제네릭(Generic), 람다식(Lambda Expressions), 컬렉션 프레임워크(collection framework) - 0829
📚 WIL(what i learned)-today

제네릭(Generic)
람다식(Lambda Expressions)
- 람다는 자바8부터 함수적 프로그래밍을 위해 지원됨.
- 람다 계산법에서 사용된 식을 프로그래밍 언어에 접목함.
- 익명함수(anonymous function)을 생성하기 위한 식
- 람다 계산법에서 사용된 식을 프로그래밍 언어에 접목함.
- 람다식을 사용하면 코드가 매우 간결해짐.
- 람다식으로 대용량데이터(컬렉션 요소)를 필터링 또는 매핑해 쉽게 집계할 수 있음
- bigData에서 사용
- 자바에서 람다식을 인터페이스의 익명 구현 객체로 취급함.
람다식 -> 매개변수를 갖고 있는 코드 블록 -> 익명 구현 객체의 과정
- 어떤 인터페이스를 구현할지는 대입되는 인터페이스에 달려 있음.
람다식(Lambda Expressions) 문법
-
람다식 추상메소드 사용시,
@FunctionalInterfaceannotation 표시 해야함. -
매개 타입은 런타임시에 대입값 따라 자동 인식함.(생략 가능)
-
하나의 매개변수만 있을 경우에는
( )생략 가능 -
하나의 실행문만 있다면
{ }생략 가능 -
매개변수 없다면
( )생략 불가// lambda 방법1 fi = () -> { String str = "method call"; System.out.println(str); }; fi.method(); // lambda 방법2 fi = () -> {System.out.println("method call2");}; fi.method(); // lambda 방법3 fi = () -> System.out.println(); fi.method();```
-
{ }에 return 문만 있을 경우,{ }생략 가능// lambda 방법1 fi = (x) -> { int result = x*5; System.out.println(result); }; fi.method(5); // lambda 방법2 fi = (x) -> {System.out.println(x*5);}; fi.method(5); // lambda 방법3 //추상메소드의 파라메터 갯수가 1개이면 ()괄호 제거 가능함. fi = x -> System.out.println(x*5); fi.method(5);```
-
추상메소드의 body가 return 키워드를 포함하면,
return 키워드와{ }를 제거 가능함.//main MyFuntionalInterface fi; // fi = (x,y) -> { int result = x+y; return result; }; System.out.println(fi.method(5, 2)); // fi = (x,y) -> {return x+y;}; System.out.println(fi.method(5, 2)); // fi = (x,y) -> x+y; System.out.println(fi.method(5, 2)); // fi = (x,y) -> sum(x,y); System.out.println(fi.method(5, 2)); //sum public static int sum(int x, int y) {return (x+y);}
컬렉션 프레임워크(collection framework)
-
배열(array)은 대량의 데이터를 변수로 선언하는 프로그래밍 방식임.
-
배열(array)의 단점은,
- 메모리를 비효율적으로 사용함.
- 저장할 수 있는 객체 수가 배열을 생성할 때 결정됨.
-> 불특정 다수의 객체를 저장하기에는 문제가 있음.
- 저장할 수 있는 객체 수가 배열을 생성할 때 결정됨.
- 배열 원소를
추가삭제조회수정하는데 시간이 많이 소요됨.
- 객체를 삭제하면, 해당 index가 null이됨.
-> 객체를 저장하려면 forloop를 돌려서 어느 index가 비어있는지 확인해야함.
--> 배열의 단점을 보완하는 방법이 등장함.(컬렉션 프레임워크)
- 메모리를 비효율적으로 사용함.
-
컬렉션 프레임워크(collection framework)는 java.util pkg(패키지)에 포함됨.
-
인터페이스를 사용하여 정형화된 방법으로 다양한 컬렉션 클래스를 사용할 수 있음
컬렉션이란?
-
사전적 의미로는 객체를 수집하여 저장하는 것을 의미함.
