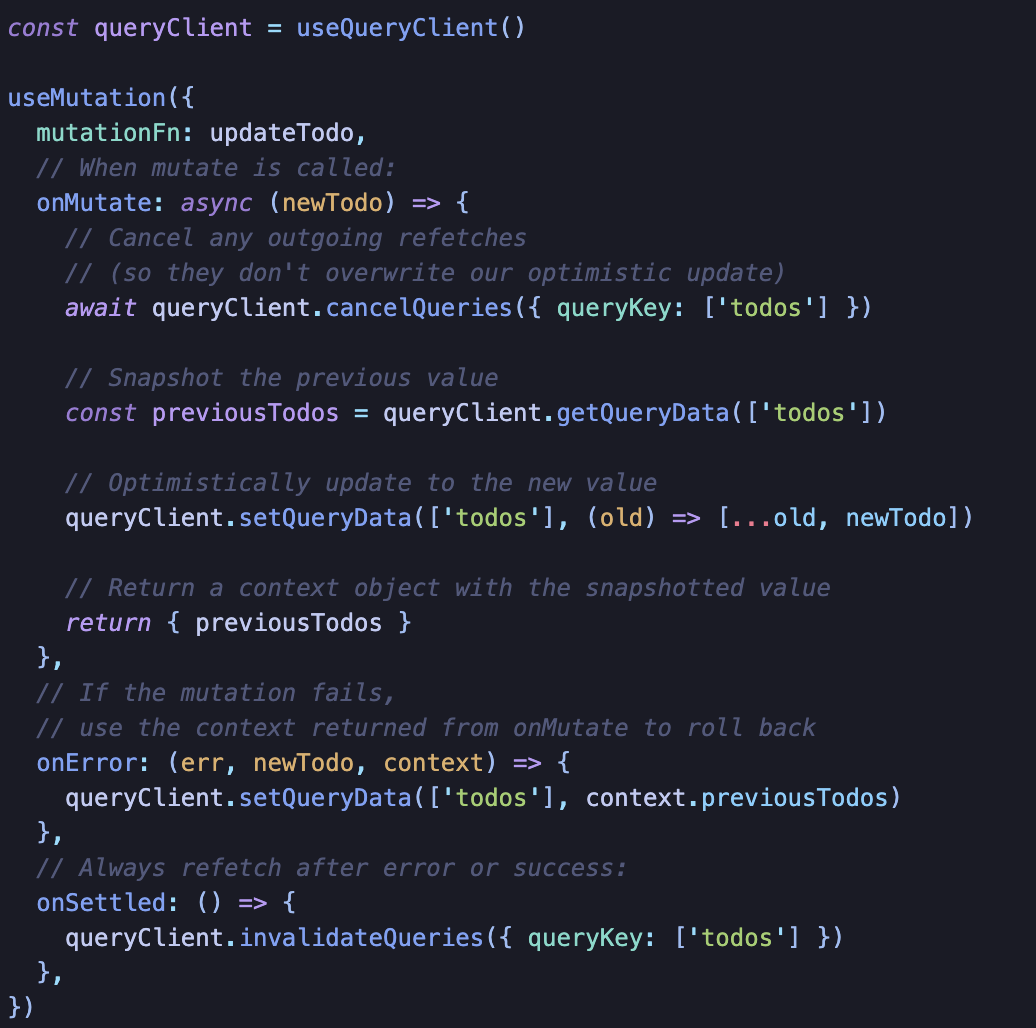
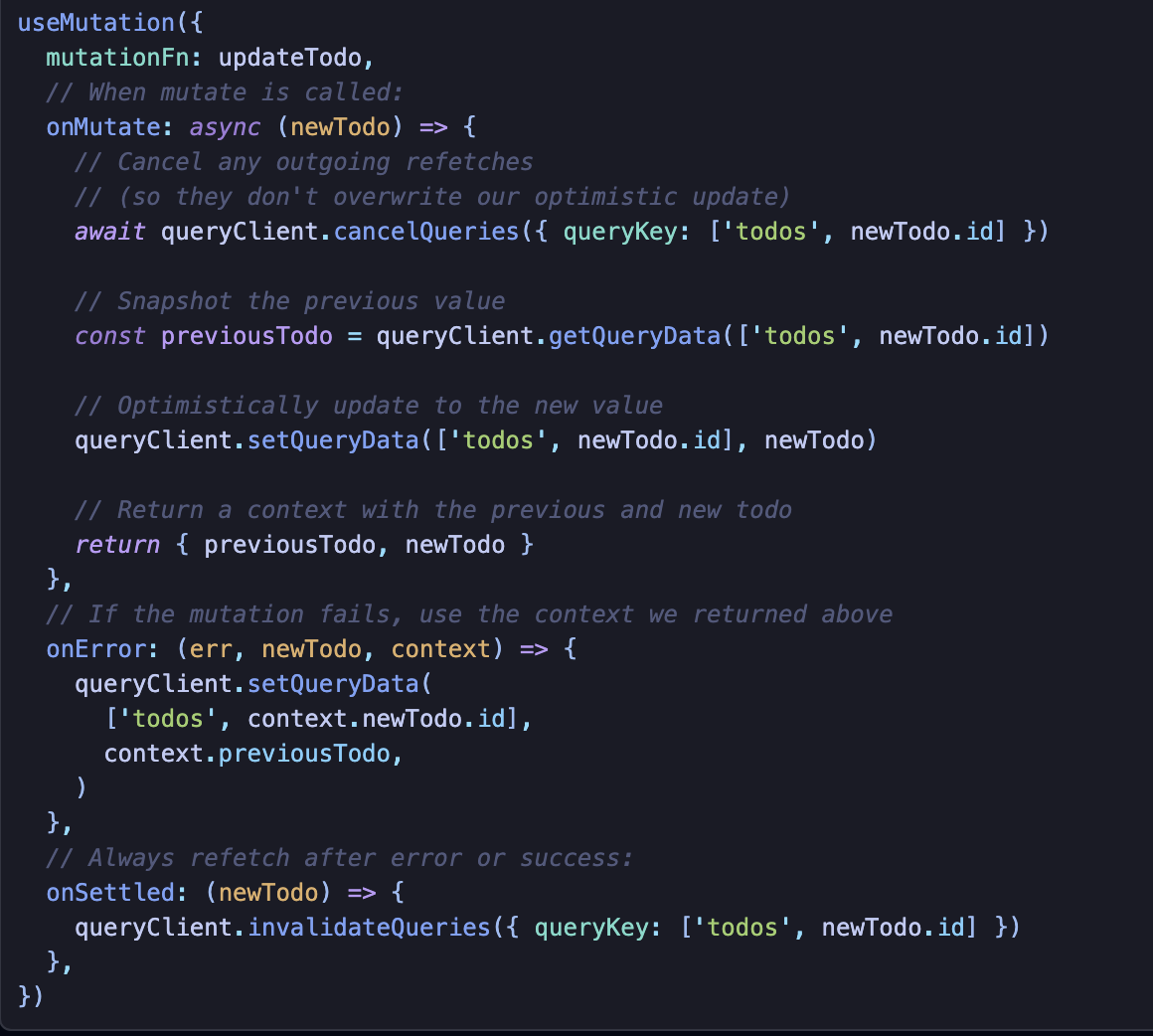
개인적으로 유튜브 모바일 버전을 사용하였을 때 좋아요 기능을 보면 로그인이 되지 않아도 눌러지는 것처럼 보이는데 낙관적 업데이트의 예시로 볼 수도 있을 것 같다.
실제 데모 앱
기본 설정
QueryClient는 Query Cache를 포함하고 관리한다. JS의 Map 자료구조로 구현되어 있으며 절대 변경되지 않는 정적 객체이다. Query Client를 생성해서 주입할 때 Next.js에서는 다르게 처리해야하는 부분이 있는데 이는 이후 다른 아티클에서 다루기로 한다.
QueryClientProvider는 Context API로 구현되어 있어서 상태 관리가 아닌 의존성 주입으로만 사용한다.

To-Do List Demo App
useQuery/useMutation/Optimistic Update에 대한 예시를 활용한 직접 만든 간단한 데모 앱 예시를 준비했다.
브랜치 구성을 통해 tanstack query가 있을 때/없을 때 비교할 수 있고,
낙관적 업데이트도 UI 접근 방식과 캐시 접근 방식을 활용하여 구성했다.
정리&마무리
Query dependency Array
- queryFn에 사용되는 모든 변수들을 모두 queryKey 배열에 넣어야 한다.
QueryKey, MutationKey Unique
- JS Map 자료구조 특성상 key들은 Globally Unique 해야 한다.
- V4 부터는 모든 키는 배열이어야 한다.
- 이름을 어떻게 잘 짓는 것이 좋을지도 고민이 필요한 부분이다.
Invalidate Queries
- QueryKey 지정 시 해당 키 모두 포함하는 부분 매칭 패턴으로 이뤄지고 순서가 중요하다.
Q&A
그동안 사내/외 세미나를 거치면서 많은 Q&A 데이터베이스가 쌓였다.
해당 데이터베이스에 대한 상세한 내용은 구글 슬라이드 내용을 참고하면 좋다.
또한 슬라이드 하단에 부가 설명으로 여러 생각들과 내용들을 적었으니 꼭 같이 확인해보면 좋다.
구글 슬라이드에 추가적인 내용들이 좀 더 있습니다.
구글 슬라이드에 밑줄 표시가 된 부분은 레퍼런스 링크 사이트로 연결이 되고,
또 슬라이드 하단에 첨언 같은 의견, 그리고 Q&A 하단에는 여러 생각들이 적혀있으니 참고하시면 좋을 것 같습니다.
About Tanstack Query - 구글 슬라이드
About Tanstack Query - 유튜브
Demo 앱 - 깃헙 소스코드