-
framework는 라이브러리;고도의 여러가지 기능이 있는 라이브러리
-
spring famework(jsp library)
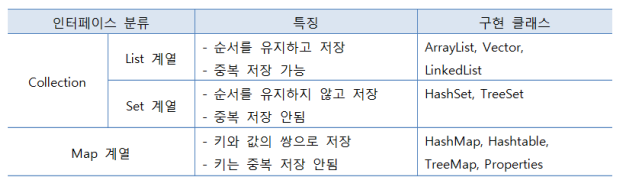
컬렉션 프레임워크의 주요 인터페이스
컬렉션 프레임워크에는 주요 인터페이스 List Set Map이 있음
List에는 ArrayList Vector LinkedList 클래스가 있음
Set에는 HashSet TreeSet 클래스가 있음
Map은 컬렉션 인터페이스에 포함되지 않음. HashMap Hashtable TreeMap Properties 클래스가 있음
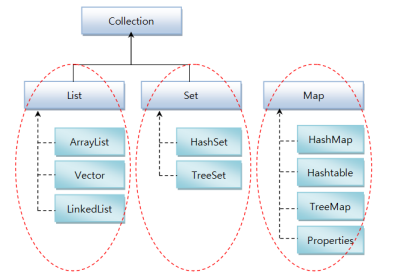
List data type 특징
-
List의 구현 클래스는
ArrayListVectorLinkedList -
원소를 추가할 때, 기본적으로 맨 마지막 원소 다음에 추가함.
-
원소를 삭제하면, 해당 원소의 자리에 다음자리의 원소가 앞으로 당겨짐.(중간에 비어있는 자리가 없음.)
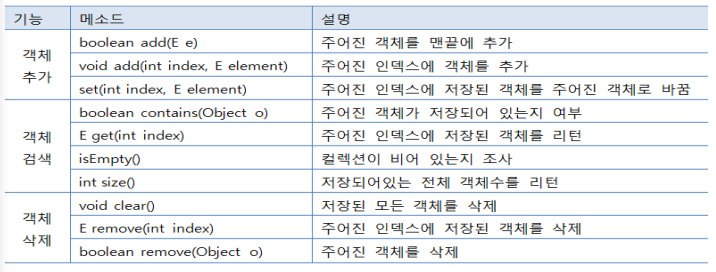
List 컬렉션의 주요 메소드 정리
ArrayList class
리스트.hasNext()로 리스트 출력
- 배열에서 읽어올 때, 메모리에 요소를 읽음과 동시에 정리함.
- null 값 없이 출력 가능함.
- 배열에 읽어올 요소가 있으면(배열이 null이 아니면) true, 없으면 false를 리턴함.
// 스케너로 name에 이름들을 입력 받는 코드
// 이름 배열 출력
Iterator<String> it = a.iterator();
while (it.hasNext()) {
String name = it.next();
System.out.println("Iterator 사용 이름 : " + name);
}Collections method
max()최대값,min()최소값binarySearch()원하는 원소의 찾아, 해당 원소의 index 리턴함.- binary search 알고리즘을 사용하여 검색함, 속도가 매우 빠름.
sort()오름차순,reverse()리스트 순서 역행disjoint()두개의 리스트를 비교해 중복되지 않으면 true, 중복되면 false
Integer[] numbers = { 1123, 1412, 23, 44, 512132 };
List<Integer> list = Arrays.asList(numbers);
System.out.println("Collections.max(list) : " + Collections.max(list));
System.out.println("Collections.min(list) : " + Collections.min(list));
System.out.println("Collections.binarySearch(list) : " + Collections.binarySearch(list, 44));
Collections.sort(list); // 오름차순
System.out.println("오름차순 : "+list);
Collections.reverse(list); // 리스트 역행
System.out.println("리스트 역행 : "+list);
Integer[] numbers1 = { 1123, 1412, 23, 44, 512132 };
List<Integer> list1 = Arrays.asList(numbers1);
Integer[] numbers2 = { 123, 142, 3, 4, 5132 };
List<Integer> list2 = Arrays.asList(numbers2);
// 두 리스트의 중복확인
System.out.println(Collections.disjoint(list, list1)); // 중복 있음, false
System.out.println(Collections.disjoint(list1, list2)); // 중복 없음, trueVector class
Vector는 스레드 동기화가 특징임- 복수의 스레드가 동시에
Vector에 접근해 객제를추가,삭제하더라도 스레드는 안전함.
- 복수의 스레드가 동시에
- :
Vector<E>: E는 Element의 데이터 타입을 의미함.
// int[] v와 같은 표현
Vector<Integer> v = new Vector<Integer>();
v.add(5); // 마지막 원소 다음에 집어 넣음.
v.add(4);
v.add(-1);
for (int i = 0; i < v.size(); i++) {
int n = v.get(i); // v.get(i) == v[i]
System.out.println(n);
}